用SSE做向量内积
SSE是Streaming SIMD Extensions的缩写,SIMD是Single Instruction Multiple Data的缩写,即对多条数据并行执行相同的操作,以提高CPU的性能。
从SSE4.1开始支持向量的内积:__m128 _mm_dp_ps( __m128 a,__m128 b,const int mask)。更老的版本需要综合运用多条指令才可以办到。_m128表示128位寄存器,可以存储4个单精度浮点数,2个双精度浮点数,在SSE指令集中ps代表单精度接口,pd代表双精度接口。dp是dot production的意思。
如何查看自己的机器是否支持SSE4.1 ?
$ cat /proc/cpuinfo | grep sse
如果你能看到“sse4_1”或更高的版本就可以了。
不多解释,直接上代码。
#include <smmintrin.h> //SSE
#include <iostream>
#include <ctime>
float inner_product(const float* x, const float* y, const long & len){
float prod = 0.0f;
long i;
for (i=0;i<len;i++){
prod+=x[i]*y[i];
}
return prod;
}
float dot_product(const float* x, const float* y, const long & len){
float prod = 0.0f;
const int mask = 0xff; //把每一位都设为1。详见https://msdn.microsoft.com/en-us/library/bb514054(v=vs.120).aspx
__m128 X, Y;
float tmp;
long i;
for (i=0;i<len;i+=4){
X=_mm_loadu_ps(x+i); //_mm_loadu_ps把float转为__m128
Y=_mm_loadu_ps(y+i);
_mm_storeu_ps(&tmp,_mm_dp_ps(X,Y,mask));//_mm_storeu_ps把__m128转为float。_mm_dp_ps计算向量内积(向量的长度不能超过4),在https://software.intel.com/sites/default/files/m/8/b/8/D9156103.pdf第3页最下方对_mm_dp_ps有说明
prod += tmp;
}
return prod;
}
int main(){
const int len1 = 10;
float arr[len1]={2.0f,5.0f,3.0f,1.0f,7.0f,9.0f,4.0f,3.0f,7.0f,5.0f};
float brr[len1]={9.0f,0.0f,3.0f,5.0f,3.0f,7.0f,8.0f,2.0f,6.0f,1.0f};
std::cout<<"蛮力计算内积 "<<inner_product(arr,brr,len1)<<std::endl;
std::cout<<"使用SSE计算内积 "<<dot_product(arr,brr,len1)<<std::endl;
const int len2 = 1000000;
float *crr=new float[len2];
float *drr=new float[len2];
for (int i=0;i<len2;i++){
int value=i%10;
crr[i]=value;
drr[i]=value;
}
float prod;
clock_t begin;
clock_t end;
begin=clock();
prod=inner_product(crr,drr,len2);
end=clock();
std::cout<<"蛮力计算内积 "<<prod<<"\t用时"<<(double)(end-begin)/CLOCKS_PER_SEC<<"秒"<<std::endl;
begin=clock();
prod=dot_product(crr,drr,len2);
end=clock();
std::cout<<"使用SSE计算内积 "<<prod<<"\t用时"<<(double)(end-begin)/CLOCKS_PER_SEC<<"秒"<<std::endl;
}
//g++ -m32 -msse4.1 dp.cpp -o dp
python numpy中的向量内积调用了C语言并行库(具体是什么并行计算库我不知道),看一下numpy.dot()性能如何。
#coding=utf-8
__author__='orisun'
import numpy as np
import time
LEN=1000000
arr=[]
brr=[]
for i in xrange(LEN):
value=i%10
arr.append(value)
brr.append(value)
array1=np.array(arr)
array2=np.array(brr)
begin=time.time()
prod=0.0
for i in xrange(LEN):
prod+=arr[i]*brr[i]
end=time.time()
print "蛮力计算内积 %.2e\t\t用时%f秒" % (prod,end-begin)
begin=time.time()
prod=np.dot(array1,array2)
end=time.time()
print "使用numpy计算内积 %.2e\t用时%f秒" % (prod,end-begin)
Go语言以C为原型,我们来领略下Go的威力。
package main
import (
"fmt"
"time"
)
func InnerProduct(x []float32, y []float32) float32{
var rect float32=0
for i:=0;i<len(x);i++{
rect+=x[i]*y[i]
}
return rect
}
func main() {
const len2 int=1000000
crr:=[]float32{}
drr:=[]float32{}
for i:=0;i<len2;i++{
value:=float32(i%10)
crr=append(crr,value)
drr=append(drr,value)
}
begin:=time.Now().UnixNano()
prod:=InnerProduct(crr,drr)
end:=time.Now().UnixNano()
fmt.Printf("蛮力计算内积 %.0f\t\t用时%f秒\n",prod,float32(end-begin)/1e9)
}
结果
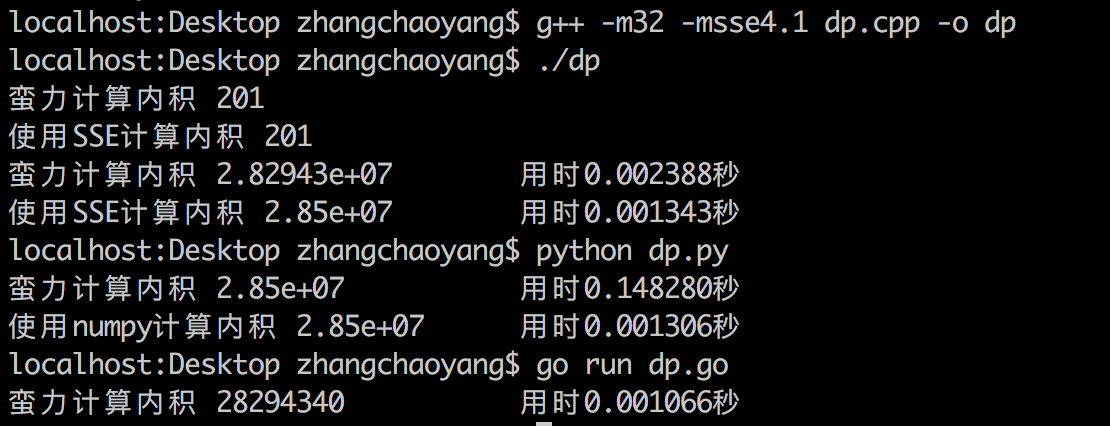
结论:
- 用SSE计算向量内积比用蛮力计算明显要快,但快不到4倍(4倍应该是极限值),计算量越大SSE的优势越明显。
- 用蛮力计算向量内积,python的性能远不如C++,C++比python快了50多倍。但C++的float运算损失了0.7%的精度,python里的小数都是双精度,没有损失精度。
- Go秒杀C++,Go的蛮力法比C++的并行法还要快!
- numpy.dot()比用SSE的_mm_dp_ps还在快一点。猜测:如果numpy.dot()底层也是用的SSE,那它显然不是直接调的_mm_dp_ps,_mm_dp_ps对简单的指令进行了封装并且引入了mask参数自然会慢一些。
参考
https://msdn.microsoft.com/en-us/library/bb514054(v=vs.120).aspx
https://software.intel.com/sites/default/files/m/8/b/8/D9156103.pdf
https://software.intel.com/sites/landingpage/IntrinsicsGuide/#techs=SSE4_1
本文来自博客园,作者:张朝阳讲go语言,转载请注明原文链接:https://www.cnblogs.com/zhangchaoyang/articles/8284543.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号