


【机器学习】解决数据不平衡问题
在机器学习的实践中,我们通常会遇到实际数据中正负样本比例不平衡的情况,也叫数据倾斜。对于数据倾斜的情况,如果选取的算法不合适,或者评价指标不合适,那么对于实际应用线上时效果往往会不尽人意,所以如何解决数据不平衡问题是实际生产中非常常见且重要的问题。
什么是类别不平衡问题
我们拿到一份数据时,如果是二分类问题,通常会判断一下正负样本的比例,在机器学习中,通常会遇到正负样本极不均衡的情况,如垃圾邮件的分类等;在目标检测SSD中,也经常遇到数据不平衡的情况,检测器需要在每张图像中评价一万个到十万个候选位置,然而其中只有很少的点真的含有目标物体。这就导致了训练效率低下和简单的负面样本引发整个模型表现下降的问题。
如何解决不平衡问题
1. 从数据角度
-
主动获取:获取更多的少量样本数据
针对少量样本数据,可以尽可能去扩大这些少量样本的数据集,或者尽可能去增加他们特有的特征来丰富数据的多样性。譬如,如果是一个情感分析项目,在分析数据比例时发现负样本(消极情感)的样本数量较少,那么我们可以尽可能在网站中搜集更多的负样本数量。
-
算法采样:上采样、下采样、生成合成数据
-
ADASYN采样方法:
ADASYN为样本较少的类生成合成数据,其生成的数据与更容易学习的样本相比,更难学习。基本思想是根据学习难度的不同,对不同的少数类的样本使用加权分布。其中,更难学习的少数类的样本比那些更容易学习的少数类的样本要产生更多的合成数据。因此,ADASYN方法通过以下两种方式改善了数据分布的学习:(1)减少由于类别不平衡带来的偏差;(2)自适应地将分类决策边界转移到困难的例子。
-
SMOTE采样方法:
从少数类创建新的合成点,以增加其基数。但是SMOTE算法也有一定的局限性。具体有两项,一是在近邻选择时,存在一定的盲目性。在算法执行过程中,需要确定K值,即选择几个近邻样本,这个需要根据具体的实验数据和实验人自己解决。二是该算法无法克服非平衡数据集的数据分布问题,容易产生分布边缘化的问题。由于负类样本的分布决定了其可选择的近邻,如果一个负类样本处在负类样本的边缘,则由此负类样本和近邻样本产生的样本也会处在边缘,从而无法确定正负类的分类边界。下图是以前做的一个项目应用个各种采样方法做数据增强的情况。(效果不明显,因为原始数据的分布重合太明显,可视化不容易显示出效果)
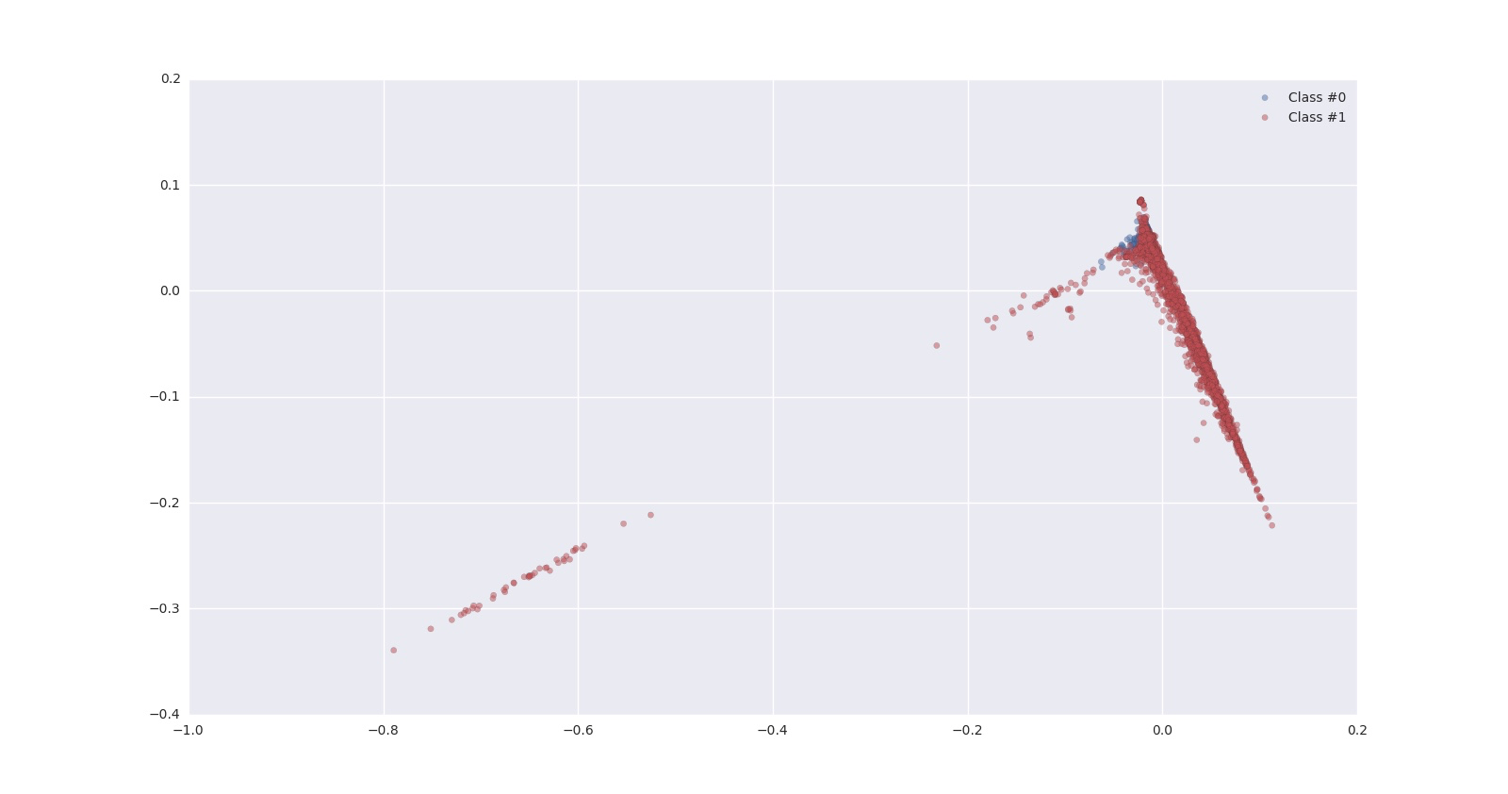
原始数据
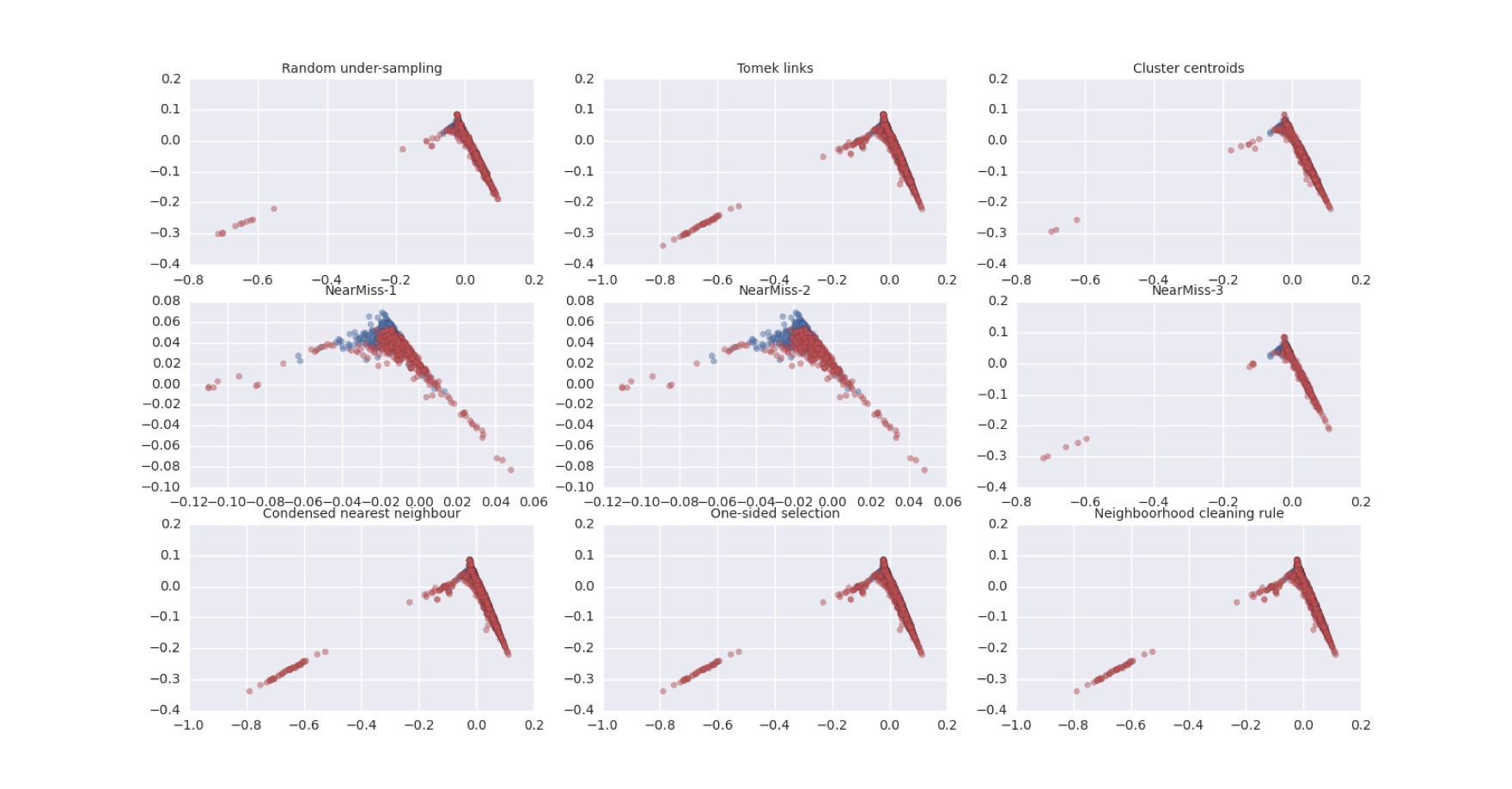
下采样结果
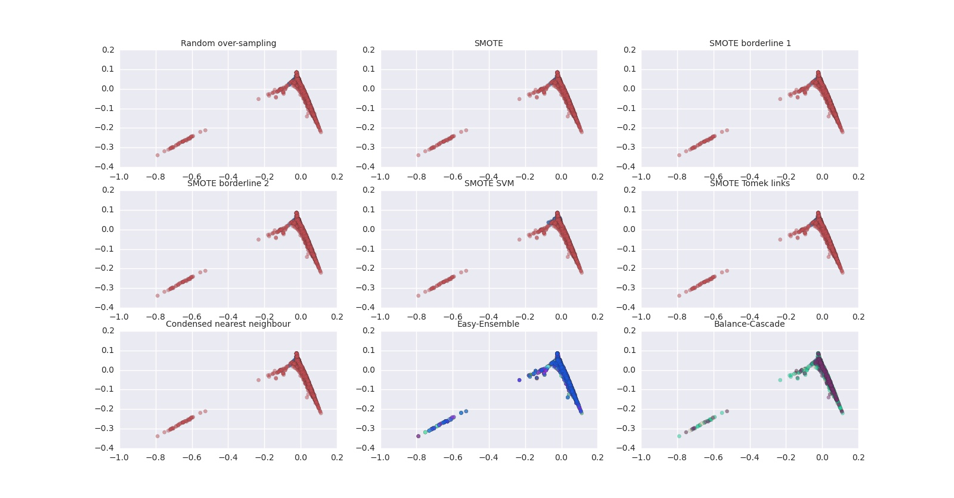
上采样结果
-
数据增强:加噪音增强模型鲁棒性、对不同性质的数据也可以做不同的augmentation
-
改变权重:设定惩罚因子,如libsvm等算法里设置的正负样本的权重项等。惩罚多样本类别,其实还可以加权少样本类别
注意:在选择采样法事需要注意一个问题,如果你的实际数据是数据不平衡的,在训练模型时发现效果不好,于是采取了采样法平衡的数据的比例再来进行训练,然后去测试数据上预测,这个时候算法的效果是否会有偏差呢?此时你的训练样本的分布与测试样本的分布已经发生了改变,这样做反而会产生不好的效果。在实际情况中,我们尽可能的需要保持训练和测试的样本的概率分布是一致的,如果测试样本的分布是不平衡的,那么训练样本尽可能与测试样本的分布保持一致,哪怕拿到手的是已经清洗和做过预处理后的平衡的数据。具体原因感兴趣的可以仔细思考一下。
2.从评价指标角度
-
谨慎选择AUC作为评价指标:对于数据极端不平衡时,可以观察观察不同算法在同一份数据下的训练结果的precision和recall,这样做有两个好处,一是可以了解不同算法对于数据的敏感程度,二是可以明确采取哪种评价指标更合适。针对机器学习中的数据不平衡问题,建议更多PR(Precision-Recall曲线),而非ROC曲线,具体原因画图即可得知,如果采用ROC曲线来作为评价指标,很容易因为AUC值高而忽略实际对少两样本的效果其实并不理想的情况。
-
不要只看Accuracy:Accuracy可以说是最模糊的一个指标了,因为这个指标高可能压根就不能代表业务的效果好,在实际生产中,我们可能更关注precision/recall/mAP等具体的指标,具体侧重那个指标,得结合实际情况看。
3.从算法角度
-
选择对数据倾斜相对不敏感的算法。如树模型等。
-
集成学习(Ensemble集成算法)。首先从多数类中独立随机抽取出若干子集,将每个子集与少数类数据联合起来训练生成多个基分类器,再加权组成新的分类器,如加法模型、Adaboost、随机森林等。
-
将任务转换成异常检测问题。譬如有这样一个项目,需要从高压线的航拍图片中,将松动的螺丝/零件判断为待检测站点,即负样本,其他作为正样本,这样来看,数据倾斜是非常严重的,而且在图像质量一般的情况下小物体检测的难度较大,所以不如将其转换为无监督的异常检测算法,不用过多的去考虑将数据转换为平衡问题来解决。
目标检测中的不平衡问题的进展
1.GHM_Detection
论文:https://arvix.org/pdf/1811.05181.pdf
github:https://github.com/libuyu/GHM_Detection
本文是香港中文大学发表于 AAAI 2019 的工作,文章从梯度的角度解决样本中常见的正负样本不均衡的问题。从梯度的角度给计算 loss 的样本加权,相比与 OHEM 的硬截断,这种思路和 Focal Loss 一样属于软截断。
文章设计的思路不仅可以用于分类 loss 改进,对回归 loss 也很容易进行嵌入。不需要考虑 Focal Loss 的超参设计问题,同时文章提出的方法效果比 Focal Loss 更好。创新点相当于 FL 的下一步方案,给出了解决 class-imbalance 的另一种思路,开了一条路,估计下一步会有很多这方面的 paper 出现。
2.Focal Loss for Dense Object Detection
论文:
Focal Loss:https://arxiv.org/abs/1708.02002
RetinaNet:https://github.com/unsky/RetinaNet
github:https://github.com/unsky/focal-loss
本文通过重塑标准交叉熵损失来解决这一类不平衡问题。他们的想法是降低简单的负面样本所占的权重,所以他们提出的焦点损失(Focal Loss)方法将训练集中在一系列难点上,并且防止了大量的简单负面例子在训练过程中阻碍探测器学习。如上图,参数 γ 的值选择得越大,模型就会对已经得到了很好的分类的样本忽略得越多,越专注于难的样本的学习。这样的机制就让他们的检测器在密集对象检测这样的真实正面样本比例很低的情况下取得了很高的准确率。对于应对样本不平衡问题的关键方法“焦距损失”,作者们在论文中还提出了两种不同的表现形式,都起到了很好的效果.
3.在线困难样例挖掘(online hard example mining, OHEM)
目标检测的另一个问题是类别不平衡,图像中大部分的区域是不包含目标的,而只有小部分区域包含目标。此外,不同目标的检测难度也有很大差异,绝大部分的目标很容易被检测到,而有一小部分目标却十分困难。OHEM和Boosting的思路类似,其根据损失值将所有候选区域进行排序,并选择损失值最高的一部分候选区域进行优化,使网络更关注于图像中更困难的目标。此外,为了避免选到相互重叠很大的候选区域,OHEM对候选区域根据损失值进行NMS。
总之,针对数据不平衡问题,有多重解决方式,但是不能为了解决这个问题就去改变数据的真实分布来得到更好的结果,可以从算法、loss function的设计等等多种角度来选择解决数据不平衡的方法。
参考:
1.https://www.cnblogs.com/charlotte77/p/10455900.html

