

Hadoop2 使用 YARN 运行 MapReduce 的过程源码分析
Hadoop 使用 YARN 运行 MapReduce 的过程如下图所示:
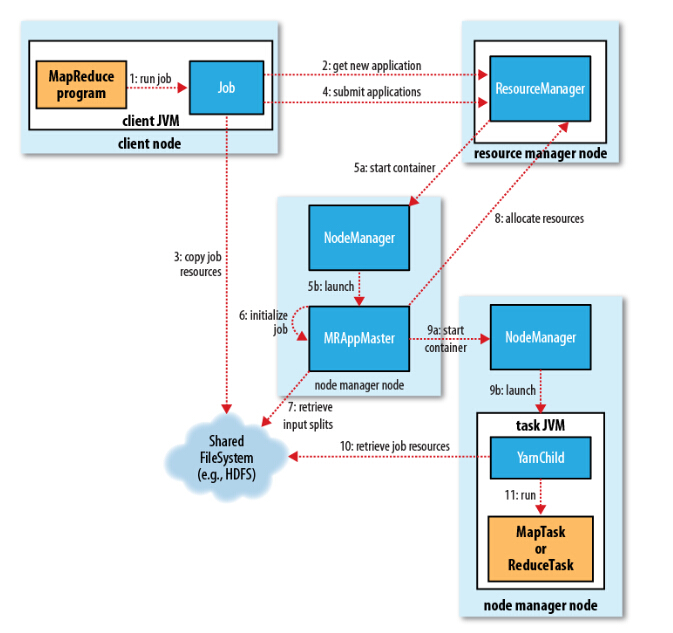
总共分为11步. 这里以 WordCount 为例, 我们在客户端终端提交作业:
# 把本地的 /home/hadoop/test.txt 文件上传到 HDFS 的 /input 下, 之后 HDFS 会对文件分块等 hadoop-2.7.3/bin/hadoop fs -put /home/hadoop/test.txt /input/ # 我们以 hadoop 自带测试例子 wordcount 为例 hadoop-2.7.3/bin/hadoop jar hadoop-2.7.3/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.3.jar wordcount /input /output
第一步: run job ( 运行作业 )
这一步是在 Client 内部进行, hadoop jar .... 是通过 RunJar 运行的, 参考 hadoop-2.7.3/bin/hadoop

# 这段代码在 hadoop-2.7.3/bin/hadoop 中 # the core commands if [ "$COMMAND" = "fs" ] ; then CLASS=org.apache.hadoop.fs.FsShell elif [ "$COMMAND" = "version" ] ; then CLASS=org.apache.hadoop.util.VersionInfo elif [ "$COMMAND" = "jar" ] ; then CLASS=org.apache.hadoop.util.RunJar if [[ -n "${YARN_OPTS}" ]] || [[ -n "${YARN_CLIENT_OPTS}" ]]; then echo "WARNING: Use \"yarn jar\" to launch YARN applications." 1>&2 fi
( 未完待续 )


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 10年+ .NET Coder 心语,封装的思维:从隐藏、稳定开始理解其本质意义
· .NET Core 中如何实现缓存的预热?
· 从 HTTP 原因短语缺失研究 HTTP/2 和 HTTP/3 的设计差异
· AI与.NET技术实操系列:向量存储与相似性搜索在 .NET 中的实现
· 基于Microsoft.Extensions.AI核心库实现RAG应用
· TypeScript + Deepseek 打造卜卦网站:技术与玄学的结合
· 阿里巴巴 QwQ-32B真的超越了 DeepSeek R-1吗?
· 【译】Visual Studio 中新的强大生产力特性
· 10年+ .NET Coder 心语 ── 封装的思维:从隐藏、稳定开始理解其本质意义
· 【设计模式】告别冗长if-else语句:使用策略模式优化代码结构