

HDFS源码分析一-概述
HDFS 主要包含 NameNode, SecondaryNameNode, DataNode 以及 HDFS Client .
我们从以下这几部分讲:
1. HDFS概述
2. NameNode 实现
3. DataNode 实现
4. HDFS Client
我们这里先讲 HDFS 概述:
1. HDFS 概述
首先了解 HDFS: 百度百科 HDFS , 以及 Apache Hadoop 官网 .
1.1 初识 HDFS
1.1.1 HDFS 体系结构
HDFS 采用主从( master/slave )体系结构, 名字节点 NameNode, 数据节点 DataNode 和客户端 Client 是 HDFS 中3个重要的角色.
在一个 HDFS 中, 有一个名字节点和一个第二名字节点, 典型的集群有几十到几百个数据节点, 规模大的系统可以有上千, 甚至几千个数据节点; 而客户端, 一般情况下, 比数据节点的个数还多.
HDFS 的体系结构, 即名字节点, 数据节点和客户端的关系如图所示: (这里没有第二名字节点, 其实第二名字节点只与名字节点通信)
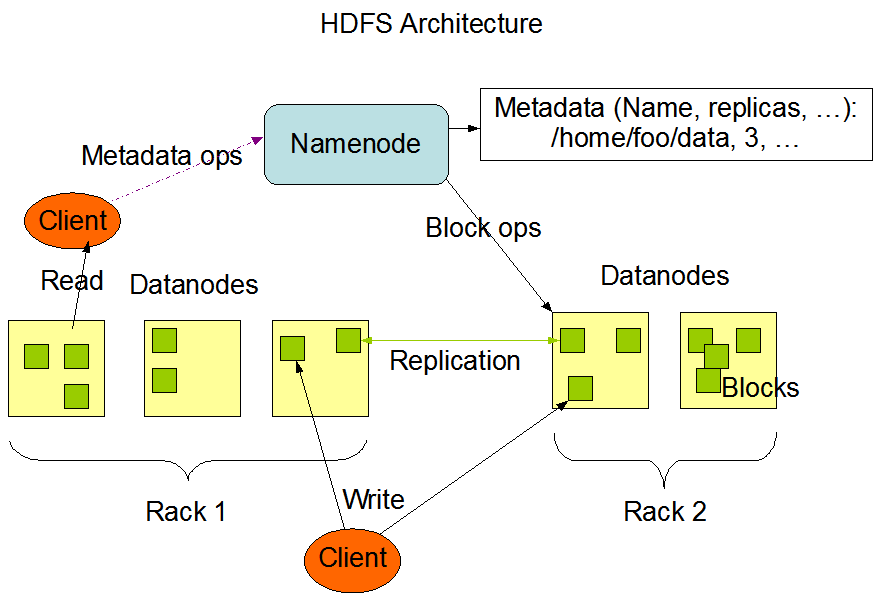
NameNode: 名字节点可以看做是分布式文件系统的管理者, 它负责管理文件系统的命名空间, 集群配置和数据块复制等.
DataNode: 数据节点是文件系统的基本存储单元, 它以数据块的形式保存了 HDFS 中文件的内容和数据块的数据校验信息.
Client: 客户端和名字节点, 数据节点通信, 访问 HDFS 文件系统, 操作文件.
1. 数据块( block )
数据块( Block ), 我们知道, 为了便于管理, 设备往往将存储空间组织成为具有一定结构的存储单位. 如磁盘, 文件是以块的形式存储在磁盘上, 块的大小代表系统读/写操作的最小单位.
HDFS 也有块的概念, HDFS 默认块大小是64MB, HDFS2 默认块大小是128MB.
2. 名字节点( NameNode )和第二名字节点( SecondaryNameNode )
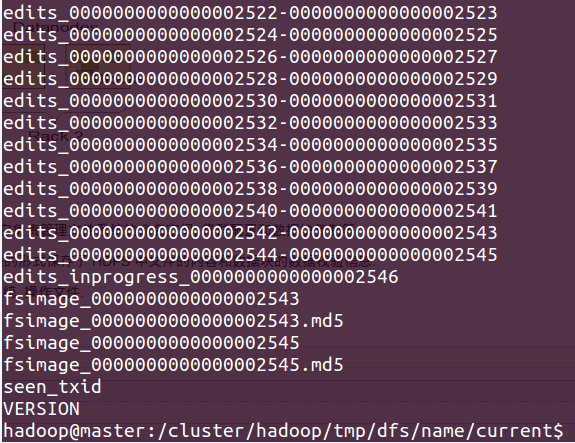
我们集群中的 NameNode 在本地磁盘中存放的数据如下图所示: 包括 current 文件夹 和 in_use.lock 文件, current 文件夹内部如第二个图, 主要是 edits 和 fsimage.
![]()
名字节点是 HDFS 主从结构中主节点上运行的主要进程, 它指导主从结构中的从节点, 数据节点执行底层的 I/O 任务.
名字节点维护者整个文件系统的文件目录树, 文件/目录的元信息和文件相关的数据块索引, 即每个文件对应的数据块列表. 这些信息以两种形式存储在本地文件系统中: 一种是命名空间镜像( File System Image, FSImage, 也称文件系统镜像), 另一种是命名空间镜像的编辑日志( Edit Log ),
命名空间镜像保存着某一特定时刻 HDFS 的目录树, 元信息和数据块索引等信息, 后续对这些信息的改动,则保存在编辑日志中, 它们一起提供了一个完整的名字节点第一关系.
同时, 通过名字节点, 客户端还可以了解到数据块所在的数据节点的信息. 需要注意的是, 名字节点中与数据节点相关的信息不保留在名字节点的本地文件系统中, 也就是上面提到的命名空间镜像和编辑日志中, 名字节点每次启动时, 都会动态的重建这些信息, 这些信息构成了名字节点第二关系. 运行时, 客户端通过名字节点获取上述信息, 然后和数据节点进行交互, 读写问价数据.
另外, 名字节点还获取 HDFS 整体运行状态的一些信息, 如系统的可用空间, 已经使用的空间, 各个数据节点的当前状态等.
第二名字节点是用于定期合并命名空间镜像和镜像的编辑日志的辅助守护进程. 和名字节点一样, 每个集群都有一个第二名字节点, 在大规模部署的条件下, 一般第二名字节点也独自占用一台服务器.
第二名字节点和名字节点的区别在于它不接收或记录 HDFS 的任何变化, 而只是根据集群配置的时间间隔, 不停的获取 HDFS 某一时间点的命名空间镜像和镜像的编辑日志, 合并得到一个新的命名空间镜像. 该新镜像会上传到名字节点, 为名字节点上的名字节点第一关系提供了一个简单的检查点( Checkpoint )机制, 并避免出现编辑日志过大, 导致名字节点启动时间过长的问题.
名字节点是 HDFS 集群只的单一故障点, 通过第二名字节点的检查点, 可以减少停机的时间并减低名字节点元数据丢失的风险. 但是, 第二名字节点不支持名字节点的故障自动恢复, 名字节点失效处理需要人工干预.
3. 数据节点( DataNode )
集群 DataNode 在本地磁盘中存放的数据如下图所示:
HDFS 集群上的从节点都会驻留一个数据节点的守护进程, 来执行分布式文件系统中最忙碌的部分: 将 HDFS 数据块写到 Linux 本地文件系统的实际文件中, 或者从这些实际文件读取数据块.
虽然 HDFS 是为大文件件设计, 但存放在 HDFS 上的文件和传统文件系统类似, 也是将文件分块, 然后进行存储. 但和传统文件系统不同, 在数据节点上, HDFS 文件块( 也就是数据块 )以 Linux 文件系统上的普通文件进行保存. 客户端进行文件内容操作时, 先由名字节点告知客户端每个数据块驻留在哪个数据节点, 然后客户端直接与数据节点守护进程进行通信, 处理与数据尅对应的本地文件. 同时, 数据节点会和其他数据节点进行通信, 复制数据块, 保证数据的冗余性.
数据节点作为从节点, 会不断的向名字节点报告. 初始化时, 每个数据节点将当前存储的数据块告知名字节点. 后续数据节点工作过程中, 数据节点仍会不断的更新名字节点, 为之提供本地修改的相关信息, 并接受来自名字节点的指令, 创建, 移动或者删除本地磁盘上的数据块.
4. 客户端( Client )
客户端是用户和 HDFS 进行交互的手段, HDFS 提供了各种各样的客户端, 包括命令行接口, Java API, Thrift 接口, C 语言库, 用户空间文件系统( FileSystem in Userspace, FUSE )等.
1.1.2 HDFS 源代码结构
1.2 基于远程过程调用的接口( 未完待续 )
1.3 非远程过程调用接口( 未完待续 )
1.4 HDFS 主要流程 ( 未完待续 )


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 10年+ .NET Coder 心语,封装的思维:从隐藏、稳定开始理解其本质意义
· .NET Core 中如何实现缓存的预热?
· 从 HTTP 原因短语缺失研究 HTTP/2 和 HTTP/3 的设计差异
· AI与.NET技术实操系列:向量存储与相似性搜索在 .NET 中的实现
· 基于Microsoft.Extensions.AI核心库实现RAG应用
· TypeScript + Deepseek 打造卜卦网站:技术与玄学的结合
· 阿里巴巴 QwQ-32B真的超越了 DeepSeek R-1吗?
· 【译】Visual Studio 中新的强大生产力特性
· 10年+ .NET Coder 心语 ── 封装的思维:从隐藏、稳定开始理解其本质意义
· 【设计模式】告别冗长if-else语句:使用策略模式优化代码结构