

深度学习之目标检测与目标识别
2020-09-21
参考:https://blog.csdn.net/qq_32241189/article/details/80573087
一 目标识别分类及应用场景
目前可以将现有的基于深度学习的目标检测与识别算法大致分为以下三大类:
① 基于区域建议的目标检测与识别算法,如R-CNN, Fast-R-CNN, Faster-R-CNN;
② 基于回归的目标检测与识别算法,如YOLO, SSD;
③ 基于搜索的目标检测与识别算法,如基于视觉注意的AttentionNet,基于强化学习的算法.
目前, 目标识别主要有以下几个应用场景:
① 安全领域:指纹识别、人脸识别等,代表项目如Face++、依图科技、深醒科技等。
② 军事领域:地形勘察、飞行物识别等,代表项目全悉科技。
③ 交通领域:车牌号识别、无人驾驶、交通标志识别等,代表项目纵目科技、TuSimple(图森科技)、驭势科技等。
④ 医疗领域:心电图、B超、健康管理、营养学等,代表项目智影医疗、图玛深维等。
⑤ 生活领域:智能家居、购物、智能测肤等,代表项目Yi+、木薯科技、肌秘等。
具体可参考这里:从图像识别多样化的应用场景,看计算机视觉的未来价值
二 基于区域建议的目标识别的算法
1. R-CNN
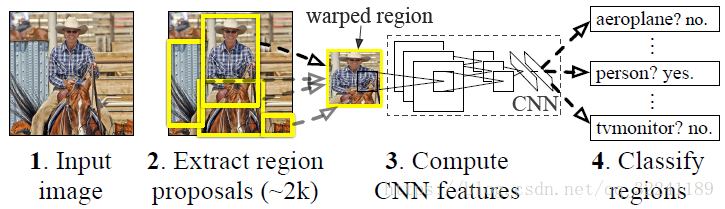
1.1 基本工作流程:
1) 接收一个图像, 使用Selective Search选择大约2000个从上到下的类无关的候选区域(proposal)
2) 将提取出来的候选区域转换为统一大小的图片(拉升/压缩等方法), 使用CNN模型提取每一个候选区域的固定长度的特征.
3) 使用特定类别的线性SVM分类器对每一个候选区域进行分类.
4) Bounding Box回归.
1.2 训练 (使用AlexNet, 要求输入为227*227大小的图像)
1) 预训练. 预训练CNN(边界框标签不可用于该数据).
2) 特征领域的微调. 使用基于CNN的SGD的训练,对模型进行微调.在这里选择学习率为预训练的1/10, 保证微调不破坏初始化.
3) 将所有候选区域与真实框重叠(IoU)大于等于0.5的作为该框类的正例,其余的作为负例.再进行SVM分类.
------这个表明了训练过程是需要Grounding Truth(标定框)的, 是有监督的过程.
注意: 在预训练和微调中使用的CNN网络参数的共享,并且提取的特征数目为(类别N+背景1)个.
1.3 预测
预测的过程和训练基本相同,不同的是:
1) 预测的过程没有初始给定的标定框(Grounding Truth).
2) Bounding Box回归.
其实简单来说, 预测的过程就是根据在训练过程中找到的CNN回归值与所要预测的Grounding Truth之间的关系, 反向推导Grounding Truth的位置.
1.4 R-CNN的优劣分析及小结
1) R-CNN较之于传统方法的主要优势:
① 使用了Select Search进行proposal的选择, 极大地减少了proposal的数量.(百万级别~2000左右)
② 深度学习提取特征来代替人为设计, 较大地提高了精度和效率.
③ 使用了Bounding Box回归, 进一步提高了检测的精度.
2) R-CNN的不足之处:
① 训练分为了多个步骤. 包括Select Search进行proposal的选择, CNN的模型训练(模型的预训练和微调), SVM的分类,Bounding Box回归等, 整个过程需要的时间过长.
② 由于当时的历史等各个因素的影响, 使用了SVM进行多类别分类,要训练多个分类器, 训练时间较长
③ 测试时间长,由于每张图片要处理大量的目标候选框
3) 小结
虽然R-CNN仍然存在很多的问题, 但是它打破了传统的目标识别的方式, 基于深度神经网络的目标识别技术也由此发展起来了.
2. SPP Net
为了后面介绍Fast R-CNN, 这里我们简要介绍下SPP Net的相关内容.
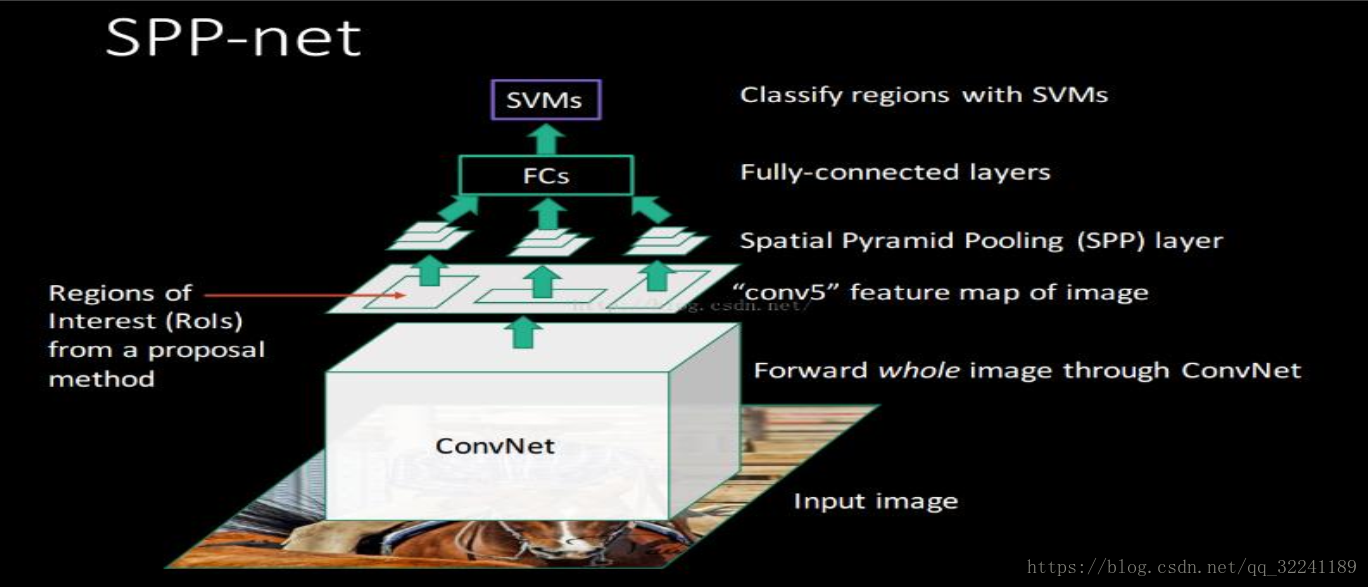
SPP Net具有两个特点:
① 结合金字塔的思想, 实现了实现了CNNs的多尺寸输入. 解决了因为CNNs对输入的格式要求而进行的预处理(如crop,warp等)操作造成的数据信息的丢失问题.
② 只对原图进行一次卷积操作.
2.1 SPP Net的金字塔池化
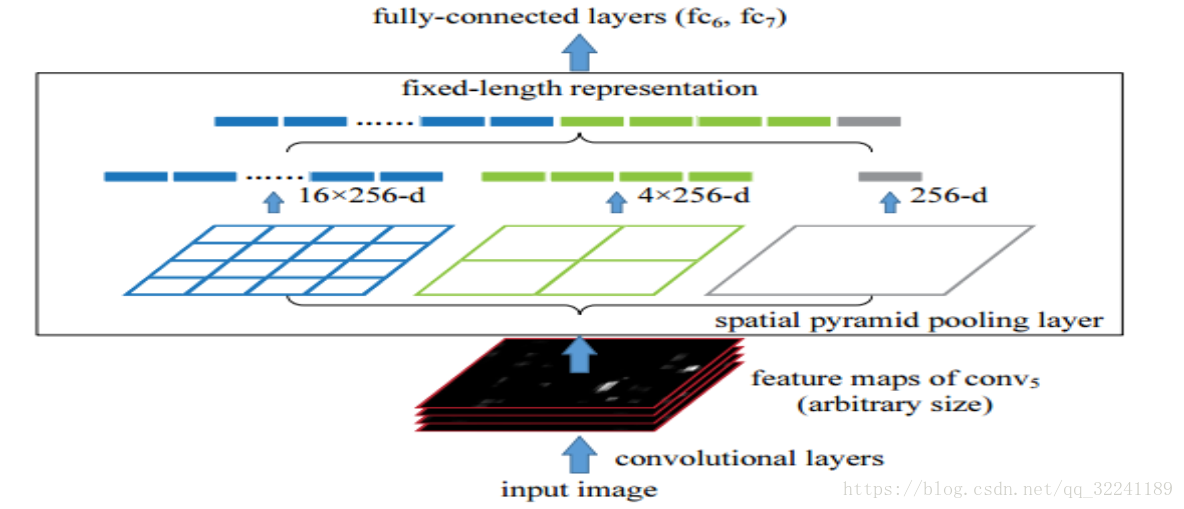
如上图所示, 输入图片经过多个卷积层操作, 再将输出的feature map输入到SPP Net池化层, 最后将池化后的特征输入全连接层.
下面针对上图来说说SPP Net池化层的思想.可以参见这里.
我们使用三层的金字塔池化层pooling,分别设置图片切分成多少块,论文中设置的分别是(1,4,16),然后按照层次对这个特征图feature A进行分别处理(用代码实现就是for(1,2,3层)),也就是在第一层对这个特征图feature A整个特征图进行池化(池化又分为:最大池化,平均池化,随机池化),论文中使用的是最大池化,得到1个特征。
第二层先将这个特征图feature A切分为4个(20,30)的小的特征图,然后使用对应的大小的池化核对其进行池化得到4个特征,
第三层先将这个特征图feature A切分为16个(10,15)的小的特征图,然后使用对应大小的池化核对其进行池化得到16个特征.
最后将这1+4+16=21个特征输入到全连接层,进行权重计算. 当然了,这个层数是可以随意设定的,以及这个图片划分也是可以随意的,只要效果好同时最后能组合成我们需要的特征个数即可.
2.2 SPP Net的一次卷积
由于R-CNN先获取proposal,再进行resize,最后输入CNN卷积, 这样做效率很低. SPP Net针对这一缺点, 提出了只进行一次原图的卷积操, 得到feature map , 然后找到每一个proposal在feature map上对应的patch, 将这个patch作为每个proposal的卷积特征输入到SPP Net中,进行后续运算. 速度提升百倍.
3. Fast R-CNN
Fast R-CNN主要作用是实现了对R-CNN的加速, 它在R-CNN的基础上主要有以下几个方面的改进:
① 借鉴了SPP Net的思路, 提出了简化版的ROI池化层(没有使用金字塔), 同时加入了候选框映射的功能, 使得网络能够进行反向传播, 解决了SPP的整体网络训练的问题.
② 多任务Loss层. 1) 使用了softmax代替SVM进行多分类. 2) SmoothL1Loss取代了 Bounding Box回归.
3.1 基本工作流程
1) 接收一个图像, 使用Selective Search选择大约2000个从上到下的类无关的候选区域(proposal).
2) 对整张图片进行卷积操作提取特征, 得到feature map.
3) 找到每个候选框在feature map中的映射patch. 将patch作为每个候选框的特征输入到ROI池化层及后面的层.
4) 将提取出的候选框的特征输入到softmax分类器中进行分类.==>替换了R-CNN的SVM分类.
5) 使用SmoothL1Loss回归的方法对于候选框进一步调整位置.
3.2 Fast R-CNN的优点及其不足之处
1) 优点
融合了R-CNN和SPP Net的精髓, 并且引入了多任务损失函数 ,极大地特高了算法的效率, 使得整个网络的训练和测试变得较为简单(相对R-CNN而言).
2) 不足
没有对Selective Search进行候选区域(region proposal)的选择进行改进, 仍然不能实现真正意义上的edge-to-edge(端到端)的训练和测试.
4. Faster R-CNN
Faster R-CNN和Faste R-CNN的不同点主要是使用RPN网络进行region proposal的选择, 并且将RPN网络合并到CNN网络中, 真正地实现了端到端的目标检测.这也是 Faster R-CNN的里程碑式的贡献.
Faster R-CNN的网络拓扑图如下图所示.
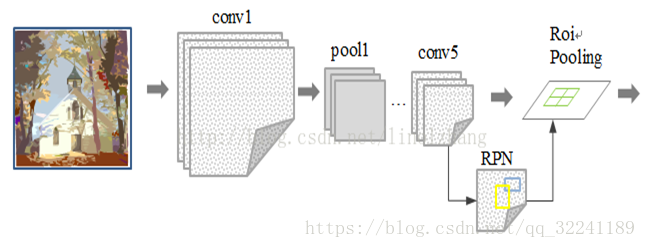
4.1 基本工作流程
1. 对整张图片输进CNN网络,得到feature map.
2. 卷积特征输入到RPN,得到候选框的特征信息.
3. 对候选框中提取出的特征,使用分类器判别是否属于一个特定类.
4. 对于属于某一特征的候选框,用回归器进一步调整其位置.
4.2 RPN
用于提取region proposal的神经网络叫做Region Proposal Network(简称RPN).
RPN网络的特点在于通过滑动窗口的方式实现候选框的提取,每个滑动窗口位置生成9个候选窗口(不同尺度、不同宽高), 提取对应9个候选窗口(anchor)的特征,用于目标分类和边框回归,与FastRCNN类似。目标分类只需要区分候选框内特征为前景或者背景。
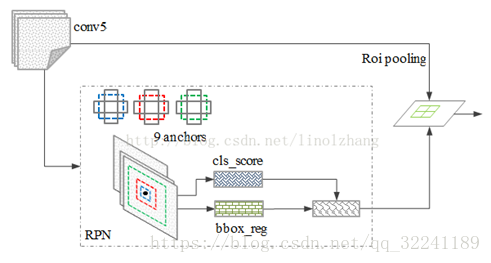
1) 候选框的选取依据:
① 对于IoU大于等于0.7的标记为前景样本, 低于0.3的样本标记为后景样本.
② 丢弃①中所有的边界样本
对于每一个位置,通过两个全连接层(目标分类+边框回归)对每个候选框(anchor)进行判断,并且结合概率值进行舍弃(仅保留约300个anchor),没有显式地提取任何候选窗口,完全使用网络自身完成判断和修正。
2) 损失函数
同时使用两种损失函数:
a. 分类的误差.
b. 前景样本的窗口位置的偏差.
3) 模型训练
从模型训练的角度来看,通过使用共享特征交替训练的方式,达到接近实时的性能,交替训练方式描述为:
1)根据现有网络初始化权值w,训练RPN;
2)用RPN提取训练集上的候选区域,用候选区域训练FastRCNN,更新权值w;
3)重复1、2,直到收敛.
4.3 Faster R-CNN的优点及其不足之处
1) 优点
Faster R-CNN将我们一直以来的目标检测的几个过程(预选框生成, CNN特征提取, SVM/softmax/CNN预选框分类,y 预选框位置微调)完全被统一到同一个网络中去, 从真正意义上实现了从端到端的训练和测试.
2) 不足
预先获取预选区域,再对预选区域进行分类, 仍然具有较大的运算量, 还是没有实现真正意义上的实时检测的要求.
三 小结
本节介绍基于region proposal的目标检测与识别算法, 从最初的R-CNN, fast R-CNN, 直到最后的faster R-CNN, 逐步实现了端到端的目标识别和检测的网络.网络训练和测试的效率也有了一个较大的提升.可以说基于region proposal的R-CNN系列目标检测与识别算法是当前目标最主要的一个分支。
下一章我们将讲述第二类--基于回归的目标检测与识别算法.


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 10年+ .NET Coder 心语,封装的思维:从隐藏、稳定开始理解其本质意义
· .NET Core 中如何实现缓存的预热?
· 从 HTTP 原因短语缺失研究 HTTP/2 和 HTTP/3 的设计差异
· AI与.NET技术实操系列:向量存储与相似性搜索在 .NET 中的实现
· 基于Microsoft.Extensions.AI核心库实现RAG应用
· TypeScript + Deepseek 打造卜卦网站:技术与玄学的结合
· 阿里巴巴 QwQ-32B真的超越了 DeepSeek R-1吗?
· 【译】Visual Studio 中新的强大生产力特性
· 10年+ .NET Coder 心语 ── 封装的思维:从隐藏、稳定开始理解其本质意义
· 【设计模式】告别冗长if-else语句:使用策略模式优化代码结构