
mysql中varchar和char的区别
本篇笔记记录了mysql的innodb引擎中varchar和char的区别
一. 行记录格式
为了后面分析问题的方便,首先了解一下行记录的存储格式。
innodb在存储数据的时候是以行的形式存储的,版本相关,并且有固定的格式。可以通过下面的语句查询当前所用版本的行记录格式:
show table status like '表名';
在版本5.7中默认使用格式是Compact,而在8.0中默认的格式是Dynamic。本文描述的是Compact格式下的行记录。版本查询可以使用语句‘select version();’。
Compact格式是5.0引入的,目的是为了高效存储数据。其存储方式如下:
|
变长字段长度列表 |
NULL标志位 |
记录头信息 |
列1数据 |
列2数据 |
... |
1、变长字段长度列表,注意断句为变长字段-长度-列表。
a) 其描述了行记录中存储内容长度不固定的字段所占用的字节数
b) 按照列的顺序逆序存放
c) 若列的长度小于255个字节,则用一个字节描述
d) 若列的长度大于255个字节,则用两个字节描述
e) 变长字段的长度不能大于65535个字节,所以,最多用两个字节描述其长度:2^16=65536。
2、NULL标志位指示该行数据中是否有null值,有则用1表示,占用1个字节(占用一个字节是书里写的,但是实验下来发现也并非如此,对于书里的内容还是不能全信啊)。
3、记录头信息如下图所示:
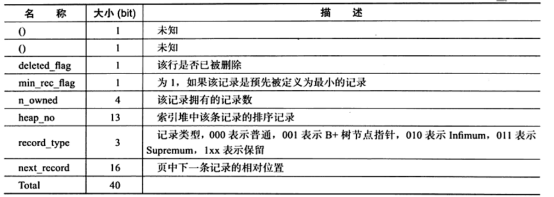
4、数据列
5、两个隐藏列:事务ID和回滚指针
a) 事务ID:占用6个字节,描述最新更新该行的事务的ID
b) 回滚指针:占用7个字节,指向undo log链,用于回滚和mvcc
6、没有主键,每行回增加一个6字节的rowid列
现在通过一个表来具体看一下某一行在底层的存储内容,建表语句及插入数据如下所示:
create table mytest(
t1 varchar(10),
t2 varchar(10),
t3 char(10),
t4 varchar(10)
)engine=innodb charset=latin1 row_format=compact;
insert into mytest
values
('a', 'bb','bb','ccc'),
('d','ee','ee','fff'),
('d', null, null, 'fff');
通过vscode打开数据表的存储文件mytest.ibd(需要安装hexdump for vscode插件),找到数据记录存储的位置,如下所示:
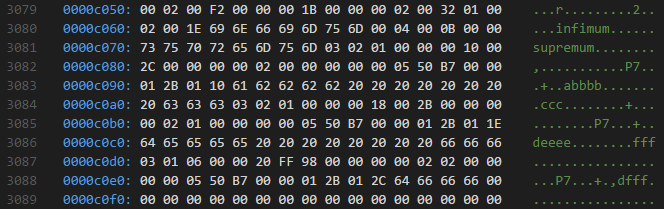
通过分析其二进制内容,找到第一行记录的位置,分析其内容如下:
03 02 01 /* 变长字段长度列表,逆序 */ 00 /* null标志位,第一行没有null值 */ 00 00 10 00 2C /* 记录头,固定5字节长度 */ 00 00 00 00 02 00 /* RowID,innodb自动创建,6字节 */ 00 00 00 00 05 50 /* 事务id */ B7 00 00 01 2B 01 10 /* 回滚指针 */ 61 /* 列1数据 'a' */ 62 62 /* 列2数据 'bb' */ 62 62 20 20 20 20 20 20 20 20 /* 列3数据'bb' */ 63 63 63 /* 列4数据 'ccc' */
从上面可以看到,变长字段长度列表是逆序的,char字段未使用的位会用0x20(空格)表示。
第三条记录的二进制表示如下:
03 01 /* 变长字段长度列表,逆序 */ 06 /* null标志位,第三行的第二列和第三列为null */ 00 00 20 FF 98 /* 记录头,固定5字节长度 */ 00 00 00 00 02 02 /* RowID,innodb自动创建,6字节 */ 00 00 00 00 05 50 /* 事务id */ B7 00 00 01 2B 01 2C /* 回滚指针 */ 64 /* 列1数据 'd' */ 66 66 66 /* 列4数据 'fff */‘
从上面可以看到,无论是char还是varchar,在compact格式下,null值都不占用任何空间,且null标志位中记录了varchar和char为null的列。
前面说到null标志位占用多少内存的问题,下面再做一个测试,该测试中的表有9个可以为null的字段,建表及数据插入语句如下:
create table eight_null (
id int primary key auto_increment,
c1 varchar(10) default null,
c2 varchar(10) default null,
c3 varchar(10) default null,
c4 varchar(10) default null,
c5 varchar(10) default null,
c6 varchar(10) default null,
c7 varchar(10) default null,
c8 char(10) default null,
c9 varchar(10) default null,
c11 varchar(10) not null
)engine=innodb charset=latin1 row_format=compact;
insert into eight_null(c11) values('aaaaaa');
insert into eight_null(c7, c11) values('abbbbbbb','aaaaaaa');
insert into eight_null(c1, c2, c3, c4, c5, c6, c7, c8, c9, c11) values('a','a','a','a','a','a','a','a','a','aaaaaaa');
insert into eight_null(c7, c11) values('a','b');
分析第二行记录如下:
07 08 01 BF /* 0000000110111111 */ 00 00 18 00 29 80 00 00 02 00 00 00 00 05 40 AB 00 00 01 1F 01 10 61 62 62 62 62 62 62 62 61 61 61 61 61 61 61
可以看到,null标志位现在使用两个字节表示。
二. CHAR和VARCHAR
这里首先提出几个问题,并分别分析。
1. char(N)和varchar(N)中的N分别指的是什么?
2. N的上限是多少?
3. char和varchar是否是变长的?
对于问题1,这两者中的N都是指的字符长度。
那么,N最大是多少呢?
首先来看char,我们通过建表语句来分析这个问题:
create table test_char_latin1( a char(255), b char(2) )charset=latin1 engine=INNODB;
上面这个语句是可以执行成功的,但是把列a的长度从255改成256之后就失败了,也就是说,其最大长度是255。
1074 - Column length too big for column 'a' (max = 255); use BLOB or TEXT instead
上面是对于latin1编码下的情况,那么对于最多使用三个字节的utf8编码的char字段呢?实验证明,最高同样是255。也就是说,在utf8编码下,char字段最多支持255个字符,即255*3=765个字节。
-----------
对于varchar,前面说过,最多使用两个字节记录varchar列的长度,也就是65535,平时我们也会说varchar的最大长度是65535,那么是不是这么回事呢?看下面的建表语句
create table test_varchar( a varchar(65535) )charset=latin1 engine=INNODB; 1118 - Row size too large. The maximum row size for the used table type, not counting BLOBs, is 65535. This includes storage overhead, check the manual. You have to change some columns to TEXT or BLOBs
失败了,也就是说,在latin1编码(单字节编码)下,最大是支持不了65535的,通过实验证明,最高支持到65532。
那么在utf8编码下呢,我们执行下面的建表语句,直接返回错误并指明了最高支持字符数为21845个(注:这里需要知道,mysql中utf8最多使用三个字节编码字符,而21845*3=65535):
create table test_varchar( a varchar(65532) )charset=utf8 engine=INNODB; 1074 - Column length too big for column 'a' (max = 21845); use BLOB or TEXT instead
综上所述,65535只是理论上的varchar字段最多支持的字节数,而在实际使用varchar(n)的时候,n最高为多少还需要根据具体的编码来确定。
那么,char和varchar是否是变长的呢?前面提过,varchar肯定是变长的,在compact记录格式下,会有专门的【变长字段长度列表】记录varchar字段的长度,并且varchar字段没有使用0x20补位。那么,char呢?首先分析latin1编码下的情况,先建表:
create table test_char_latin1(
a char(10),
b char(2)
)charset=latin1 engine=INNODB;
insert into test_char_latin1 values('12345','ab');
分析其存储文件,如下:

00 /* null标记位 */ 00 00 10 FF F2 00 00 00 00 02 03 00 00 00 00 05 98 EB 00 00 01 72 01 10 31 32 33 34 35 20 20 20 20 20 /* 12345 */ 61 62 /* ab */
可以看到,确实没有记录字段长度,且第一个字段的部分字节使用了0x20填充。
那么在utf8编码下呢,同样先建表,再分析插入数据。
create table test_char_utf8(
a char(10),
b char(2)
)charset=utf8 engine=INNODB;
insert into test_char_utf8 values('中国人','ab');
insert into test_char_utf8 values('我是中国人','ab');
为了便于分析,先查一下utf8下‘中国人’和‘我是中国人’的16进制编码:
SELECT hex(CONVERT( '中国人' USING utf8 )); E4B8ADE59BBDE4BABA SELECT hex(CONVERT( '我是中国人' USING utf8 )); E68891E698AFE4B8ADE59BBDE4BABA
对于第一行记录,其二进制内容为:

02 0A /* 变长字段长度列表 */ 00 /* null标记位 */ 00 00 10 00 27 00 00 00 00 02 04 00 00 00 00 05 B4 FE 00 00 01 82 01 10 E4 B8 AD E5 9B BD E4 BA BA 20 /* 中国人 */ 61 62 /* ab */
‘中国人’三个字在utf8编码下占用9个字节,可以看到,在utf8编码下,char的两个字段都记录了其长度,也就是说char也被当作了变长字段,其长度记录的是varchar实际占用的包含填充字节的字节数。需要注意的是,在字段a下,由于存储内容不足10个字节,总长度还是为10个字节,且不足的地方用0x20填充。
第二行记录的内容如下:

02 0F /* 变长字段长度列表 */ 00 /* null标记位 */ 00 00 18 FF C9 00 00 00 00 02 05 00 00 00 00 05 B5 FF 00 00 01 83 01 10 E6 88 91 E6 98 AF E4 B8 AD E5 9B BD E4 BA BA /* 我是中国人 */ 61 62 /* ab */
‘我是中国人’三个字在utf8编码下占用15个字节,所以第一行的第二个字节的内容为0x0F=15,印证了长度列表存储的是实际占用的字节数。
最后再做一个实验,在同时存在varchar和char,且char都为null的情况下,如何存储:
create table test_char_utf8(
a char(10),
b char(2),
c varchar(10)
)charset=utf8 engine=INNODB;
insert into test_char_utf8 (c) values('aaaaaa');
06 /* 变长字段长度列表 */
03 /* null标记位 */
00 00 10 FF F1
00 00 00 00 02 06
00 00 00 00 05 C7
A9 00 00 01 1D 01 10
61 61 61 61 61 /* aaaaaa */
从上面可以看到,varchar和char已经没有区别了。
总结:
通过上面的分析可以知道,在单字节编码下,char不是变长的,不记录字段长度;在变长编码下,char是变长字段,且除了最大字符数外,与varchar没有区别。
参考:
姜承尧.《MySQL技术内幕InnoDB存储引擎》第二版

