数字人论文: dreamtalk笔记
3.2
dreamtalk 有3个关键组成: 一个去噪网络, 一个风格嘴部专家, 一个风格预测器
去噪网络
输入\(A_w=[a_i]_{i=l-w}^{l+w}\), 这里w是窗口大小.
开始帧是\(m_{0}\).也就是我们的真实图片,加噪

其中t值得是diffusion的stept, t\(\in{1,..,T}\).
最后我们随机取一个帧\(m_T \in N(0,I)\),然后我们用逆过程去噪.
这个过程记作\(m^*_0=E_\theta(m_t,t,A_w,R)\)
*表示是生成的变量. \(m_t是随机一个正态分布, t是扩散时间,A_w是音频片段输入, R是风格\)
风格嘴部专家
我们需要专注嘴部所以需要一个嘴部专家网络来加强效果.我们加强了分各个.

这个网络名字叫做E
a是语音,m是帧,R是风格
风格预测:
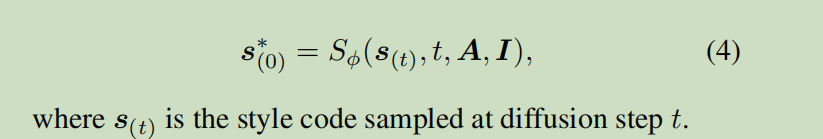

 浙公网安备 33010602011771号
浙公网安备 33010602011771号