开源协议 和llm 评测
开源协议
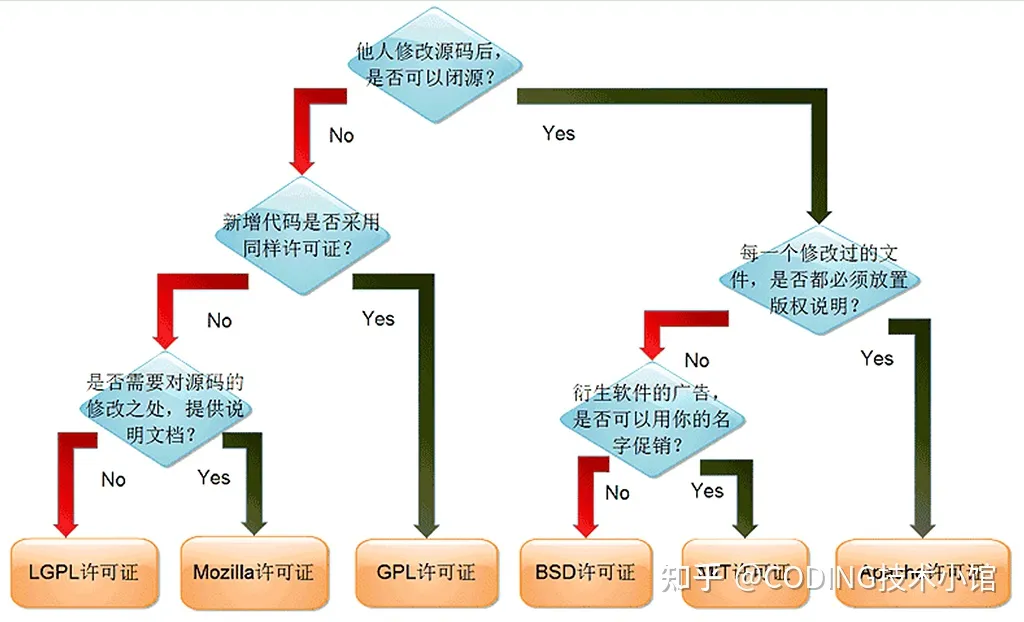
总结:
开源能商用的:
- bsd
- mit
- apache
- cc by 4.0
- cc by sa 4.0
- CreativeML Open RAIL-M
- llama2
- wtfpl
不能商用:(或者用了必须开源)
- cc by nc 4.0
- cc by nc nd
- gpl
- mozila
- lgpl
- agpl
效果评测
We evaluate models on 7 key benchmarks using the Eleuther AI Language Model Evaluation Harness , a unified framework to test generative language models on a large number of different evaluation tasks.(https://github.com/EleutherAI/lm-evaluation-harness)
- AI2 Reasoning Challenge (25-shot) - a set of grade-school science questions.
- HellaSwag (10-shot) - a test of commonsense inference, which is easy for humans (~95%) but challenging for SOTA models.
- MMLU (5-shot) - a test to measure a text model's multitask accuracy. The test covers 57 tasks including elementary mathematics, US history, computer science, law, and more.
- TruthfulQA (0-shot) - a test to measure a model's propensity to reproduce falsehoods commonly found online. Note: TruthfulQA in the Harness is actually a minima a 6-shots task, as it is prepended by 6 examples systematically, even when launched using 0 for the number of few-shot examples.
- Winogrande (5-shot) - an adversarial and difficult Winograd benchmark at scale, for commonsense reasoning.
- GSM8k (5-shot) - diverse grade school math word problems to measure a model's ability to solve multi-step mathematical reasoning problems.
For all these evaluations, a higher score is a better score. We chose these benchmarks as they test a variety of reasoning and general knowledge across a wide variety of fields in 0-shot and few-shot settings.
推理速度
作者:夏天的阳光
链接:https://www.zhihu.com/question/591112394/answer/3164341451
来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
-
延迟(Latency)延迟是指从输入文本数据到得到结果的时间。正常情况下,延迟越低越好。而由于人类阅读速度是有上限的。所以大语言模型的有一个合理延迟区间。成年人的阅读速度:英文文本平均阅读速度大约是200-300词/分钟,即3-5词/秒。中文文本平均阅读速度大约是300-500字符/分钟,即5-8字符/秒。分词器分词法则:对于英文,常见的分词器(如WordPiece或BPE)可能会将一个单词分为多个token,尤其是对于长单词或不常见的单词。因此,英文中的一个token并不总是对应一个完整的单词。所以模型输出速度可能需要提高到5-10 tokens/秒。对于中文,由于其字符性质,常见的分词器可能会将每个字符视为一个token,但也可能会将常见的词汇或短语合并为一个token。输出速度应达到5-8 tokens/秒。实际上,为了提供流畅的用户体验,模型的输出速度可能需要远远超过这个速度,尤其是在交互式应用中,用户可能希望模型能够即时响应。合理的目标是使模型的输出速度至少达到10-15 tokens/秒。一般来说,单token的延迟在100ms以内,可确保流畅的用户体验。关注的是输出token
-
First token latency指从输入文本到生成第一个单词的延迟。即用户在提问后等待出第一个结果的时间。也是实际应用中业务比较关注的另一个延迟指标。一般在2-4秒内用户比较容易接受的。
-
吞吐量(Throughput)指模型在单位时间内能处理的数据量(通常表示为每秒处理的tokens数量)。这个指标直接影响到模型在实际应用中的效率、成本和用户体验。吞吐量越大越好,但是因为硬件资源的限制,吞吐量都会有上限。关注的是输入token.
-
QPS(Queries Per Second)衡量系统或服务在每秒内可以处理的查询或请求的数量。QPS越大,说明能支持的用户越多,但是这个指标不仅仅受限于模型推理,更多的负载均衡以及服务策略等因素。类似还有TPS
qps, tps的区别
QPS:Queries Per Second,顾名思义:“每秒查询率”,是一台服务器每秒能够相应的查询次数,是对一个特定的查询服务器在规定时间内所处理流量多少的衡量标准。
TPS:是TransactionsPerSecond的缩写,也就是事务数/秒。它是软件测试结果的测量单位。一个事务是指一个客户机向服务器发送请求然后服务器做出反应的过程。客户机在发送请求时开始计时,收到服务器响应后结束计时,以此来计算使用的时间和完成的事务个数。
TPS处理流程:
Tps即每秒处理事务数,包括了
1、用户请求服务器
2、服务器自己的内部查询等处理
3、服务器返回给用户
这三个过程,每秒能够完成N个这三个过程,Tps也就是3;
QPS基本类似于TPS,但是不同的是,对于一个页面的一次访问,形成一个TPS;但一次页面请求,可能产生多次对服务器的请求,服务器对这些请求,就可计入QPS之中。每秒查询率QPS是对一个特定的查询服务器在规定时间内所处理流量多少的衡量标准
一个事务是指一个客户机向服务器发送请求然后服务器做出反应的过程。客户机在发送请求时开始计时,收到服务器响应后结束计时,以此来计算使用的时间和完成的事务个数。
如果是对一个接口(单场景)压测,且这个接口内部不会再去请求其它接口,那么TPS等于QPS,否则,TPS不等于QPS

 浙公网安备 33010602011771号
浙公网安备 33010602011771号