

大模型量化3
https://huggingface.co/blog/4bit-transformers-bitsandbytes
1. 8 位float
The FP8 (floating point 8) format has been first introduced in the paper “FP8 for Deep Learning” with two different FP8 encodings: E4M3 (4-bit exponent and 3-bit mantissa) and E5M2 (5-bit exponent and 2-bit mantissa).
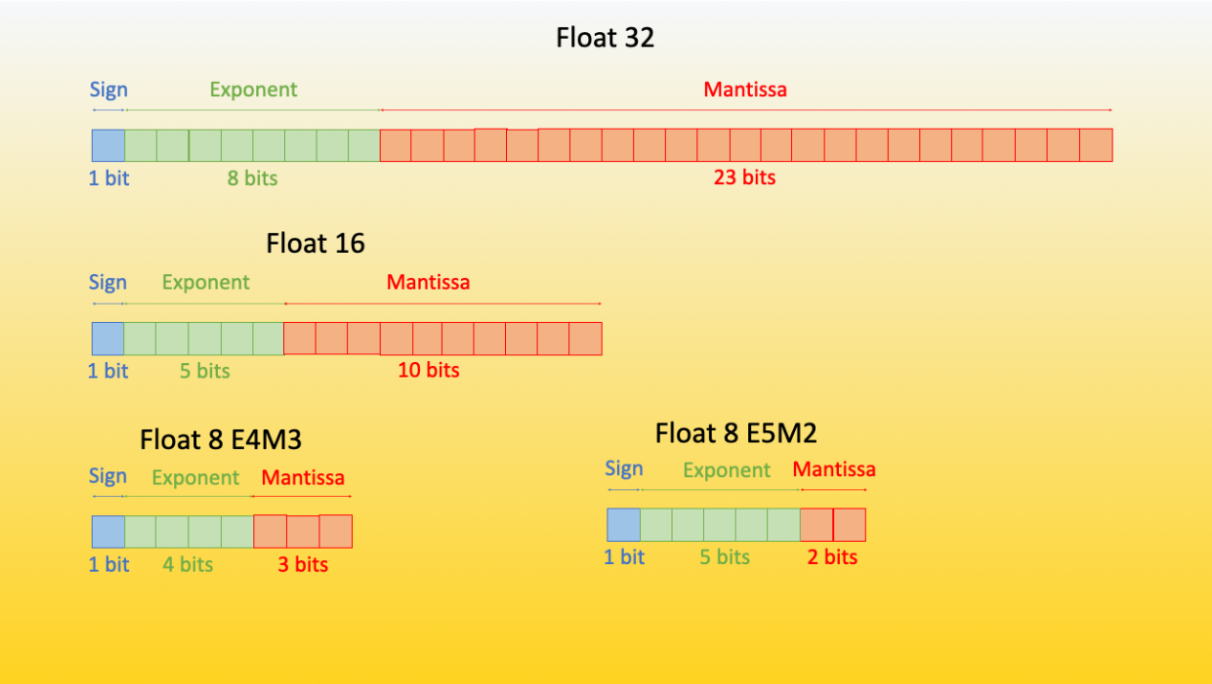
The potential floating points that can be represented in the E4M3 format are in the range -448 to 448, whereas in the E5M2 format, as the number of bits of the exponent increases, the range increases to -57344 to 57344 - but with a loss of precision because the number of possible representations remains constant. It has been empirically proven that the E4M3 is best suited for the forward pass, and the second version is best suited for the backward computation
这部分意思就是8bit 浮点数. E4M3精度高,所以forward比较好, E5M2精度低bakward比较好.这是经验上的结论. 我理解是求梯度时候不要求那么精确. 因为反正需要走一个方向做梯度下降即可. 但是forward运算必须保证精度才能效果好!!!!!!!这是很trivial的道理.
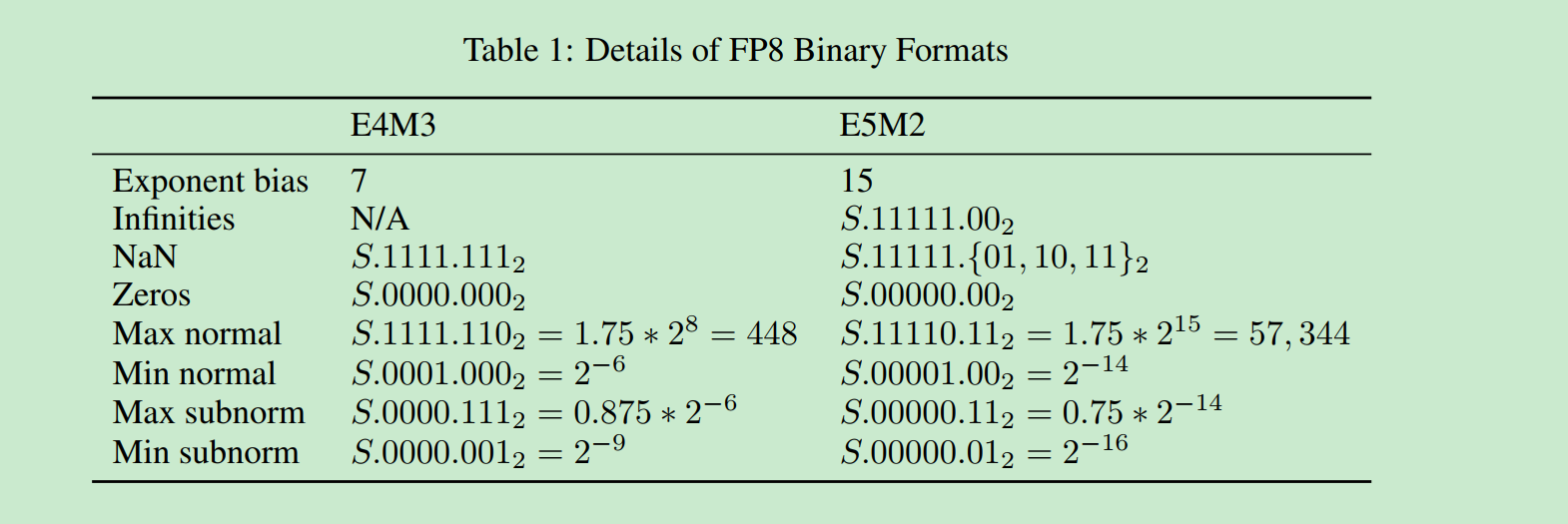
https://aijishu.com/a/1060000000385081 这里面讲解FP8的详细知识.
有两个点需要注意: 第一个是指数偏移量是-7, 第二个是小数部分求和之后要加一. 一些特例要另算.
FP4:
for example, with 2 exponent bits and one mantissa bit the representations 1101 would be:
-1 * 2^(2) * (1 + 2^-1) = -1 * 4 * 1.5 = -6
1101: 1表示负数. 10表示指数2, 1表示1.5
整体上跟fp8区别不大. 这种叫2e1m 还可以3e0m
Qlora:
More specifically, QLoRA uses 4-bit quantization to compress a pretrained language model. The LM parameters are then frozen and a relatively small number of trainable parameters are added to the model in the form of Low-Rank Adapters. During finetuning, QLoRA backpropagates gradients through the frozen 4-bit quantized pretrained language model into the Low-Rank Adapters. The LoRA layers are the only parameters being updated during training. Read more about LoRA in the original LoRA paper.
QLora就是 fp4版本的lora
实战版本:
Advanced usage: 这里面代码很实用.
from transformers import BitsAndBytesConfig
nf4_config = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_quant_type="nf4",
bnb_4bit_use_double_quant=True,
bnb_4bit_compute_dtype=torch.bfloat16
)
model_nf4 = AutoModelForCausalLM.from_pretrained(model_id, quantization_config=nf4_config)
from transformers import BitsAndBytesConfig
double_quant_config = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_use_double_quant=True, # 双量化, 开启后精度更高
)
model_double_quant = AutoModelForCausalLM.from_pretrained(model_id, quantization_config=double_quant_config)选参心得:
A rule of thumb is: use double quant if you have problems with memory, use NF4 for higher precision, and use a 16-bit dtype for faster finetuning. For instance in the inference demo, we use nested quantization, bfloat16 compute dtype and NF4 quantization to fit gpt-neo-x-20b (40GB) entirely in 4bit in a single 16GB GPU.
所以推荐是双量化, nested 就是嵌套也就是双重的意思. 然后bf16, nf4. 即可.
硬件:
Note that this method is only compatible with GPUs, hence it is not possible to quantize models in 4bit on a CPU. Among GPUs, there should not be any hardware requirement about this method, therefore any GPU could be used to run the 4bit quantization as long as you have CUDA>=11.2 installed. Keep also in mind that the computation is not done in 4bit, the weights and activations are compressed to that format and the computation is still kept in the desired or native dtype.
训练:
Can we train 4bit/8bit models?
It is not possible to perform pure 4bit training on these models. However, you can train these models by leveraging parameter efficient fine tuning methods (PEFT) and train for example adapters on top of them. That is what is done in the paper and is officially supported by the PEFT library from Hugging Face. We also provide a training notebook and recommend users to check the QLoRA repository if they are interested in replicating the results from the paper.
使用peft可以训练.
应用前景:
In RLHF (Reinforcement Learning with Human Feedback) it is possible to load a single base model, in 4bit and train multiple adapters on top of it, one for the reward modeling, and another for the value policy training. A more detailed blogpost and announcement will be made soon about this use case.
在rlhf中. 同一个basemodel, 接2个不同的adapter 头. 一个作为奖励模型, 一个座位policy 模型.

