

大模型量化论文1
大模型如何轻量化训练和部署是非常重要的问题.
相关论文也需要学习.
第一篇我就写这里.
8-BIT OPTIMIZERS VIA BLOCK-WISE QUANTIZATION
1. 基本知识:
1.1状态优化器
一个优化器在迭代第t次时候更新神经网络参数w的公式为:
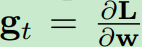 . L是损失函数.
. L是损失函数.
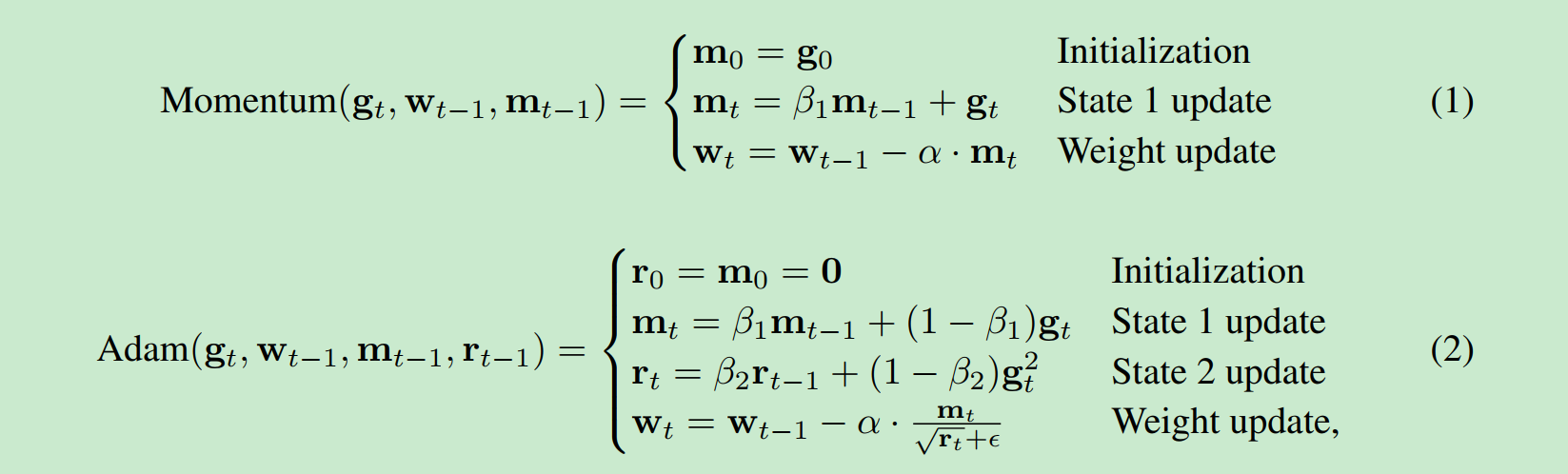
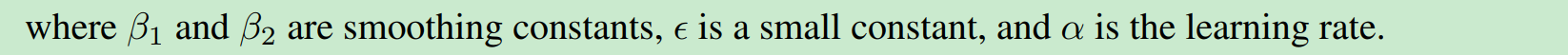
分别是sgd和adam的算法.
1.2 非线性量化
1.3 动态三量化
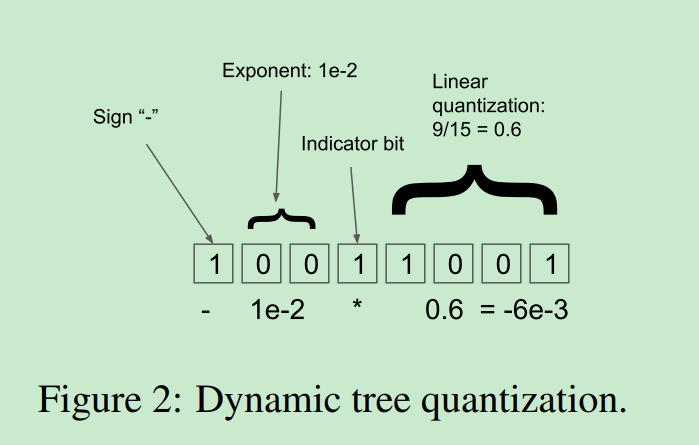
其中indicator bit用来做分隔符. 讲一下上面的图: 第一个位置标示整体的负号, 后面多少个0 标示 e的负多少. 这里就是e-2.
然后后面是1001=9 除以最大值1111=15 得到数值.
这个算法只能在[-1,1]区间时候使用, 这点可以在最开始时候进行max 归一化即可.
通过移动Indicator bit.
研究一下表示的最大值和精度问题:
1 0 0 0 0 0 0 0 表示 e-7
11 0 0 0 0 0 1 表示 1/111111=1/63
所以最小值可以表示e-7, 最精细可以表示1/63
2. 8-bit 优化器
这一个章节才是我们论文的算法.
2.1分块化.
2.2 去掉符号位
基本就这些内容了. 论文比较旧. 我再去hf 上找找新的算法.

