codeformer 论文笔记
直接老套路, 直接第三章开始.
3. 方法论:
主要方法是用一个离散的表示空间来弱化图像重造的不稳定性,不确定性. 并且能补充高清细节.
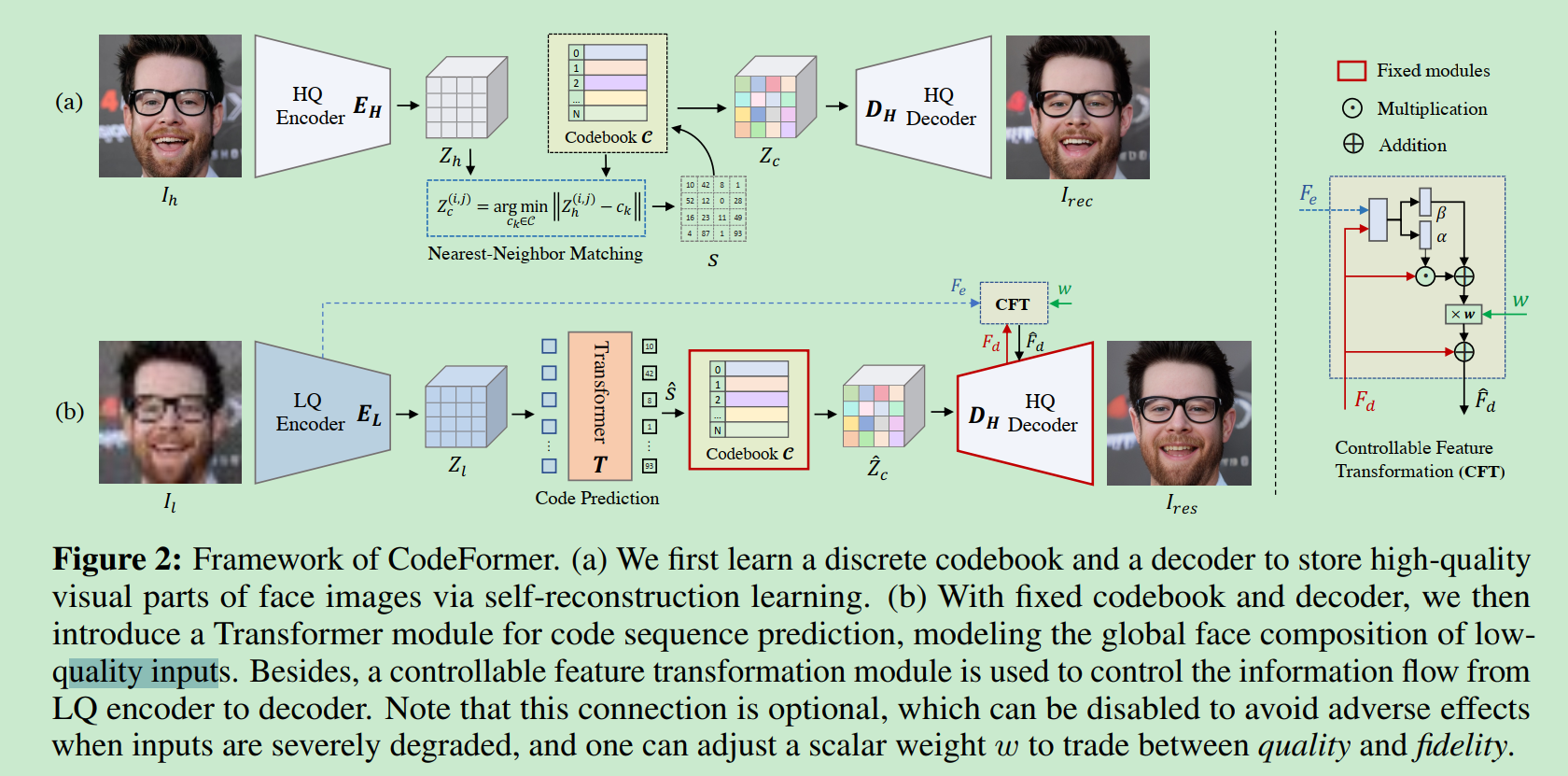
3.1 codebook 学习 (第一部分)
在Fig2(a)中, HQ : 表示high quality LQ 表示low quatlity
I_h表示一个图片, 通过一个编码器E_H编码为Z_h∈R^{m*n*d}
我们把Z_h中每一个元素(pixel), 也就是每一个d维向量, 我们一共有m*n个. 把这些向量用最近距离去codebook中查询然后替换.得到
Z_c 同时还有一个序列s.
这个过程里面codebook里面的向量是需要学的. Encoder是锁住的.
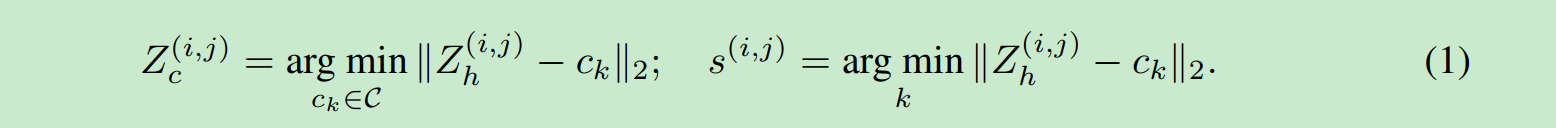
用数学刻画是上面2个式子.第一个是在codebook中找到最近的. 第二个是把最近的序列记录下来记做s.
D_H, 使用Z_c来创造I_rec, 其中s也作为一个输入.
损失函数:
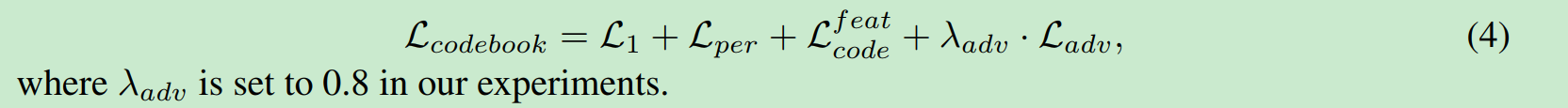
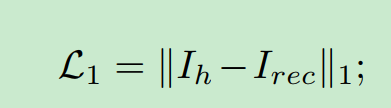
L1是图像重构.
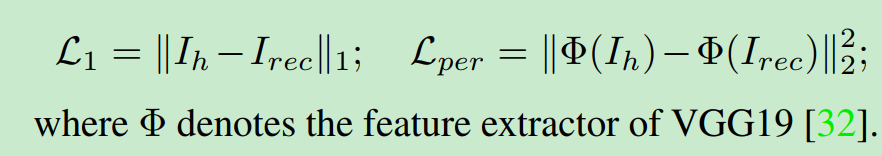
L_per是vgg下的距离.
adversarial loss是对抗loss
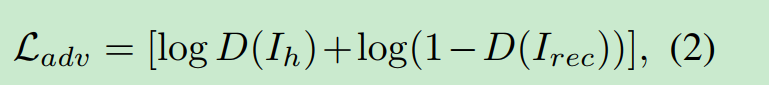
这里应该是有一个D网络来给真实性打分. 目标是让原始的图片分值小, 让新生成的分值大, 也就是让区分器分不清即可保证图片生成的逼真.
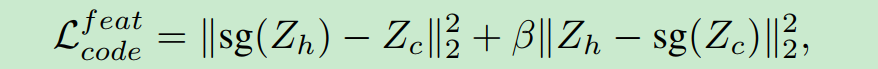
这个用来缩短codebook和Z_h的距离.
β=0.25 . 上面式子第一个部分用来更新codebook, 第二个部分用来更新encoder. 这个很好理解. sg是stop gradient, 哪个套上sg哪个表示不学习.
3.2 codebook lookup transformer 学习
这个部分对应上面的图b, 我们固定codebook 和D_H, 然后学习E_H部分. 学习之后这个编码器就叫做E_L.
Z_l向量拆分成m*n个向量. 这些向量整体记做Z_l^v . 这mn个向量, 进入transformer, 输出一个mn长的int序列.
等于一个翻译任务.
目标函数:
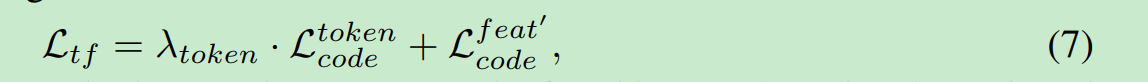
训练transfromer的loss记做L_tf
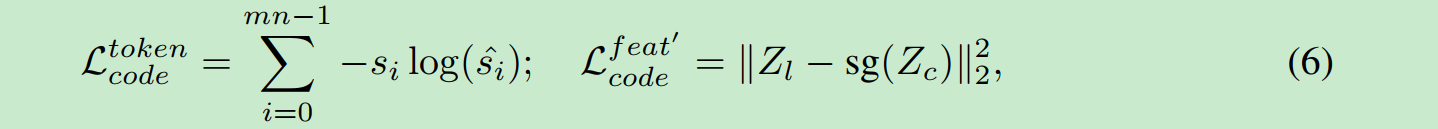
code是Z_l^v 组成的mn长序列, token是mn长序列.
使用的是交叉熵. nlp经典分类任务.
第二个式子是学习编码器.Z_l逼近Z_c.
3.3 Controllable Feature Transformation
记做CFT,
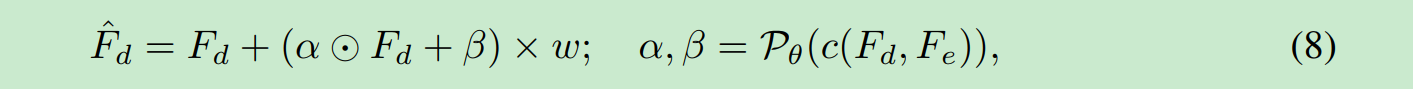
其中w是我们给的参数. alphat, beta是右边式子生成出来的参数.
左边式子是线性的. 所以我们w=0时候, 就是不实用这个8式子.也就是只输出F_d. 也就是学一个端到端,所以是最逼近我们生成的.
w=1时候,变化最大.让我们结果有一些变动.利用编码器得到的部分进行一些修改. 所以真实性更大!!!!!!!!!!
训练时候我们w恒为1, 这样训完之后他就有0到1之间变化的能力了.
下面就是实验秀结果的部分了. 不在我们学习范围之内, 后续会对源码进行研究. 会更新相关实现细节.

 浙公网安备 33010602011771号
浙公网安备 33010602011771号