

Seeing What You Said: Talking Face Generation Guided by a Lip Reading Expert 论文笔记
最近一直在看虚拟人像.
最关键的论文就是wav2lip. 目前项目中也是用的这个. 一个视频加一个语音, 就可以生成用视频里面的头,加语音的新视频.
现在看这篇论文Seeing What You Said: Talking Face Generation Guided by a Lip Reading Expert.
主要是搜了没有相关论文, 所以就自己写一下笔记作为记录学习.
还是惯例,直接第三章走起.
3.1
做一个lip reading expert. 使用AV-Hubert提供一个唇语阅读器. (也就是输入视频,返回里面说的文字)
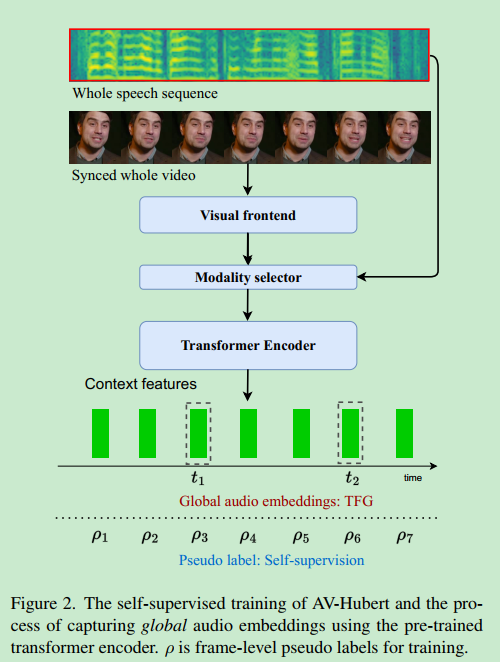
看图的意思是这个模型输入video,输出音频.
3.2
音频编码器使用cnn和transfomer.
3.3
视频编码编码个人信息和姿态信息.
姿态信息是人脸下半部分挡住,不学嘴唇运动信息.
个人信息是视频里面随机片段.
3.4
第一个损失函数:
![]() 其中Ni是多少个对, vi是真实脸, vi'是生成的脸.
其中Ni是多少个对, vi是真实脸, vi'是生成的脸.
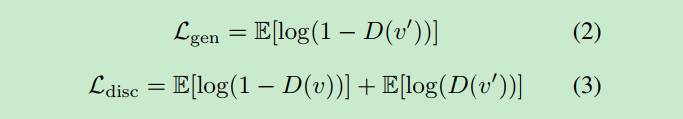
基本的gan公式. D网络判定假图片的结果一定是趋近于0. (结果表示判定为真的概率), 所以我们看2函数, 让loss越小, 那么D(v')越大, 这时候D网络固化, v'会变动,也就是让D越看不出来是假的.
再看3函数. loss越小表示右边2个都越小. 第一个表示D(v)越大, 后面表示D(v')越小, 正好都是我们要的D的效果. 这里跟标准gan网络一样, 没有创新点.
3.5
lip reading loss:
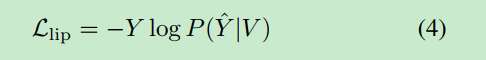
分类的交叉熵. -plogp^ , 记忆这个就是- 概率 log 概率2. 至于哪个是概率p ,哪个是phat, 因为分类最后接softmax, 里面有exp函数. 最后还需要纲量统一,再log回来. 我们计算的是phat, 真实的是p .所以公式是
-plogp^ .
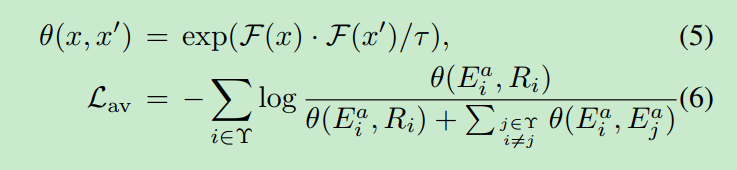
公式5. 表示两个特征向量x 和x' 的相似度. 内积.
公式6. Ei^a表示第i个样本里面音频编码. Ri表示第i个样本的视频编码.
所以分子是自己跟自己的编码相似度. 分母是自己跟自己相似度加上自己跟其他的相似度.
显然这个6的loss越小表示. 自己跟自己的相似度越大. 自己跟其他的相似度越远. 这也是标准的 对比学习.
没了.下面就是实验结果. 我会去跑代码. 权重需要FQ. 这几天试试效果. 代码细节会github上开源.

