
深入理解layernorm在nlp中的含义和计算公式. 附带cv上ln的理解.
import torch
import torch.nn as nn
from torch.nn import LayerNorm
# NLP Example
batch, sentence_length, embedding_dim = 2, 2, 3
embedding = torch.randn(batch, sentence_length, embedding_dim)
layer_norm = nn.LayerNorm(embedding_dim) # shape是10. 所以结果是他在最后一个维度上保持shape.前面20*5 都做mean了. nlp经典做法是对最后一个维度做layernorm.也就是对channel做. The mean and standard-deviation are calculated over the last D dimensions
mean = embedding.mean(-1, keepdim=True)
# Activate module
layer_norm(embedding)#========我们理解这个就需要手动计算. 返回的是(2,2,3)
# Image Example
下面我们手动计算.
例如我们上面跑的.
embedding:
tensor([[[ 0.1769, 0.9543, 0.4827],
[ 0.3181, -1.1836, 1.3440]],
[[ 2.1516, 1.7302, 0.8906],
[-0.0393, 0.0352, 0.2574]]])
layer_norm(embedding):
tensor([[[-1.1292, 1.3019, -0.1727],
[ 0.1528, -1.2940, 1.1412]],
[[ 1.0699, 0.2659, -1.3358],
[-0.9815, -0.3905, 1.3720]]], grad_fn=<NativeLayerNormBackward>)
那么我们手动来计算这个-1.1292: 其实他就是 ( 0.1769- mean(0.1769, 0.9543, 0.4827) ) / std(0.1769, 0.9543, 0.4827)
总结: layernorm 一般在nlp上就是对于channel 做归一化. 其他维度都保持.
最后送上经典图:
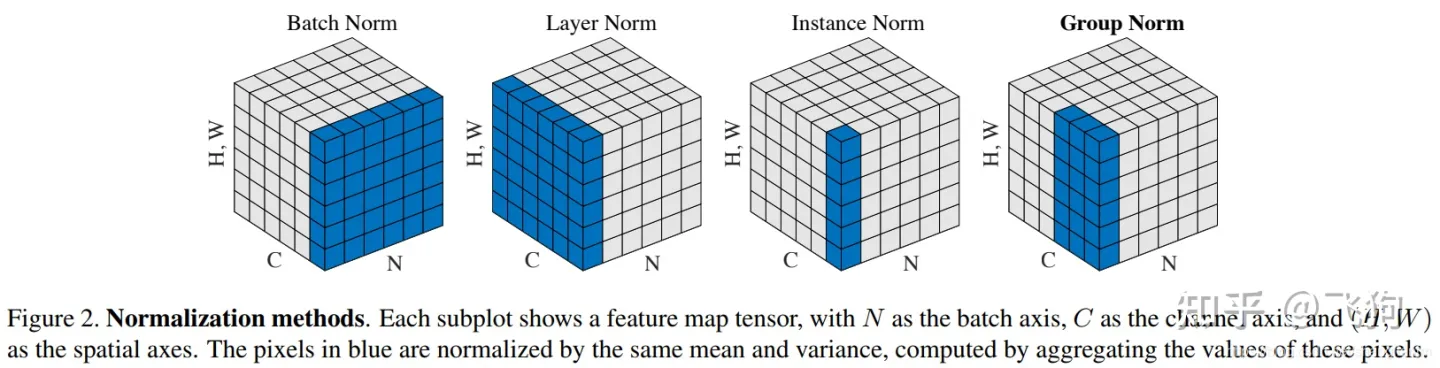
这个图经典的含义是. 我们看第二个图. 图颜色的部分我们来每次计算他们的归一化. 这个跟nlp里面使用的是不一样的.
他是玩cv的. 对应的cv代码是这个:
N, C, H, W = 20, 5, 10, 10
input = torch.randn(N, C, H, W)
# Normalize over the last three dimensions (i.e. the channel and spatial dimensions)
# as shown in the image below
layer_norm = nn.LayerNorm([C, H, W])
output = layer_norm(input)
当然cv里面ln不常用.
ps: 本文中的代码都是torch官方源码. 可以在torch库包中看到.
