
Java FileInputStream和FileOutputStream
java.io.FileInputStream:
1、文件字节输入流,万能的,任何类型的文件都可以采用这个流来读。
2、字节的方式,完成输入的操作,完成读的操作(硬盘---> 内存)
3、IDEA默认的当前路径是哪里?工程Project的根就是IDEA的默认当前路径。
4、FileInputStream类的其它常用方法:
int available():返回流当中剩余的没有读到的字节数量
long skip(long n):跳过几个字节不读。
//int readByte = fis.read();
// 还剩下可以读的字节数量是:5
//System.out.println("剩下多少个字节没有读:" + fis.available());
// 这个方法有什么用?
//byte[] bytes = new byte[fis.available()]; // 这种方式不太适合太大的文件,因为byte[]数组不能太大。
// 不需要循环了。
// 直接读一次就行了。
// skip跳过几个字节不读取
fis.skip(3);
System.out.println(fis.read()); //100
package com.bjpowernode.java.io; import java.io.FileInputStream; import java.io.FileNotFoundException; import java.io.IOException; public class FileInputStreamTest04 { public static void main(String[] args) { FileInputStream fis = null; try { // 一个个字节读 /* fis = new FileInputStream("D:/course/JavaProjects/02-JavaSE/temp"); // 开始读 int readData = fis.read(); // 这个方法的返回值是:读取到的“字节”本身。 System.out.println(readData); //97 */ fis = new FileInputStream("chapter23/src/tempfile3"); // 准备一个byte数组 byte[] bytes = new byte[4]; /*while(true){ int readCount = fis.read(bytes); if(readCount == -1){ break; } // 把byte数组转换成字符串,读到多少个转换多少个。 System.out.print(new String(bytes, 0, readCount)); }*/ int readCount = 0; while((readCount = fis.read(bytes)) != -1) { System.out.print(new String(bytes, 0, readCount)); } } catch (FileNotFoundException e) { e.printStackTrace(); } catch (IOException e) { e.printStackTrace(); } finally { if (fis != null) { try { fis.close(); } catch (IOException e) { e.printStackTrace(); } } } } }
java.io.FileOutputStream:
文件字节输出流,负责写。
从内存到硬盘。
flush()是强行将缓冲区中的内容输出,否则直到缓冲区满后才会一次性的将内容输出
package com.bjpowernode.java.io; import java.io.FileNotFoundException; import java.io.FileOutputStream; import java.io.IOException; /** * 文件字节输出流,负责写。 * 从内存到硬盘。 */ public class FileOutputStreamTest01 { public static void main(String[] args) { FileOutputStream fos = null; try { // myfile文件不存在的时候会自动新建! // 这种方式谨慎使用,这种方式会先将原文件清空,然后重新写入。 //fos = new FileOutputStream("myfile"); //fos = new FileOutputStream("chapter23/src/tempfile3"); // 以追加的方式在文件末尾写入。不会清空原文件内容。 fos = new FileOutputStream("chapter23/src/tempfile3", true); // 开始写。 byte[] bytes = {97, 98, 99, 100}; // 将byte数组全部写出! fos.write(bytes); // abcd // 将byte数组的一部分写出! fos.write(bytes, 0, 2); // 再写出ab // 字符串 String s = "我是一个中国人,我骄傲!!!"; // 将字符串转换成byte数组。 byte[] bs = s.getBytes(); // 写 fos.write(bs); // 写完之后,最后一定要刷新 fos.flush(); } catch (FileNotFoundException e) { e.printStackTrace(); } catch (IOException e) { e.printStackTrace(); } finally { if (fos != null) { try { fos.close(); } catch (IOException e) { e.printStackTrace(); } } } } }
文件拷贝
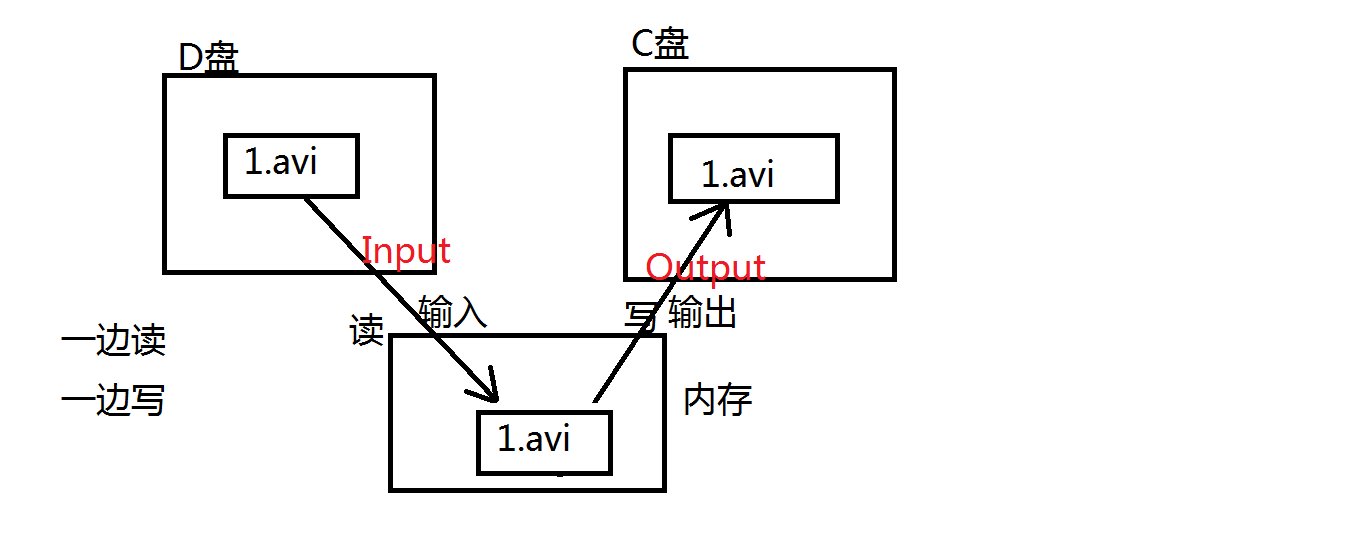
package com.bjpowernode.java.io; import java.io.FileInputStream; import java.io.FileNotFoundException; import java.io.FileOutputStream; import java.io.IOException; /* 使用FileInputStream + FileOutputStream完成文件的拷贝。 拷贝的过程应该是一边读,一边写。 使用以上的字节流拷贝文件的时候,文件类型随意,万能的。什么样的文件都能拷贝。 */ public class Copy01 { public static void main(String[] args) { FileInputStream fis = null; FileOutputStream fos = null; try { // 创建一个输入流对象 fis = new FileInputStream("D:\\course\\02-JavaSE\\video\\chapter01\\动力节点-JavaSE-杜聚宾-001-文件扩展名的显示.avi"); // 创建一个输出流对象 fos = new FileOutputStream("C:\\动力节点-JavaSE-杜聚宾-001-文件扩展名的显示.avi"); // 最核心的:一边读,一边写 byte[] bytes = new byte[1024 * 1024]; // 1MB(一次最多拷贝1MB。) int readCount = 0; while((readCount = fis.read(bytes)) != -1) { fos.write(bytes, 0, readCount); } // 刷新,输出流最后要刷新 fos.flush(); } catch (FileNotFoundException e) { e.printStackTrace(); } catch (IOException e) { e.printStackTrace(); } finally { // 分开try,不要一起try。 // 一起try的时候,其中一个出现异常,可能会影响到另一个流的关闭。 if (fos != null) { try { fos.close(); } catch (IOException e) { e.printStackTrace(); } } if (fis != null) { try { fis.close(); } catch (IOException e) { e.printStackTrace(); } } } } }

