分享一份关于Hadoop2.2.0集群环境搭建文档
一,准备环境
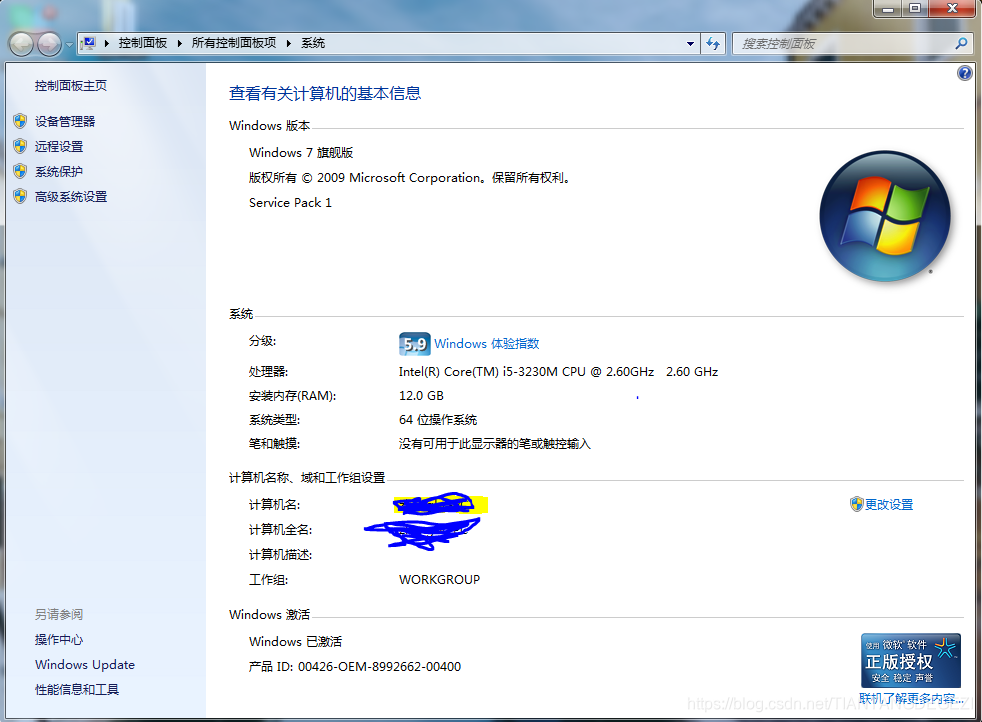
PC基本配置如下:
处理器:Intel(R) Core(TM) i5-3230M CPU @ 2.6GHz 2.60GHz
安装内存(RAM): 12.0GB
系统类型:64位操作系统
- 初始化四台
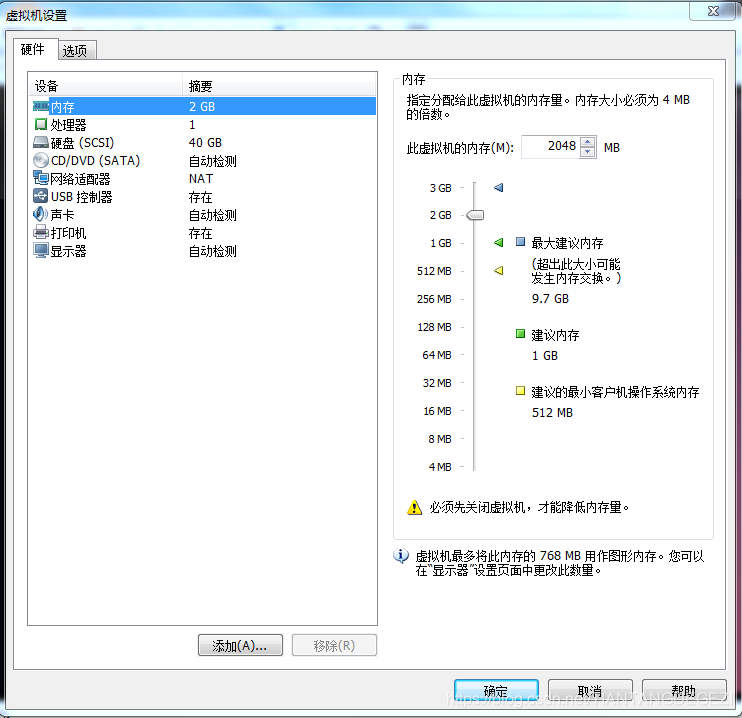
Ubuntu-14.04_x64虚拟机,配置如下:
内存:2GB
处理器:1
硬盘:40G
网络适配器:NAT
系统:Linux ubuntu 4.4.0-142-generic #168~14.04.1-Ubuntu SMP Sat Jan 19 11:26:28 UTC 2019 x86_64 x86_64 x86_64 GNU/Linux
- 修改系统时区
~ sudo timedatectl set-timezone "Asia/Shanghai"
- 为方便使用建议如下配置:
安装
oh-my-zsh插件;设置
VIM行号;安装
SSH插件服务;安装
vsftpd插件服务并加以配置,方便文件上传下载;在
PC上安装XSHELL客户端;在
PC上安装FTP客户端。
- 需要的软件:
jdk-7u51-linux-x64.gz 链接:http://pan.baidu.com/s/1dFFT1GP 密码:cc5t
hadoop-2.2.0-x64.tar.gz https://download.csdn.net/download/wwyymmddbb/10203840
- 在虚拟机做如下步骤:创建目录,存储工具包
/home/zhangbocheng,并利用FTP上传相关软件包。
二,安装单机环境
- 安装
Java1.7.0
~ mkdir java
~ cd java
➜ java tar -xf /home/zhangbocheng/jdk-7u51-linux-x64.gz
➜ java ln -s jdk1.7.0_51 JDK
➜ java vi ~/.bashrc
➜ java vi ~/.zshrc
export JAVA_HOME=$HOME/java/java
export PATH=$JAVA_HOME/bin:$PATH
:wq
➜ java source ~/.bashrc
➜ java source ~/.zshrc
➜ java java -version
java version "1.7.0_51"
Java(TM) SE Runtime Environment (build 1.7.0_51-b13)
Java HotSpot(TM) 64-Bit Server VM (build 24.51-b03, mixed mode)

- 安装
Hadoop2.2.0
➜ ~ tar -xf /home/zhangbocheng/hadoop-2.2.0-x64.tar.gz
➜ ~ mv hadoop-2.2.0 hadoop2.2.0
➜ ~ mkdir hadoop2.2.0/hdfs
➜ ~ mkdir hadoop2.2.0/hdfs/name
➜ ~ mkdir hadoop2.2.0/hdfs/data
➜ ~ mkdir hadoop2.2.0/logs
➜ ~ mkdir hadoop2.2.0/tmp
- 配置环境
➜ ~ vi .zshrc
export JAVA_HOME=$HOME/java/jdk
export CLASSPATH=$JAVA_HOME/lib/tool.jar:$JAVA_HOME/lib/dt.jar
export PATH=$JAVA_HOME/bin:$PATH
➜ ~ source .zshrc
➜ ~ echo $CLASSPATH
/home/zhangbc/java/jdk/lib/tool.jar:/home/zhangbc/java/jdk/lib/dt.jar
➜ ~ vi .zshrc
export HADOOP_HOME=$HOME/hadoop2.2.0
export PATH=$HADOOP_HOME/sbin:$HADOOP_HOME/bin:$JAVA_HOME/bin:$PATH
export HADOOP_LOG_DIR=$HADOOP_HOME/logs
export YARN_LOG_DIR=$HADOOP_LOG_DIR
➜ ~ source .zshrc
➜ ~ hadoop version
Hadoop 2.2.0
Subversion Unknown -r Unknown
Compiled by root on 2014-09-21T22:41Z
Compiled with protoc 2.5.0
From source with checksum 79e53ce7994d1628b240f09af91e1af4
This command was run using /home/zhangbc/hadoop2.2.0/share/hadoop/common/hadoop-common-2.2.0.jar

- 修改
Hadoop2.2.0配置文件
# 检查并修改以下三个文件中JAVA_HOME的值
➜ ~ vi hadoop2.2.0/etc/hadoop/hadoop-env.sh
➜ ~ vi hadoop2.2.0/etc/hadoop/yarn-env.sh
➜ ~ vi hadoop2.2.0/etc/hadoop/mapred-env.sh # 只需要去掉注释加以修改
export JAVA_HOME=${JAVA_HOME} # 错误
export JAVA_HOME=/home/zhangbc/java/jdk # 正确
# 添加集群的slave节点
➜ ~ vi hadoop2.2.0/etc/hadoop/slaves
# localhost
slave_1
slave_2
slave_3
➜ ~ vi hadoop2.2.0/etc/hadoop/core-site.xml
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://master:9000/</value>
<descrption>设定namenode的主机名及其端口</descrption>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/home/zhangbc/hadoop2.2.0/tmp/hadoop-${user.name}</value>
<descrption>存储临时文件</descrption>
</property>
<property>
<name>hadoop.proxyuser.hadoop.hosts</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.hadoop.groups</name>
<value>*</value>
</property>
</configuration>
➜ ~ vi hadoop2.2.0/etc/hadoop/hdfs-site.xml
<configuration>
<property>
<name>dfs.namenode.http-address</name>
<value>master:50070</value>
<descrption>设定NameNode地址及其端口</descrption>
</property>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>slave_1:50090</value>
<descrption>设定SecondNameNode地址及其端口</descrption>
</property>
<property>
<name>dfs.replication</name>
<value>3</value>
<descrption>设定HDFS存储文件的副本个数,默认为3</descrption>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:///home/zhangbc/hadoop2.2.0/hdfs/name</value>
<descrption>设置NameNode用来持续存储命名空间和交换日志的本地文件系统路径</descrption>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:///home/zhangbc/hadoop2.2.0/hdfs/data</value>
<descrption>设置DataNode在本地存储文件的目录列表</descrption>
</property>
<property>
<name>dfs.namenode.checkpoint.dir</name>
<value>file:///home/zhangbc/hadoop2.2.0/hdfs/namesecondary</value>
<descrption>设置SecondaryNameNode存储临时镜像的本地文件系统路径,
若这是一个用逗号分隔的列表,则镜像会冗余复制到所有目录</descrption>
</property>
<property>
<name>dfs.webhdfs.enable</name>
<value>true</value>
<descrption>是否允许网页浏览HDFS文件</descrption>
</property>
<property>
<name>dfs.stream-buffer-size</name>
<value>131072</value>
<descrption>默认为4KB,作为Hadoop的缓冲区,用于Hapdoop读写HDFS的文件,
还有map的输出都用到了这个缓冲区容量,131072=128KB</descrption>
</property>
</configuration>
➜ ~ vi hadoop2.2.0/etc/hadoop/mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>master:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>master:19888</value>
</property>
</configuration>
➜ ~ vi hadoop2.2.0/etc/hadoop/yarn-site.xml
<configuration>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>master</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
<property>
<name>yarn.resourcemanager.address</name>
<value>master:8032</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>master:8030</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>master:8031</value>
</property>
<property>
<name>yarn.resourcemanager.admin.address</name>
<value>master:8033</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>master:8088</value>
</property>
</configuration>
- 修改主机名称(千万不要含有下划线
_)
➜ ~ sudo hostname master # 只对当前状态生效
[sudo] password for zhangbc:
➜ ~ hostname
master
➜ ~ sudo vi /etc/hostname # 永久修改
master
:wq
- 关闭防火墙
➜ ~ service ufw status
ufw start/running
➜ ~ sudo service ufw stop
[sudo] password for zhangbc:
ufw stop/waiting
➜ ~ service ufw status
ufw stop/waiting
三,克隆VM
通过 VMware Workstation工具,关闭当前虚拟机,对其克隆三台虚拟机作为从机使用。
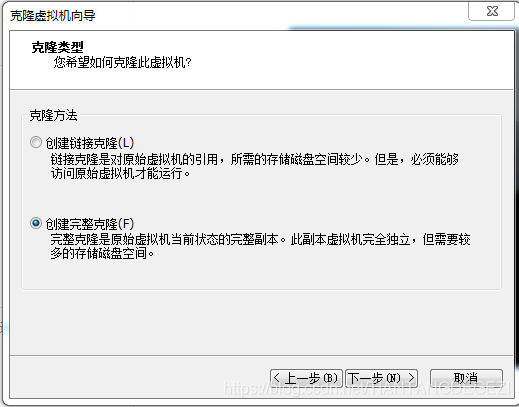
克隆方法选择“创建完整克隆(F)”,如图所示:
四,搭建集群
- 修改三台从机
slave的host,并再重启使之生效。
➜ ~ sudo vi /etc/hostname
➜ ~ sudo vi /etc/hosts
➜ ~ sudo reboot
- 对所有集群中的服务器进行检查,关闭防火墙并禁止掉。
➜ ~ sudo service ufw status
[sudo] password for zhangbc:
ufw start/running
➜ ~ sudo service ufw stop
ufw stop/waiting
➜ ~ sudo service ufw status
ufw stop/waiting
➜ ~ sudo ufw disable
Firewall stopped and disabled on system startup
- 对所有集群中的服务器绑定
hostname与IP
➜ ~ sudo vi /etc/hosts
192.168.71.128 master
192.168.71.129 slave_1
192.168.71.130 slave_2
192.168.71.131 slave_3
- 对所有集群中的服务器创建
SSH密钥,完成相关验证,注意保留原有的其他密钥,以备他用
➜ .ssh mv id_rsa id_rsa_git
➜ .ssh mv id_rsa.pub id_rsa_git.pub
➜ .ssh ssh-keygen -t rsa -P '' -f ~/.ssh/id_rsa
# 生成authorized_keys
➜ .ssh cat id_rsa.pub >> authorized_keys
# 设置权限
➜ .ssh sudo chmod 600 authorized_keys
# ssh登录本机,并退出
➜ .ssh ssh localhost
The authenticity of host 'localhost (127.0.0.1)' can't be established.
ECDSA key fingerprint is b6:fa:8d:2b:2d:0d:e4:fd:4f:44:ed:37:3f:79:b6:ce.
Are you sure you want to continue connecting (yes/no)? yes
Warning: Permanently added 'localhost' (ECDSA) to the list of known hosts.
Welcome to Ubuntu 14.04.6 LTS (GNU/Linux 4.4.0-142-generic x86_64)
* Documentation: https://help.ubuntu.com/
New release '16.04.6 LTS' available.
Run 'do-release-upgrade' to upgrade to it.
Your Hardware Enablement Stack (HWE) is supported until April 2019.
Last login: Wed Nov 13 20:17:41 2019 from 192.168.71.1
➜ ~ exit
Connection to localhost closed.
➜ .ssh
- 配置各个节点之间免密登录
# 将slave_1节点rsa通过ssh-copy-id分别复制到master,slave_2,slave_3
➜ ~ ssh-copy-id -i ~/.ssh/id_rsa.pub master
➜ ~ ssh-copy-id -i ~/.ssh/id_rsa.pub slave_2
➜ ~ ssh-copy-id -i ~/.ssh/id_rsa.pub slave_3
# 验证登录
➜ ~ ssh master
➜ ~ ssh slave_2
➜ ~ ssh slave_3
# 其他节点同步骤
五,Hadoop启动与测试
- 格式化文件系统
➜ ~ hdfs namenode -format
19/11/13 21:57:48 INFO namenode.NameNode: STARTUP_MSG:
/************************************************************
STARTUP_MSG: Starting NameNode
STARTUP_MSG: host = master/192.168.71.128
STARTUP_MSG: args = [-format]
STARTUP_MSG: version = 2.2.0
.........
19/11/13 21:57:55 INFO util.ExitUtil: Exiting with status 0 # 表示成功
.........
- 启动
HDFS
zhangbc@master:~$ start-dfs.sh
Starting namenodes on [master]
master: starting namenode, logging to /home/zhangbc/hadoop2.2.0/logs/hadoop-zhangbc-namenode-master.out
slave_1: starting datanode, logging to /home/zhangbc/hadoop2.2.0/logs/hadoop-zhangbc-datanode-slave_1.out
slave_3: starting datanode, logging to /home/zhangbc/hadoop2.2.0/logs/hadoop-zhangbc-datanode-slave_3.out
slave_2: starting datanode, logging to /home/zhangbc/hadoop2.2.0/logs/hadoop-zhangbc-datanode-slave_2.out
zhangbc@master:~$ jps
6524 Jps
5771 NameNode
zhangbc@slave_1:~$ jps
4919 Jps
4818 DataNode
zhangbc@slave_2:~$ jps
4919 Jps
4801 DataNode
zhangbc@slave_3:~$ jps
4705 DataNode
4800 Jps
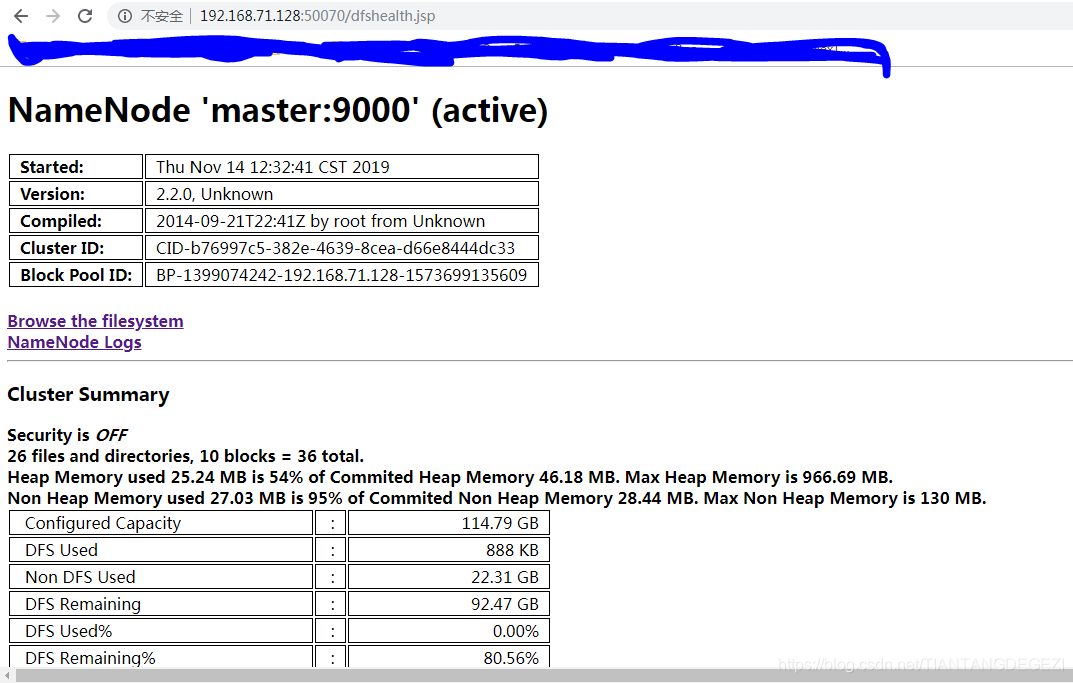
WEB验证:http://192.168.71.128:50070
- 启动
Yarn
zhangbc@master:~$ start-yarn.sh
starting yarn daemons
starting resourcemanager, logging to /home/zhangbc/hadoop2.2.0/logs/yarn-zhangbc-resourcemanager-master.out
slave_2: starting nodemanager, logging to /home/zhangbc/hadoop2.2.0/logs/yarn-zhangbc-nodemanager-slave_2.out
slave_1: starting nodemanager, logging to /home/zhangbc/hadoop2.2.0/logs/yarn-zhangbc-nodemanager-slave_1.out
slave_3: starting nodemanager, logging to /home/zhangbc/hadoop2.2.0/logs/yarn-zhangbc-nodemanager-slave_3.out
zhangbc@master:~$ jps
5771 NameNode
6642 Jps
zhangbc@slave_1:~$ jps
5099 Jps
4818 DataNode
5011 NodeManager
zhangbc@slave_2:~$ jps
5101 Jps
5016 NodeManager
4801 DataNode
zhangbc@slave_2:~$ jps
5101 Jps
5016 NodeManager
4801 DataNode
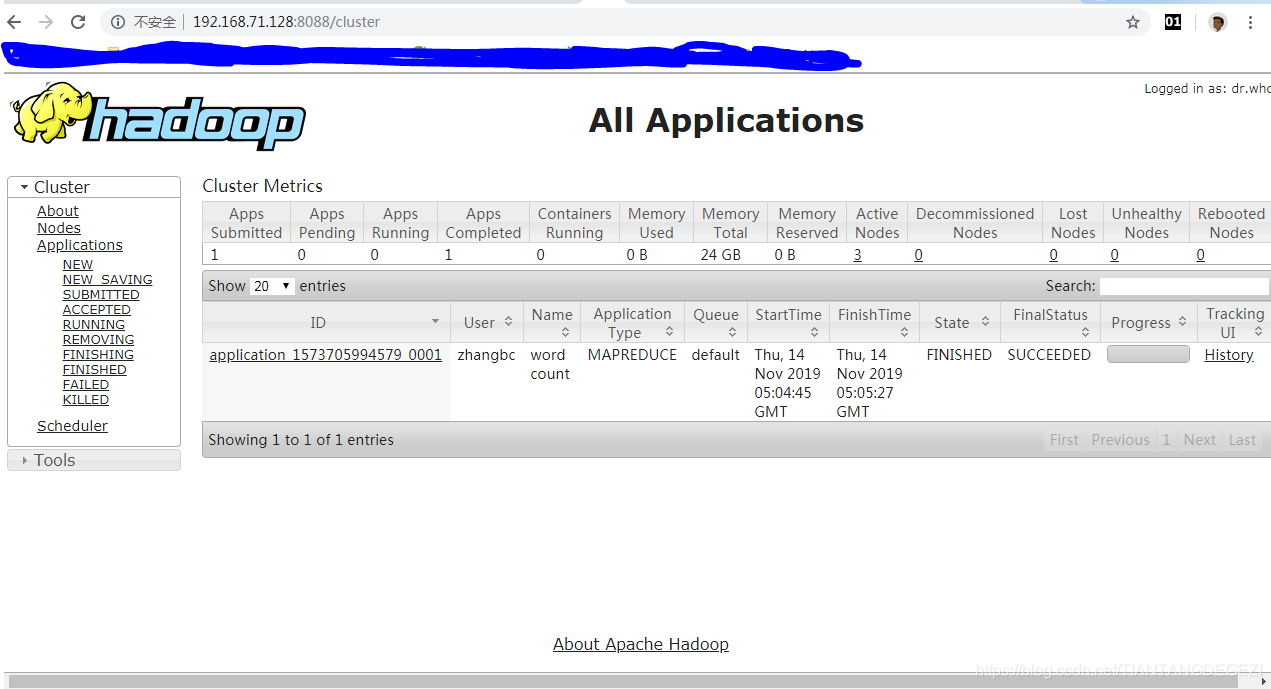
WEB验证:http://192.168.71.128:8088
- 管理
JobHistory Server
zhangbc@master:~$ mr-jobhistory-daemon.sh start historyserver
starting historyserver, logging to /home/zhangbc/hadoop2.2.0/logs/mapred-zhangbc-historyserver-master.out
zhangbc@master:~$ mr-jobhistory-daemon.sh stop historyserver
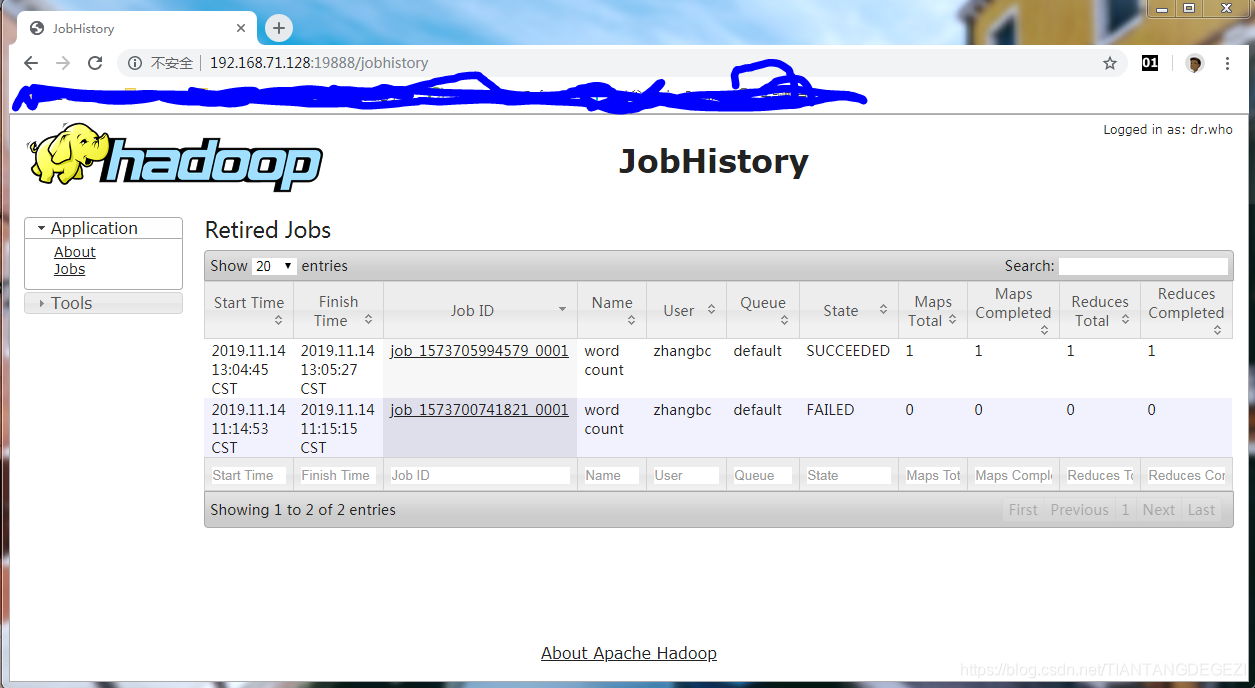
WEB验证:http://192.168.71.128:19888
- 集群验证
# 创建目录
zhangbc@master:~$ hdfs dfs -mkdir -p /data/wordscount
zhangbc@master:~$ hdfs dfs -mkdir -p /output
# 查看数据目录
zhangbc@master:~$ hdfs dfs -ls /data
# 上传本地文件
zhangbc@master:~$ hdfs dfs -put hadoop2.2.0/etc/hadoop/core-site.xml /data/wordscount
# 执行
zhangbc@master:~$ hadoop jar hadoop2.2.0/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.2.0.jar wordcount /data/wordscount /output/wordscount
...............................
19/11/14 13:04:45 INFO mapreduce.Job: The url to track the job: http://master:8088/proxy/application_1573705994579_0001/
19/11/14 13:04:45 INFO mapreduce.Job: Running job: job_1573705994579_0001
19/11/14 13:04:59 INFO mapreduce.Job: Job job_1573705994579_0001 running in uber mode : false
19/11/14 13:04:59 INFO mapreduce.Job: map 0% reduce 0%
19/11/14 13:05:14 INFO mapreduce.Job: map 100% reduce 0%
19/11/14 13:05:27 INFO mapreduce.Job: map 100% reduce 100%
19/11/14 13:05:27 INFO mapreduce.Job: Job job_1573705994579_0001 completed successfully
19/11/14 13:05:27 INFO mapreduce.Job: Counters: 43
............................................
# 查看运行结果
zhangbc@master:~$ hdfs dfs -cat /output/wordscount/part-r-00000
六,安装过程中遇到的问题及其解决方案
- 问题1:上传文件报错
zhangbc@master:~$ hdfs dfs -put hadoop2.2.0/etc/hadoop/core-site.xml /data/wordcount
19/11/14 10:13:24 WARN hdfs.DFSClient: DataStreamer Exception
org.apache.hadoop.ipc.RemoteException(java.io.IOExcept、ion): File /data/wordcount/core-site.xml._COPYING_ could only be replicated to 0 nodes instead of minReplication (=1). There are 0 datanode(s) running and no node(s) are excluded in this operation.
at org.apache.hadoop.hdfs.server.blockmanagement.BlockManager.chooseTarget(BlockManager.java:1384)
at org.apache.hadoop.hdfs.server.namenode.FSNamesystem.getAdditionalBlock(FSNamesystem.java:2477)
at org.apache.hadoop.hdfs.server.namenode.NameNodeRpcServer.addBlock(NameNodeRpcServer.java:555)
at org.apache.hadoop.hdfs.protocolPB.ClientNamenodeProtocolServerSideTranslatorPB.addBlock(ClientNamenodeProtocolServerSideTranslatorPB.java:387)
at org.apache.hadoop.hdfs.protocol.proto.ClientNamenodeProtocolProtos$ClientNamenodeProtocol$2.callBlockingMethod(ClientNamenodeProtocolProtos.java:59582)
at org.apache.hadoop.ipc.ProtobufRpcEngine$Server$ProtoBufRpcInvoker.call(ProtobufRpcEngine.java:585)
at org.apache.hadoop.ipc.RPC$Server.call(RPC.java:928)
at org.apache.hadoop.ipc.Server$Handler$1.run(Server.java:2048)
at org.apache.hadoop.ipc.Server$Handler$1.run(Server.java:2044)
at java.security.AccessController.doPrivileged(Native Method)
at javax.security.auth.Subject.doAs(Subject.java:415)
at org.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:1491)
at org.apache.hadoop.ipc.Server$Handler.run(Server.java:2042)
at org.apache.hadoop.ipc.Client.call(Client.java:1347)
at org.apache.hadoop.ipc.Client.call(Client.java:1300)
at org.apache.hadoop.ipc.ProtobufRpcEngine$Invoker.invoke(ProtobufRpcEngine.java:206)
at com.sun.proxy.$Proxy9.addBlock(Unknown Source)
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:57)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
at java.lang.reflect.Method.invoke(Method.java:606)
at org.apache.hadoop.io.retry.RetryInvocationHandler.invokeMethod(RetryInvocationHandler.java:186)
at org.apache.hadoop.io.retry.RetryInvocationHandler.invoke(RetryInvocationHandler.java:102)
at com.sun.proxy.$Proxy9.addBlock(Unknown Source)
at org.apache.hadoop.hdfs.protocolPB.ClientNamenodeProtocolTranslatorPB.addBlock(ClientNamenodeProtocolTranslatorPB.java:330)
at org.apache.hadoop.hdfs.DFSOutputStream$DataStreamer.locateFollowingBlock(DFSOutputStream.java:1226)
at org.apache.hadoop.hdfs.DFSOutputStream$DataStreamer.nextBlockOutputStream(DFSOutputStream.java:1078)
at org.apache.hadoop.hdfs.DFSOutputStream$DataStreamer.run(DFSOutputStream.java:514)
put: File /data/wordcount/core-site.xml._COPYING_ could only be replicated to 0 nodes instead of minReplication (=1). There are 0 datanode(s) running and no node(s) are excluded in this operation.
19/11/14 10:13:24 ERROR hdfs.DFSClient: Failed to close file /data/wordcount/core-site.xml._COPYING_
org.apache.hadoop.ipc.RemoteException(java.io.IOException): File /data/wordcount/core-site.xml._COPYING_ could only be replicated to 0 nodes instead of minReplication (=1). There are 0 datanode(s) running and no node(s) are excluded in this operation.
at org.apache.hadoop.hdfs.server.blockmanagement.BlockManager.chooseTarget(BlockManager.java:1384)
at org.apache.hadoop.hdfs.server.namenode.FSNamesystem.getAdditionalBlock(FSNamesystem.java:2477)
at org.apache.hadoop.hdfs.server.namenode.NameNodeRpcServer.addBlock(NameNodeRpcServer.java:555)
at org.apache.hadoop.hdfs.protocolPB.ClientNamenodeProtocolServerSideTranslatorPB.addBlock(ClientNamenodeProtocolServerSideTranslatorPB.java:387)
at org.apache.hadoop.hdfs.protocol.proto.ClientNamenodeProtocolProtos$ClientNamenodeProtocol$2.callBlockingMethod(ClientNamenodeProtocolProtos.java:59582)
at org.apache.hadoop.ipc.ProtobufRpcEngine$Server$ProtoBufRpcInvoker.call(ProtobufRpcEngine.java:585)
at org.apache.hadoop.ipc.RPC$Server.call(RPC.java:928)
at org.apache.hadoop.ipc.Server$Handler$1.run(Server.java:2048)
at org.apache.hadoop.ipc.Server$Handler$1.run(Server.java:2044)
at java.security.AccessController.doPrivileged(Native Method)
at javax.security.auth.Subject.doAs(Subject.java:415)
at org.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:1491)
at org.apache.hadoop.ipc.Server$Handler.run(Server.java:2042)
at org.apache.hadoop.ipc.Client.call(Client.java:1347)
at org.apache.hadoop.ipc.Client.call(Client.java:1300)
at org.apache.hadoop.ipc.ProtobufRpcEngine$Invoker.invoke(ProtobufRpcEngine.java:206)
at com.sun.proxy.$Proxy9.addBlock(Unknown Source)
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:57)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
at java.lang.reflect.Method.invoke(Method.java:606)
at org.apache.hadoop.io.retry.RetryInvocationHandler.invokeMethod(RetryInvocationHandler.java:186)
at org.apache.hadoop.io.retry.RetryInvocationHandler.invoke(RetryInvocationHandler.java:102)
at com.sun.proxy.$Proxy9.addBlock(Unknown Source)
at org.apache.hadoop.hdfs.protocolPB.ClientNamenodeProtocolTranslatorPB.addBlock(ClientNamenodeProtocolTranslatorPB.java:330)
at org.apache.hadoop.hdfs.DFSOutputStream$DataStreamer.locateFollowingBlock(DFSOutputStream.java:1226)
at org.apache.hadoop.hdfs.DFSOutputStream$DataStreamer.nextBlockOutputStream(DFSOutputStream.java:1078)
at org.apache.hadoop.hdfs.DFSOutputStream$DataStreamer.run(DFSOutputStream.java:514)
主要原因是重新格式化文件系统,导致master节点下的hadoop2.2.0/hdfs/name/current/VERSION中的clusterID和Slave节点下的hadoop2.2.0/hdfs/data/current/VERSION中的clusterID不一致。在浏览器输入master:50070可以发现Live Nodes为0。
解决方案是修改master节点下的clusterID使之与Slave节点下的clusterID一致,然后重启服务即可。
- 问题2:执行
JAR报错问题
Container launch failed for container_1573700741821_0001_01_000007 : java.lang.IllegalArgumentException: Does not contain a valid host:port authority: slave_1:33775
主要原因:Hadoop nodemanager结点主机名不能带下划线_。
解决方案:修改主机名称。
- 问题3:绑定主机名引起的问题:
sudo: unable to resolve host master
解决方案如下:
➜ ~ sudo vi /etc/hosts
1 127.0.0.1 localhost
2 127.0.1.1 ubuntu
3 127.0.1.1 master
:wq!
通过本次实验,对集群概念有个基本的认识,在搭建过程中遇到问题不算太多,主要是对局域网组建缺乏认识深度,本集群环境可以进一步扩展,如动态增减节点,借助Zookeeper技术加以融合等在企业中是比较常见的做法。
PS:如果你觉得文章对你有所帮助,别忘了推荐或者分享,因为有你的支持,才是我续写下篇的动力和源泉!
出处: http://www.cnblogs.com/zhangbc/
格言: 我愿意做一只蜗牛,慢慢地向前爬,不退缩,不泄气,做好自己,立足当下,展望未来!
本文版权归作者和博客园共有,欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出原文连接,否则保留追究法律责任的权利。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号