

【转】Directx11 SDK文档
原文地址:http://blog.csdn.net/cmt100/article/details/6343274
总结
这是一个初步的教程。我们将通过必要的步骤来创建一个Win32 Application。我们创建一个空白的窗口为DirectX 11做准备。
创建窗口
每一个窗口应用程序需要至少一个窗口对象。甚至在开始获得DirectX 11的诸多细节之前,我们的Application必须要有一个工作着的窗口。我们有三个事情要做:
1.注册一个窗口类
WNDCLASSEX wcex;
wcex.cbSize = sizeof(WNDCLASSEX);
wcex.style = CS_HREDRAW | CS_VREDRAW;
wcex.lpfnWndProc = WndProc;
wcex.cbClsExtra = 0;
wcex.cbWndExtra = 0;
wcex.hInstance = hInstance;
wcex.hIcon = LoadIcon(hInstance, (LPCTSTR)IDI_TUTORIAL1);//这个是资源图标,需要资源载入
wcex.hCursor = LoadCursor(NULL, IDC_ARROW);
wcex.hbrBackground = (HBRUSH)(COLOR_WINDOW+1);
wcex.lpszMenuName = NULL;
wcex.lpszClassName = szWindowClass;
wcex.hIconSm = LoadIcon(wcex.hInstance, (LPCTSTR)IDI_TUTORIAL1);
if( !RegisterClassEx(&wcex) )
return FALSE;
2.创建一个窗口对象
g_hInst = hInstance; // 用全局变量来保存应用程序实例句柄
RECT rc = { 0, 0, 640, 480 };
AdjustWindowRect( &rc, WS_OVERLAPPEDWINDOW, FALSE );//根据窗口风格,以rc为客户区调整整个窗口大小
g_hWnd = CreateWindow( szWindowClass, L"Direct3D 11 Tutorial 0: Setting Up Window",
WS_OVERLAPPEDWINDOW,
CW_USEDEFAULT, CW_USEDEFAULT,
rc.right - rc.left, rc.bottom - rc.top,
NULL, NULL,
hInstance, NULL);
if( !g_hWnd )
return FALSE;
ShowWindow( g_hWnd, nCmdShow );
3.检索和调度这个窗口的消息队列的消息
MSG msg = {0};
while( GetMessage( &msg, NULL, 0, 0 ) {
TranslateMessage( &msg );
DispatchMessage( &msg );
}
LRESULT CALLBACK WndProc( HWND hWnd, UINT message, WPARAM wParam, LPARAM lParam ){
PAINTSTRUCT ps;
HDC hdc;
switch (message) {
case WM_PAINT:
hdc = BeginPaint(hWnd, &ps);
EndPaint(hWnd, &ps);
break;
case WM_DESTROY:
PostQuitMessage(0);
break;
default:
return DefWindowProc(hWnd, message, wParam, lParam);
}
return 0;
}
对于每个窗口应用程序,这是最少的步骤来创建一个窗口对象。如果我们编译运行这个代码,我们将看到一个空的白色背景的窗口。
总结
这是第一个教程,我们将通过必要的元素来创建一个小型的DirectX 11应用程序。每个DirectX 11应用程序必须拥有这些元素得以正常运转。这些元素包括创建一个窗口对象和设备对象,并且能够显示一种颜色的窗口。
创建DirectX 11 设备
创建窗口对象和消息循环请参见DirectX 11 SDK文档(一)。现在我们有一个能够显示的窗口,接下来我们能够创建Direct3D 11 设备。如果我们要渲染3D的场景,创建设备是必须的。第一件事要做的就是创建以下三个对象:device,immediate context,swap chain。immediate context在Direct3D 11 是一个新的对象。
在Direct3D 10中device对象被用来渲染场景和创建资源。在Direct3D 11中immediate context被应用程序用来将场景渲染到缓冲区里,而device有很多创建资源的函数。
swap chain负责交换device渲染的场景所存放缓冲区,并且能够将要显示的内容呈现在屏幕上。swap chain将包含两个或更多的缓冲区,主要包含前景缓冲区和背景缓冲区。前景缓冲区就是用户当前在屏幕上所看到的。前景缓冲区是只读,并且不能被修改。背景缓冲区就是device所渲染场景的目标位置。一旦完成了绘制操作,swap chain通过交换两个缓冲区将背景缓冲区的内容呈现在屏幕上。这时背景缓冲区变成了前景缓冲区,而前景缓冲区变成了背景缓冲区。
为了创建swap chain,我们填充一个DXGI_SWAPCHAIN_DESC结构体,DXGI_SWAPCHAIN_DESC结构体描述了我们要创建swap chain的对象属性。DXGI_SWAPCHAIN_DESC结构体的变量虽然多,但是我们只要关心一小部分就可以了。BackBufferUsage标记应用程序将如何使用背景缓冲区。在这个例子中,我们要渲染这个背景缓冲区,所以我们将BackBufferUsage赋值为DXGI_USAGE_RENDER_TARGET_OUTPUT。OutputWindow代表窗口,该窗口是swap chain将图像呈现的区域。SampleDesc用来支持多采样,既然这个例子备没有使用多采样,所以将SampleDesc.Count=1,SampleDesc.Quality=0。
一旦DXGI_SWAPCHAIN_DESC结构体被填好,我们就可以调用D3D11CreateDeviceAndSwapChain()函数为我们创建device 和 swap chain。代码如下:
DXGI_SWAP_CHAIN_DESC sd;
ZeroMemory( &sd, sizeof(sd) );
sd.BufferCount = 1;
sd.BufferDesc.Width = 640;
sd.BufferDesc.Height = 480;
sd.BufferDesc.Format = DXGI_FORMAT_R8G8B8A8_UNORM;
sd.BufferDesc.RefreshRate.Numerator = 60;
sd.BufferDesc.RefreshRate.Denominator = 1;
sd.BufferUsage = DXGI_USAGE_RENDER_TARGET_OUTPUT;
sd.OutputWindow = g_hWnd;
sd.SampleDesc.Count = 1;
sd.SampleDesc.Quality = 0;
sd.Windowed = TRUE;
if( FAILED( D3D11CreateDeviceAndSwapChain( NULL, D3D_DRIVER_TYPE_HARDWARE,
NULL, 0, featureLevels, numFeatureLevels,
D3D11_SDK_VERSION, &sd, &g_pSwapChain, &g_pd3dDevice,
NULL, &g_pImmediateContext ) ) ){
return FALSE;
}
接下来我们需要创建一个render target view,它在Direct3D 11是resource view的一种类型。在特定的阶段,resource view允许一个资源受graphics pipeline绑定。resource views是C中声明的类型,是一个大块的raw memory将应用于任何的数据类型。我们能够在resource views中将大块的raw memory用于定义一个整数数组,一个浮点数数组,一个结构体,一个结构体数组,等等。如果我们不知道raw memory的数据类型,那么它对我们来讲是没有用处的。Direct3D 11的resource views与之类似。目前为止,一个2D的纹理保存方式与raw memory类似,也是一个潜在的raw resource。一旦我们有了这个资源,我们就可以在graphics pipeline的不同阶段创建不同的resource views,数据格式类型如下:作为渲染目标,作为深度模板缓冲区来接受深度信息,或者作为纹理资源。在C中的声明中允许一个内存块以不同的方式使用,resource views也是如此。
我们需要创建一个render target view,因为我们需要将它绑定到swap chain后背缓冲区,作为渲染目标。所以Direct3D 11能够将渲染的场景写入缓冲区。我们可以调用GetBuffer()函数来获得背景缓冲区对象。选择性的,我们可以选择填充一个描述render target view的D3D11_RENDERTARGETVIEW_DESC结构体来创建render target view。这个描述通常是CreateRenderTargetView()函数的第二个参数。然而,在这个教程,创建一个默认的render target view就够了,所以第二个参数传NULL。一旦我们创建了默认的render target view,我们就可以调用immediate context对象的OMSetRenderTargets()函数,就可以将render target view绑定到pipeline。这个确保了pipeline渲染的场景内容输出到背景缓冲区。代码如下:
ID3D11Texture2D *pBackBuffer;
if( FAILED( g_pSwapChain->GetBuffer( 0, __uuidof( ID3D11Texture2D ), (LPVOID*)&pBackBuffer ) ) )
return FALSE;
hr = g_pd3dDevice->CreateRenderTargetView( pBackBuffer, NULL, &g_pRenderTargetView );
pBackBuffer->Release();
if( FAILED( hr ) )
return FALSE;
g_pImmediateContext->OMSetRenderTargets( 1, &g_pRenderTargetView, NULL );
最后,在Direct3D能够渲染之前,我们需要初始化一下视图。这个视图用于映射空间坐标系。这个视图的X,Y在[-1,1],Z在[0,1]
用于渲染目标空间,有时就是所谓的像素空间。在Direct3D 9中,如果应用程序没有设置视图,就会默认一个和渲染目标大小相等的视图。在Direct3D 11中没有默认的视图,所以我们必须想在屏幕上看到东西之前设置视图。既然我们要使用整个渲染目标作为输出,我们设置左上角的点是(0,0),并且宽高设置成与渲染目标相等。代码如下:
D3D11_VIEWPORT vp;
vp.Width = (FLOAT)width;
vp.Height = (FLOAT)height;
vp.MinDepth = 0.0f;
vp.MaxDepth = 1.0f;
vp.TopLeftX = 0;
vp.TopLeftY = 0;
g_pImmediateContext->RSSetViewports( 1, &vp );
修改消息循环
我们已经创建了窗口和Direct3D 11 device,并且我们为渲染做好了准备。然而,在我们的消息循环代码里仍然有个问题:它使用 GetMessage()函数来获取消息。如果应用程序窗口的消息队列内没有消息,GetMessage()函数阻塞程序不会返回,直到消息队列内有消息。以至于在消息队列为空的时候我们的应用程序不得不等待,在此期间我们不能进行渲染操作。我们可以用PeekMessage()函数来代替GetMessage()来解决这个问题。PeekMessage()检索消息的操作与GetMessage()一样,但是当消息队列内没有消息时不会等待,而是直接返回。我们可以利用这个时间来做一些渲染操作。代码修改如下:
MSG msg = {0};
while( WM_QUIT != msg.message ){
if( PeekMessage( &msg, NULL, 0, 0, PM_REMOVE ) ){
TranslateMessage( &msg );
DispatchMessage( &msg );
}else{
Render(); // Do some rendering
}
}
渲染代码
渲染操作将在Render()函数中被执行,在这个教程中,我们尽可能渲染一个最简单的场景,该场景就是将窗口用一种颜色填充。在Direct3D 11 中,有一种很简单的办法,我们可以调用immediate context对象中ClearRenderTargetView()方法将渲染目标填充成一种颜色。第一,我们要定义一个长度为四的浮点数组来表示填充在屏幕上的颜色。Present()函数负责把swap chain中背景缓冲区的内容显示在屏幕上,以至于我们能看到。代码如下:
void Render()
{
//
// Clear the backbuffer
//
float ClearColor[4] = { 0.0f, 0.125f, 0.6f, 1.0f }; // RGBA
g_pImmediateContext->ClearRenderTargetView( g_pRenderTargetView, ClearColor );
g_pSwapChain->Present( 0, 0 );
}

总结
在前面的教程中,我们创建了一个小型的,能够显示单颜色的窗口的Direct3D 11应用程序。在这个教程中,我们将扩展这个应用程序将一个三角形显示在屏幕上,我们将贯穿这个过程来创建关于三角形的数据结构。效果如上图。
三角形的元素
一个三角形由三个点组成,也可以叫做顶点。用一个顶点数组来定义一个三角形,为了GPU能够渲染这个三角形,我们必须告诉GPU三角形的三个顶点的坐标。以2D为例,对我们来讲很容易就可以渲染一个像图1那样的三角形。我们要向GPU传送三个顶点(0,0),(0,1),(1,0),这样GPU有足够的信息来渲染我们想要的三角形。

所以,我们现在知道我们必须传三个顶点坐标给GUP来渲染一个三角形。那我们要如何传这些信息给GPU呢?在Direct3D 11中,向顶点信息(如坐标)叫保存在一个缓冲区资源内。如果一个缓冲区用来存放顶点信息,那么它就叫做顶点缓冲区。我们必须创建一个足够大的顶点缓冲区来保存者三个顶点坐标。在Direct3D 11中,创建一个顶点缓冲区必须指定大小(以byte为单位)。我们知道这个缓冲区有足够的空间来存放这个顶点,但是每个顶点有多少byte呢?回答好这个问题之前,我们需要知道顶点格式。
Input Layout
一个顶点有一个坐标信息。但通常不仅仅只有顶点信息,它也可能有其他的属性。比如:向量,多个的颜色,纹理坐标等等。顶点格式将定义这些属性在内存中如何存放:每个数据属性的用法,每个数据属性的大小,还有属性之间的排列。由于属性通常有不同的类型,类似于C中的结构体,一个顶点通常用一个结构体表示。可以方便地根据一个结构体的大小来获取顶点的大小。
在这个教程中,我们只使用到坐标信息,所以我们的顶点结构体只声明一个XMFLOAT3,XMFLOAT3由三个浮点数组成,它的典型应用就是3D内表示坐标。
struct SimpleVertex{
XMFLOAT3 Pos; // Position
};
现在我们有一个结构体来表示我们的顶点。在应用程序中要保存好这些顶点信息。然而,当我们需要GPU渲染包含这些顶点的顶点缓冲区的时候,我们要将它填入一个内存块中。GPU也必须知道顶点格式,以便于从缓冲区中提取顶点信息。完成这个需要了解input layout。
在Direct3D 11中,input layout是Direct3D对象,它能以一种GPU能够理解的方式来描述顶点结构体。每个顶点属性能够用D3D11_INPUT_ELEMENT_DESC结构体来描述。一个应用程序定义一个或多个的D3D11_INPUT_ELEMENT_DESC 结构体数组。使用这些数组来创建input layout对象来描述顶点。D3D11_INPUT_ELEMENT_DESC结构体细节如下:
|
SemanticName |
Semantic Name是一个用来描述属性的字符串。这个字符串表示一个单词,这个单词可以使用C能够定义的任何格式。目前对于描述position属性的一个好的Semantic Name是POSITION。Semantic Name不区分大小写。 |
|
SemanticIndex |
Semantic Index补充Semantic Name。一个顶点可能有多个属性是一样的。比如:有两组纹理坐标或者有两组颜色,用数字来代替Semantic Name的使用,比如:”COLOR0”和”COLOR1”。这两个元素可以共享一个Semantic Name—“COLOR”,使用0和1这两个不同的索引。 |
|
Format |
元素使用Format定义了数据类型。目前,DXGI_FORMAT_R32G32B32_FLOAT数据格式有3个32位的浮点数,使这个元素有12字节大小。DXGI_FORMAT_R16G16B16A16_UINT有4个16字节无符号整型数,使这个元素8字节大小。 |
|
InputSlot |
根据以前的方法,一个Direct3D 11应用程序通过使用顶点缓冲区的方式把顶点数据传给GPU,Direct3D 11在中,多种顶点缓冲区能够同时被传入GPU,确切的说是16种。每种顶点缓冲区将有一个数值在[0,15]绑定到Input slot。这个InputSlot告诉GPU可以从哪个顶点缓冲区获取这个元素。 |
|
AlignedByteOffset |
一个顶点保存在一个顶点缓冲区中,这个顶点缓冲区是一块连续的内存。AlignedByteOffset告诉GPU偏移量来获取这个元素。 |
|
InputSlotClass |
这个通常保存有D3D11_INPUT_PER_VERTEX_DATA。当一个应用程序使用Instancing时,它能够设置一个input layout的InputSlotClass到D3D11_INPUT_PER_INSTANCE_DATA与包含实例数据的顶点缓冲区一起工作,Instancing是一个超前的Direct3D话题,并且不会这里做深入讨论。对于我们的教程,我们将专门使用D3D11_INPUT_PER_VERTEX_DATA。 |
|
InstanceDataStepRate |
这个用于Instancing,既然我们没有使用Instancing,InstanceDataStepRate没有被用到,所以必须设置为0 |
现在我们能够定义我们的D3D11_INPUT_ELEMENT_DESC数组并且创建input layout:
// Define the input layout
D3D11_INPUT_ELEMENT_DESC layout[] ={
{ "POSITION", 0, DXGI_FORMAT_R32G32B32_FLOAT, 0, 0, D3D11_INPUT_PER_VERTEX_DATA, 0 },
};
UINT numElements = ARRAYSIZE(layout);
顶点格式
在下一个教程,我们将解释这个技术对象和渲染器。现在,我们把注意力集中在创建Direct3D 11顶点格式对象。然而,我们将了解到顶点渲染器将紧密地跟顶点格式联系在一起。原因在于创建一个顶点格式对象需要顶点渲染器的输入签名,我们将使用D3DX11CompileFromFile函数所返回的ID3DBlob对象来检索二进制数据,该二进制数据代表顶点渲染器的输入签名。一旦我们获得这个数据,我们就能够调用ID3D11Device::CreateInputLayout()函数来创建顶点格式对象,和调用ID3D11DeviceContext::IASetInputLayout()来激活这个顶点格式。代码如下:
// Create the input layout
if( FAILED( g_pd3dDevice->CreateInputLayout( layout, numElements, pVSBlob->GetBufferPointer(),
pVSBlob->GetBufferSize(), &g_pVertexLayout ) ) )
return FALSE;
// Set the input layout
g_pImmediateContext->IASetInputLayout( g_pVertexLayout );
创建顶点缓冲区
还有一件事在初始化时候要做的是创建顶点缓冲区保存顶点数据。在Direct3D 11中,为了创建一个顶点缓冲区,我们要填充两个结构体D3D11_BUFFER_DESC和D3D11_SUBRESOURCE_DATA,然后调用ID3D11Device::CreateBuffer()函数。D3D11_BUFFER_DESC描述要创建的顶点缓冲区对象。在顶点缓冲区创建的时候,D3D11_SUBRESOURCE_DATA描述在将要复制到顶点缓冲区的实际数据。顶点缓冲区在创建的时候初始化,所以之后我们就不要再初始化。将要复制到顶点缓冲区的数据是顶点数组,是3个SimpleVertex结构体的数组,顶点数组中坐标的选择是为了让三角形能显示在窗口的中央。顶点缓冲区创建之后,我们可以调用ID3D11DeviceContext::IASetVertexBuffers()将它绑定到device上。代码如下:
// Create vertex buffer
SimpleVertex vertices[] ={
XMFLOAT3( 0.0f, 0.5f, 0.5f ),
XMFLOAT3( 0.5f, -0.5f, 0.5f ),
XMFLOAT3( -0.5f, -0.5f, 0.5f ),
};
D3D11_BUFFER_DESC bd;
ZeroMemory( &bd, sizeof(bd) );
bd.Usage = D3D11_USAGE_DEFAULT;
bd.ByteWidth = sizeof( SimpleVertex ) * 3;
bd.BindFlags = D3D11_BIND_VERTEX_BUFFER;
bd.CPUAccessFlags = 0;
bd.MiscFlags = 0;
D3D11_SUBRESOURCE_DATA InitData;
ZeroMemory( &InitData, sizeof(InitData) );
InitData.pSysMem = vertices;
if( FAILED( g_pd3dDevice->CreateBuffer( &bd, &InitData, &g_pVertexBuffer ) ) )
return FALSE;
// Set vertex buffer
UINT stride = sizeof( SimpleVertex );
UINT offset = 0;
g_pImmediateContext->IASetVertexBuffers( 0, 1, &g_pVertexBuffer, &stride, &offset );
Primitive Topology
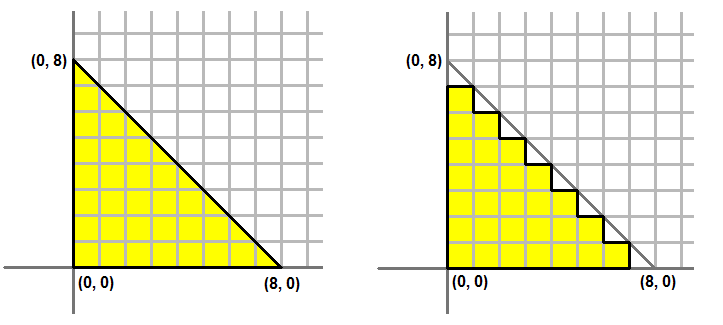
Primitive Topology是关于GPU如何获得要渲染三角形的3个顶点。我们上面讨论的都是如何让渲染一个简单三角形,应用程序需要传送这个3个顶点给GPU。所以,顶点缓冲区保存有3个顶点信息。那如果我们想要渲染两个三角形,该如何做呢?一种办法就是向GPU发送6个顶点。前3个顶点定义第一个三角形,后三个顶点定义第二个三角形,这个Topology叫做三角形列。三角形列是比较好理解的,当然它并不高效。这些例子能够成功地渲染三角形。目前为止图3a显示了一个矩形由两个三角形组成:ABC和CBD(按照惯例,以顺时针的顺序依次组成三角形列)。如果我们以三角形列的方式发送这两个三角形给GPU。我们的顶点应该这样定义:
A B C C B D
注意:B和C在顶点缓冲区中出现了两次,因为他们分别被两个三角形使用。

我们能够使顶点缓冲区更小,如果告诉GPU在渲染第二个三角形的时候,重复使用第一个三角形的最后两个顶点,然后再加上接下来的一个顶点组成第二个三角形。Direct3D支持这种格式,它叫做三角形带。当渲染一个三角形带时,第一个三角形由顶点数组的前三个顶点定义,那个接下来的三角形由前一个三角形的最后两个顶点和接下来的一个顶点定义。那么顶点应该这样定义:
A B C D
前三个顶点,即A B C定义第一个三角形。第二个三角形由B C(第一个三角形的最后两个顶点)加上D来定义。那个通过使用三角带,我们的顶点缓冲区从之前的6个顶点缩小为现在的4个顶点。
同理如图3b,使用三角列的话,顶点定义如下:ABC CBD CDE
如果使用三角带的话,顶点定义如下:A B C D E
你可能会注意到三角带的例子中,第二个三角形是由B C D来定义,这三个顶点的排列不是顺时针方向。使用三角形带时这是很正常的现象。这种现象只出现在第二个三角形,第四个三角形,第六个三角形,第八个三角形等等。这就确保了每个三角形的顶点都能够绕顺时针方向(顺时针,在这个例子中)。除了三角形列和三角形带,还有其他一些Direct3D支持的Primitive Topology,在这个教程上不做讨论。
在我们的代码里,我们只需要一个三角形,所以我们用三角形列还是三角形带都可以。但是它必须定义,所以我们使用三角形列。
// Set primitive topology
g_pImmediateContext->IASetPrimitiveTopology( D3D11_PRIMITIVE_TOPOLOGY_TRIANGLELIST );
渲染三角形
最后的代码就是如何渲染这个三角形。我们已经创建了两个渲染器用于渲染,顶点渲染器和像素渲染器。顶点渲染器负责将三角形的各个顶点变换到正确的位置。像素渲染器负责三角形内部的最后输出颜色的计算。这个将在下一个教程详细讲解。为了使用这两个渲染器,我们必须分别调用ID3D11DeviceContext::VSSetShader()函数和ID3D11DeviceContext::PSSetShader()函数。最后我们要做的就是调用ID3D11DeviceContext::Draw()函数,该函数命令GPU使用当前的顶点缓冲区,当前的顶点格式,当前的primitive topology进行渲染。Draw()的第一个参数要传给GPU的顶点个数。第二个参数表示顶点缓冲区的起始索引。因为我们要渲染一个三角形,并且我们从顶点缓冲区的0位置开始。我们分别用3和0来填充这两个参数。代码如下:
// Render a triangle
g_pImmediateContext->VSSetShader( g_pVertexShader, NULL, 0 );
g_pImmediateContext->PSSetShader( g_pPixelShader, NULL, 0 );
g_pImmediateContext->Draw( 3, 0 );

总结
在前面的教程中,我们创建了顶点缓冲区,并且传送了一个三角形的数据给GPU渲染。现在,我们通过graphics pipeline来看看,它每个步骤是怎么工作的。渲染器的概念,对系统的影响将被一一解释。
Graphics Pipeline
在前面的教程中,我们创建了顶点缓冲区,并且我们将顶点格式和顶点渲染器联系在一起。现在,我们将解释渲染器是如何工作的。为了全面了解这些渲染器,我们将回到之前的一些步骤,来看看Graphics Pipeline整个的工作。
在DirectX 11 SDK文档(三)中,当我们调用了VSSetShader()函数和PSSetShader()函数,我们可以将渲染器绑定到Pipeline的一个阶段。然后,当我们可以调用Draw()函数时,我们开始传送顶点数据给Graphics Pipeline。接下来的内容将介绍调用Draw()函数之后的细节。
渲染器
在Direct3D 11中,渲染器出现在Graphics Pipeline的不同阶段。他们是简短的代码,被GPU执行,传送特定的数据,然后将结果输出到Graphics Pipeline的下一个阶段。Direct3D 11支持三种基本的渲染器:顶点渲染器,几何渲染器,像素渲染器。顶点渲染器以顶点为输入,它每次处理从顶点缓冲区传给GPU的一个顶点信息。几何渲染器以图元为输入,它每次处理传给GPU的一个图元。一个图元是一个点,一条线,或者一个三角形。像素渲染器是以像素作为输入,它每次处理一个图元的每个像素。集合顶点渲染器,几何渲染器,像素渲染器就是所有绘制动作的实体。当用Direct3D 11渲染的时候,GPU已经就有了可用的顶点渲染器和像素渲染器。几何渲染器是Direct3D 11 的优越的特性,也是可选的。所以我们不会再这个教程讨论几何渲染器。在Direct3D 11中,还有hull渲染器和domain渲染器,compute渲染器。想知道更多的信息,请查看其他教程。
顶点渲染器
顶点渲染器是一段简短的代码,由GPU执行,处理顶点信息。可以把顶点渲染器看做是C语言中的一个函数,以顶点信息为输入,处理每个顶点,然后输出处理过的顶点。在应用程序把顶点缓冲区内的顶点信息传送给GPU之后,GPU将迭代处理这个顶点缓冲区,并且执行激活的顶点渲染器处理每个顶点,传送顶点数据给顶点渲染器作为输入参数。
当然顶点渲染器可以用来做很多的工作,但最重要的就是Transformation。Transformation就是把向量从一个坐标系转换到另一个坐标系。比如在3D场景中的一个三角形由三个顶点(0,0,0)(1,0,0)(0,1,0)。当这个三角形需要绘制2D纹理时,GPU必须知道每个顶点的纹理坐标。Transformation就是做这项工作。Transformation将在下一个教程进行详细的讨论。在这个教程中,我们只是使用一个简单的顶点渲染器只做了三角形顶点数据的处理。
在Direct3D 11教程里,我们将以HLSL高级语言来时用我们的渲染器。回收我们3D坐标的顶点信息,并且不会处理它。顶点渲染器代码如下:
float4 VS(float4 Pos : POSITION) : SV_POSITION{
return Pos;
}
这个顶点渲染器看起来想C语言的函数。HLSL使用类似C语法,对C/C++了解后,学习HLSL更容易。我们可以看到顶点渲染器,名字叫做VS,以float4为参数,返回值为float4。在HLSL中,float4是又4个浮点数组成的。那个冒号后面定义的是参数的semantics,返回值也是如此。就像之前提到的,semantics在HLSL中描述的是数据的属性。在上面的渲染器中,我们选择POSITION作为输入参数Pos的semantics,因为这个参数包含了顶点坐标信息。返回的semantics是SV_POSITION。SV_POSITION是事先已经定义好的semantics。这个semantics告诉graphics pipeline这个数据是定义clip-space坐标。GPU为了能在屏幕上画像素,必须知道坐标信息。(我们将在下一个教程讨论clip-space)。在我们的渲染器中,我们使用输入的坐标信息,处理后输出了相同的坐标信息给pipeline。
像素渲染器
现代计算机的显示器通常显示速度很快,屏幕的最小单位就是像素。每个像素都有一个颜色,并且每个像素相互独立。当我们要在屏幕上渲染一个三角形时,我们并不是把整个三角形当做一个实体来画。其实是,我们把三角形区域的像素绘制出来。
将三角形的三个顶点所覆盖的一串像素绘制出来的操作叫做光栅化。GPU首先要判断哪些像素被三角形区域覆盖。然后GPU调用激活的像素渲染器渲染这些像素。一个像素渲染器的主要目标就是计算每个像素的颜色。渲染器根据输入来计算顶点颜色,或者,如果没有使用几何渲染器,就像在这个教程中,像素渲染器的输入将直接来自顶点渲染器的输出。
上面我们所创建的顶点渲染器输出一个float4(semantics 为SV_POSITION),这个将是像素渲染器的输入。当像素渲染器输出颜色值,像素渲染器的输出也将是float4。我们给出这个输出(semantics 为SV_TARGET)也意味着目标的数据格式。像素渲染器代码如下:
float4 PS( float4 Pos:SV_POSITION):SV_Tatget{
return float4(1.0f,1.0f,0.0f,1.0f);
}
创建渲染器
在应用程序代码中,我们将创建一个顶点渲染器和一个像素渲染器对象。这些对象来代表我们的渲染器,它们将有调用D3DX11CompileFromFile()函数来创建。代码如下:
// Create the vertex shader
if( FAILED( D3DX11CompileFromFile( "Tutorial03.fx", NULL, NULL, "VS", "vs_4_0", D3DCOMPILE_ENABLE_STRICTNESS, NULL, NULL, &pVSBlob, &pErrorBlob, NULL ) ) )
return FALSE;
// Create the pixel shader
if( FAILED( D3DX11CompileFromFile( "Tutorial03.fx", NULL, NULL, "PS", "ps_4_0", D3DCOMPILE_ENABLE_STRICTNESS, NULL, NULL, &pPSBlob, &pErrorBlob, NULL ) ) )
return FALSE;
综述
通过对graphics pipeline的讲解,我们开始了解我们所创建的三角形的渲染过程。创建一个Direct3D的应用程序需要两个截然不同的两个步骤。第一,我们要在顶点数据创建源数据。第二,我们创建能为渲染转换数据的渲染器。
总结
在前面的教程中,我们成功地在应用程序窗口的中央绘制了一个三角形,我们没有吧注意力集中在顶点缓冲区里的坐标信息。在这个教程中,我们将详细描述3D坐标和Transformation。
3D空间
在前面的教程中,我们很明智地把三个顶点信息放置在屏幕上。然而,不具有一般性。那么,我们需要一个系统来表示在3D空间中的对象和一个系统将他们显示出来。
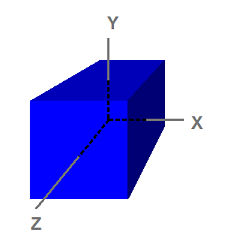
在现实世界里,对象存在于3D空间内。那就意味着,要将一个对象放置在一个特定的位置时,我们需要一个坐标系统,定义三个坐标轴来定义一个位置。在计算机图形学中,3D空间使用的是卡迪尔坐标系。在这个坐标系统中,有X,Y,Z三个坐标轴,并互相垂直,可以表示3D空间的任意点。这个坐标系统有两种表现形式,左手坐标系或者右手坐标系。如图:

既然我们讨论的3D空间的坐标系。一个点在3D空间的不同位置,将会有不同的坐标。以1D为例,假设我们有一把尺子,并且我们在上面标记了点P,P点在5英寸处。现在,如果我们把尺子向右平移1英寸,那么对于P点,现在变成了在4英寸处。通过移动尺子,这个参考系就发生了变化。所以,点并没有移动,它只是参考系变了。如图:

在3D中,一个空间由一个原点和X,Y,Z三个坐标轴定义。在计算机图形学中,使用几个空间坐标系:对象空间,世界空间,观察空间,投影空间,屏幕空间。如图:

对象空间
注意到这个立方体是以原点为中心,对象空间也叫模型空间,美工在制作模型的时候就是使用对象空间。美工在制作模型的时候,通常以对象空间的原点为中心,以便于进行变换:比如旋转模型。在我们讨论Transformation的时候将会看到。以下是八个顶点:
(-1, 1, -1)
( 1, 1, -1)
(-1, -1, -1)
( 1, -1, -1)
(-1, 1, 1)
( 1, 1, 1)
(-1, -1, 1)
( 1, -1, 1)
因为对象空间是美工创建和制作模型的典型应用,所模型所保存的顶点坐标信息都是相对于对象空间。一个应用程序能够创建一个顶点缓冲区来表示一个模型,并用模型数据来初始化这个缓冲区。所以顶点缓冲区的顶点坐标也是相对于对象空间来说。也就意味着顶点渲染器所接收到的顶点都是相对于对象空间。
世界空间
在一个场景中,所有对象将共享一个世界空间。它通常用来表示要渲染的对象之间的空间关系。想象一下这个世界空间,我们可以想象我们站在一个矩形空间的西南角,并面向北面。我们定义我们所站的这个角是坐标原点(0,0,0)。X轴指向我们的右边,Y轴指向我们的上面,Z轴指向我们的前面(即我们所面向的方向)。当我们做好这些,这个空间里的每个点都可以用XYZ坐标轴定义。现在,可能有一张椅子在我们前面5步,右手边2步的位置。可能有一盏灯在椅子上面8步高的位置。那么我们就可以知道椅子的坐标是(2,0,5),灯的坐标为(2,8,5)。正如我们所看到的,在世界中,对象之间的空间关系就用世界空间把他们联系起来。
观察空间
观察空间,有时也叫摄像机空间,跟世界空格键类似,是场景的典型应用。然而,在观察空间中,原点是观察者或者摄像机。摄像机所看到的方向定义为Z轴。应用程序定义了Y轴的正方向为摄像机向上的方向。如图所示:

左图显示了一个场景,该场景由一个像小人的对象和观察者组成,观察者正观察这个对象。红色部分表示使用世界空间的原点和坐标轴。右图显示观察空间和世界空间的关系。蓝色部分表示使用观察空间的坐标系。为了更清楚的说明插图,观察空间的坐标系于世界空间的坐标系有明显的不同。注意到观察空间中,观察者所朝着的方向是Z轴正方向。
投影空间
投影空间是用来将观察空间中的对象进行投影变换。在这个空间里,可见的范围是X,Y在[-1,1],Z在[0,1]。
屏幕空间
屏幕空间经常指帧缓存的位置。因为帧缓存通常是2D的纹理,所以屏幕空间是一个2D空间,左上角表示屏幕坐标原点。X水平向右,Y轴垂直向下。对于一个缓冲来说,它有w像素宽,h像素高。
空间到空间的转换
Transformation是指将顶点从一个空间到另一个空间的转换。在3D计算机图形学中,在pipeline中有3个逻辑转换:世界变换,观察变换,投影变换。每个变换操作如:平移,旋转,缩放将在下一个教程讲解。
世界变换
世界变换,顾名思义,将顶点从对象空间变换到世界空间。它通常包括一个或者多个的缩放,旋转,平移操作来变换对象,当然这些变换要根据我们要给的,大小,方向,位置信息。每个对象在场景中都有它自己的世界变换矩阵。因为每个对象都有自己的大小,方向和位置。
观察变换
在所有顶点都变换到世界空间后,世界变换将这些顶点从世界空间变换到观察空间。以观察者的视角来观察世界空间出现的对象。在观察空间,观察者在坐标系原点,观察方向为Z轴正方向。
以观察者的参考系来观察世界空间没有什么价值。观察变换矩阵是作用于顶点,而不是观察者。所以,当我对观察者进行变换时,观察变换矩阵执行相反的变换。比如,如果我们要观察者沿着Z轴的负方向移动5个单位,观察变换矩阵则被计算成沿着Z轴正方向移动5个单位。虽然摄像机向后移动,但是相对于观察者而言,顶点向前移动。在XNA Math中一个很方便地函数叫XMMatrixLookAtLH()经常被用来计算观察矩阵。我们只要告诉它观察者的位置,观察方向,观察者向上的方向来获取观察变换矩阵。
投影变换
投影变换将顶点从3D空间(比如世界空间和观察空间)变换到投影空间。在投影空间,顶点的X,Y坐标通过3D空间中的X/Z和Y/Z的比来计算。如图:

在3D空间中,所有事物出现在视角以内。也就是说近大远小。众所周知,一棵树的顶端h单位高,d单位远,还有一棵树2h单位高,2d单位远,那么观察者将看到两棵树的顶点重合。所以,顶点出现在屏幕上的位置可以根据X/Z和Y/Z来计算。
在参数中有一个用于顶点3D空间中可见的区域,它叫FOV。当朝着特定的方向看的时候,FOV表示根据对象特定的位置判断它是否可见。人又能在前面所能看到的FOV(我们看不到我我们背面的东西),并且我们看不到太近,或者太远的东西。在计算机图形学中,FOV包含一个平截体,在3D中,这个平截体由6个平面定义。在6个平面中的2个跟XY平面平行,这两个分别叫near-Z和far-Z平面。如图:
GPU过滤掉平截体外面的对象,所以不会花时间去渲染不会显示的图像。这个操作叫做裁剪。平截体的四个面像被割掉头的金字塔。根据体积进行裁剪是非常复杂的,GPU必须将每个顶点跟平截体的六个平面进行计算。换个角度,GPU一般先进行投影变换,然后再根据平截体裁剪。投影变换的效果就是将金字塔形的平截体转换成一个盒子。这是因为,正如前面提到的,在投影空间中X,Y坐标分别是根据X/Z和Y/Z计算出来的。所以点a和点b在投影空间中将是同一个点,正是这个原因平截体变成了一个盒子。
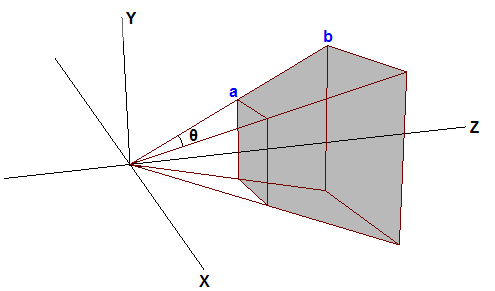
想象一下两棵树的顶点在平截体的顶部边缘,假设d = 2h。那么在投影空间中,Y轴的坐标沿着ab这条线将都是0.5(因为h/d=0.5)。所以顶点的Y坐标在投影变换后大于0.5则被GPU裁剪掉。对于不同的平截体将会有不同的裁剪结果。为了使这个操作更方便,3D程序一般缩放投射的X,Y大小是它们能在[-1,1]内。换句话说,任意的X或Y的坐标在[-1,1]区间之外,将被裁剪掉。为了让它按计划工作,投影矩阵必须缩放投射过来的X,Y坐标(通过将它们乘上h/d,或者d/h),d/h也是FOV一半的余切。经过缩放,平截体的头部将变成 h/d*d/h = 1。任何顶点经过投影变换后的X,Y坐标大于1的将被GPU裁剪掉。这就是我们想要的。
在投影空间中Z轴坐标也有相同的操作。在投影空间中我们更喜欢将Z坐标控制在[0,1]。在3D空间中,当Z=near-Z时,在投影空间中,Z=0;当Z=far-Z时,投影空间中,Z=1.当这个操作好之后,所有的Z值在[0,1]之外的将被GPU裁剪掉。
在Direct3D 11中,获取投影矩阵对简单的方法就是调用XMMatrixPerspectiveFovLH()方法。我们只要提供四个参数--FOVy,Aspect,Zn,Zf,函数返回一个矩阵,能实现上面所提到的功能。FOVy是指在Y轴方向的视野,Aspect指渲染目标的宽高比,根据FOVy和Aspect就可以算出FOVx。Zn和Zf分别表示near-Z和far-Z。
使用变换
在前面的教程中,我们写了一段程序,将一个简单的三角形渲染在屏幕上。当我们创建顶点缓冲区时,顶点的坐标直接当做投影后的坐标来使用,以至于我们没有进行任何的变换。既然我们已经了解了3D空间和变换。我们将改写这个程序,顶点缓冲区保存的将是对象空间的顶点数据。然后,我们改写我们的顶点渲染器将顶点经过一系列的变换,从对象空间变换到投影空间。
改写顶点缓冲区
现在我们开始在三维空间定义对象,我们将前面的平面三角形改成一个立方体。这样更容易地展示这些概念。
SimpleVertex vertices[] = {
{ XMFLOAT3( -1.0f, 1.0f, -1.0f ), XMFLOAT4( 0.0f, 0.0f, 1.0f, 1.0f ) },
{ XMFLOAT3( 1.0f, 1.0f, -1.0f ), XMFLOAT4( 0.0f, 1.0f, 0.0f, 1.0f ) },
{ XMFLOAT3( 1.0f, 1.0f, 1.0f ), XMFLOAT4( 0.0f, 1.0f, 1.0f, 1.0f ) },
{ XMFLOAT3( -1.0f, 1.0f, 1.0f ), XMFLOAT4( 1.0f, 0.0f, 0.0f, 1.0f ) },
{ XMFLOAT3( -1.0f, -1.0f, -1.0f ), XMFLOAT4( 1.0f, 0.0f, 1.0f, 1.0f ) },
{ XMFLOAT3( 1.0f, -1.0f, -1.0f ), XMFLOAT4( 1.0f, 1.0f, 0.0f, 1.0f ) },
{ XMFLOAT3( 1.0f, -1.0f, 1.0f ), XMFLOAT4( 1.0f, 1.0f, 1.0f, 1.0f ) },
{ XMFLOAT3( -1.0f, -1.0f, 1.0f ), XMFLOAT4( 0.0f, 0.0f, 0.0f, 1.0f ) },
};
可能你会注意到,我们指定了立方体的8个顶点,但是我们并没有描述每个三角形。如果我们就这样把数据传进去,输出将不会是我们想要的结果。我们必须通过这8个点指定三角形来组成立方体。
在一个立方体上,会有许多的三角形共享同一个顶点。并且很多顶点会被重复地定义,这样会浪费内存空间。像这样的情况,我们有一个办法只要定义8个顶点就可以了,然后告诉Direct3D使用那些点来组成三角形。通过索引缓存可以实现。一个索引缓存包含一个链表,它保存的是顶点缓冲区的索引,用它来指定使用那些顶点来组成三角形。代码如下:
// Create index buffer
WORD indices[] = {
3,1,0,
2,1,3,
0,5,4,
1,5,0,
3,4,7,
0,4,3,
1,6,5,
2,6,1,
2,7,6,
3,7,2,
6,4,5,
7,4,6,
};
正如你所看到的,第一个三角形由点3,1,和0。这意味着第一个三角形的顶点分别在:( -1.0f, 1.0f, 1.0f ),( 1.0f, 1.0f, -1.0f ), and ( -1.0f, 1.0f, -1.0f ),一个立方体有6个面,每个面由3个三角形组成。那么我们将会看到这里定义了12个三角形。
既然每个顶点已经被明确定义了,并且没有任何两个三角形没有共享边缘,这是考虑到使用三角形列。总之,包含12个三角形的三角列,我们需要36个顶点。
顶点索引缓冲区的创建跟顶点缓冲区的创建类似。我们提供指定的参数,比如一个结构体包含大小和类型,然后创建缓冲区。这个类型是D3D11_BIND_INDEX_BUFFER。既然我们使用DWORD来申请数组,那我们用sizeof(DWORD)。
D3D11_BUFFER_DESC bd;
ZeroMemory( &bd, sizeof(bd) );
bd.Usage = D3D11_USAGE_DEFAULT;
bd.ByteWidth = sizeof( WORD ) * 36; // 36 vertices needed for 12 triangles in a triangle list
bd.BindFlags = D3D11_BIND_INDEX_BUFFER;
bd.CPUAccessFlags = 0;
bd.MiscFlags = 0;
InitData.pSysMem = indices;
if( FAILED( g_pd3dDevice->CreateBuffer( &bd, &InitData, &g_pIndexBuffer ) ) )
return FALSE;
一旦我们创建好缓冲区,我们就要去设置它,以至于Direct3D能知道如何去使用索引缓冲区来获得三角形。我们指定顶点的缓冲区,格式,和偏移量。代码如下:
// Set index buffer
g_pImmediateContext->IASetIndexBuffer( g_pIndexBuffer, DXGI_FORMAT_R16_UINT, 0 );
改写顶点渲染器
在前面教程中的顶点渲染器,我们以顶点坐标为输入,以相同的顶点坐标为输出,没有进行任何的修改。我们能够完成这个是因为输入的顶点坐标已经被定义在投影空间内。现在,因为我们的顶点是被定义在对象空间。在顶点渲染器输出之前,必须对顶点进行变换。我们需要3个步骤:将对象空间转换到世界空间,然后转换到观察空间,最后转换到投影空间。我们第一件事要做的是申请静态的缓冲变量。静态缓冲区用来保存应用程序需要传入渲染器的数据。在渲染之前,应用程序通常将重要的数据写入静态缓冲区,并且在渲染数据期间西欧哪个渲染器中可以获取这些数据。在一个FX文件中,静态缓冲变量就像C++结构体中的全局变量。我们要用的者3个变量分别是世界矩阵,观察矩阵,投影矩阵,在HLSL中,他们的数据类型为matrix。
一旦我们清楚了我们所需要的矩阵,我们利用这些矩阵里运行顶点渲染器来处理输入的坐标数据。一个向量将被矩阵中多个向量变换。在HLSL,通过使用内置函数mul()。代码如下:
cbuffer ConstantBuffer : register( b0 ){
matrix World;
matrix View;
matrix Projection;
}
//
// Vertex Shader
//
VS_OUTPUT VS( float4 Pos : POSITION, float4 Color : COLOR ){
VS_OUTPUT output = (VS_OUTPUT)0;
output.Pos = mul( Pos, World );
output.Pos = mul( output.Pos, View );
output.Pos = mul( output.Pos, Projection );
output.Color = Color;
return output;
}
在这个顶点渲染器中,每个mul()函数应用一个变换作用于输入坐标。按顺序使用世界矩阵,观察矩阵,投影矩阵。这个顺序是固定的,不允许交换。
设置矩阵
通过使用这些矩阵,我们可以更新我们的顶点渲染器,但我们也需要在程序中定义这三个矩阵。在渲染的时候,这3个矩阵保存着我们需要使用的变换。在渲染之前,我们将这3个矩阵的值复制到渲染器的静态缓冲区。然后,通过调用Draw()来启动渲染,我们的顶点渲染器从静态缓冲区读出矩阵数据。除了这些矩阵,我们还需要一个ID3D11Buffer对象来表示静态缓冲区。代码如下:
ID3D11Buffer* g_pConstantBuffer = NULL;
XMMATRIX g_World;
XMMATRIX g_View;
XMMATRIX g_Projection;
为了创建ID3D11Buffer对象,我们使用ID3D11Device::CreateBuffer(),并指定 D3D11_BIND_CONSTANT_BUFFER。
D3D11_BUFFER_DESC bd;
ZeroMemory( &bd, sizeof(bd) );
bd.Usage = D3D11_USAGE_DEFAULT;
bd.ByteWidth = sizeof(ConstantBuffer);
bd.BindFlags = D3D11_BIND_CONSTANT_BUFFER;
bd.CPUAccessFlags = 0;
if( FAILED(g_pd3dDevice->CreateBuffer( &bd, NULL, &g_pConstantBuffer ) ) )
return hr;
接下来我们需要做的就是利用这3个矩阵进行变换。我们要让三角形设置在原点,并平行于XY平面。那么相对于对象空间,这些顶点要如何保存呢?所以世界变换不需要做任何事情,我们只需要把世界矩阵设置为单位矩阵即可。我们要设置摄像机的位置在(0,1,-5),看着(0,1,0)点,向上的向量为(0,1,0)。我们调用 XMMatrixLookAtLH()函数来方便地计算出观察矩阵。我们习惯Y轴的正方向为向上的方向。最后,计算投影矩阵,我们调用XMMatrixPerspectiveFovLH()函数,以90°的垂直视野(即pi/2),aspect宽高比为640/480,这个数据来自背景缓冲区的宽高。Zn=0.1,Zf=110,。这意味着任何事物力摄像机的距离小于0.1或者大于110将视为不可见。这三个矩阵分别保存在全局变量g_World, g_View, and g_Projection上。
更新静态缓冲区
我们已经有了这些矩阵,现在我们必须把这些数据写入静态缓冲区,以至于GPU进行渲染的时候能读到它。为了更新这个缓冲区,我们使用ID3D11DeviceContext::UpdateSubresource()函数,并传给它一个指向矩阵的指针,同样,传入指向静态缓冲区的指针。为了顺利地完成这个,我们创建一个包含于静态缓冲区同样格式的结构体。这是因为,矩阵在C++和HLSL的保存方式不一样。在更新之前,我们必须传送这些矩阵。
//
// Update variables
//
ConstantBuffer cb;
cb.mWorld = XMMatrixTranspose( g_World );
cb.mView = XMMatrixTranspose( g_View );
cb.mProjection = XMMatrixTranspose( g_Projection );
g_pImmediateContext->UpdateSubresource( g_pConstantBuffer, 0, NULL, &cb, 0, 0 );

总结
在前面的教程中,我们将模型空间中的立方体渲染到屏幕上。在这个教程中,我们将扩展变换的概念,并使用这些变换展示简单的动画。
变换
在3D图形学中,变换经常用来操作顶点和向量。也用来将一个对象从一个空间变换到另一个空间。变换能够能够用矩阵进行多种操作。这里有3个典型的原始变换:平移(与原点的位置关系),旋转(与X,Y,Z轴的方向关系),缩放(与原点的距离关系)。除此之外,投影变换是用来将对象从观察空间变换到投影空间。在XNA Math库中包含了这些API方便地创建应用于不同目的的变换矩阵,比如:平移,旋转,缩放,世界空间-观察空间变换,观察空间-投影空间变换等等。一个应用程序能够在场景中使用这些矩阵来变换顶点。我们需要了解基础的矩阵操作。接下来,我们来看看简要的例子。
平移
在空间中,平移指的是移动一定距离或取代当前位置。在3D中,下面的矩阵是用来平移
1 0 0 0
0 1 0 0
0 0 1 0
a b c 1
其中(a,b,c)包含方向和距离的向量用来移动,比如,将一个点沿着X轴负方向移动5个单位。则我们将有下面这个矩阵:
1 0 0 0
0 1 0 0
0 0 1 0
-5 0 0 1
如果我们将这个矩阵应用于一个中心在原定的立方体,运算的结果将是整个立方体想X轴负方向平移5个单位。如下图所示:

在3D中,一个空间一般由一个原点和X,Y,Z三个相互垂直的坐标轴定义。一下计算机图形学中使用几个空间与之类似:对象空间,世界空间,观察空间,投影空间,屏幕空间。下图是立方体的对象空间:
旋转
旋转是对顶点绕一个过原点的轴进行旋转。比如:X,Y,Z轴。举个例子,在2D世界中,点(1,0)沿顺时针旋转90°。那么旋转的结果就是点(0,1)。下面的矩阵使用来绕Y轴旋转 ΐ°。
cosΐ 0 -sinΐ 0
0 1 0 0
sinΐ 0 cosΐ 0
0 0 0 1
如下图,绕Y轴旋转45°

缩放
缩放是指将向量沿着一个轴的方向放到足够大,或缩到足够小。比如,一个向量能够按着所有方向放大或者只沿着X轴方向缩小。通用矩阵如下:
p 0 0 0
0 q 0 0
0 0 r 0
0 0 0 1
p,q,r分别为X,Y,Z轴方向的缩放比例。下图的效果是沿着X轴方向放大为原来的2倍,Y轴方向缩小为原来的0.5倍。

多重变换
为了对一个向量进行多重变换。我们可以简单的将一个一个的矩阵乘以向量。因为向量和多个矩阵的连乘具有结合性,我们可以把所有矩阵都先乘起来,然后再将向量乘以这个矩阵而得到最后的结果。下图是旋转和平移的变换结合之后对向量的作用结果:

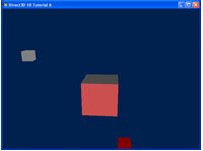
创建轨道
在这个教程,我们将变换两个立方体。第一个自转,二第二个绕着第一个转。这两个立方体都会有自己的世界变换矩阵,并且在每帧的渲染中都会使用到。
在XNA Math中,有一些函数帮助我们创建旋转,平移,缩放矩阵
1.旋转可以调用XMMatrixRotationX(), XMMatrixRotationY(), 和XMMatrixRotationZ()函数,来创建分别绕X,Y,Z轴旋转的矩阵。我们创建的选装矩阵只能绕这三个轴的其中一个旋转。至于绕任意轴旋转可以对这三个基本旋转进行复合计算而得到。
2.平移可以调用XMMatrixTranslation()函数,这个函数根据指定的参数创建一个矩阵来平移点。
3.缩放可以调用XMMatrixScaling()函数,它只能在X,Y,Z轴进行缩放。如果需要绕着任意轴缩放,可以设置多个适当角度的旋转矩阵,把它们跟缩放矩阵连乘来达到这种效果。
第一个立方体以一个点为中心进行公转。这个立方体使用世界变换矩阵惊醒沿着Y轴进行旋转。我们可以调用XMMatrixRotationY()函数,代码如下,这个立方体每帧只旋转一点。既然这个立方体能够持续旋转。每帧旋转的角度将以一定的速度变化。
// 1st Cube: Rotate around the origin
g_World1 = XMMatrixRotationY( t );
第二个立方体将绕着第一个矩阵旋转,为了展示多重变换,我们添加缩放比例和沿各自的轴旋转。公式表现在代码中,如下。第一个立方体将缩小为原来的0.3倍,并且它会绕着自己的轴进行旋转(在这个例子中,绕Z轴旋转)。为了模拟这个轨道,它将离原点有一定距离,并且轨道是绕Y轴旋转的结果。想实现这个效果必须依靠4个矩阵(mScale,mSpin,mTranslate,mOrbit)连乘的结果。
// 2nd Cube: Rotate around origin
XMMATRIX mSpin = XMMatrixRotationZ( -t );
XMMATRIX mOrbit = XMMatrixRotationY( -t * 2.0f );
XMMATRIX mTranslate = XMMatrixTranslation( -4.0f, 0.0f, 0.0f );
XMMATRIX mScale = XMMatrixScaling( 0.3f, 0.3f, 0.3f );
g_World2 = mScale * mSpin * mTranslate * mOrbit;
一个非常值得注意的就是:这些矩阵相乘的顺序是不能交换的。根据这个矩阵变换就可以看到这个结果。
// Update our time
t += XM_PI * 0.0125f;
在渲染之前,我们必须用更新渲染器中静态缓冲区。注意,每个立方体都有自己的世界矩阵,所以在绘制它们的时候要注意改变世界变换矩阵。
//
// Update variables for the first cube
//
ConstantBuffer cb1;
cb1.mWorld = XMMatrixTranspose( g_World1 );
cb1.mView = XMMatrixTranspose( g_View );
cb1.mProjection = XMMatrixTranspose( g_Projection );
g_pImmediateContext->UpdateSubresource( g_pConstantBuffer, 0, NULL, &cb1, 0, 0 );
//
// Render the first cube
//
g_pImmediateContext->VSSetShader( g_pVertexShader, NULL, 0 );
g_pImmediateContext->VSSetConstantBuffers( 0, 1, &g_pConstantBuffer );
g_pImmediateContext->PSSetShader( g_pPixelShader, NULL, 0 );
g_pImmediateContext->DrawIndexed( 36, 0, 0 );
//
// Update variables for the second cube
//
ConstantBuffer cb2;
cb2.mWorld = XMMatrixTranspose( g_World2 );
cb2.mView = XMMatrixTranspose( g_View );
cb2.mProjection = XMMatrixTranspose( g_Projection );
g_pImmediateContext->UpdateSubresource( g_pConstantBuffer, 0, NULL, &cb2, 0, 0 );
//
// Render the second cube
//
g_pImmediateContext->DrawIndexed( 36, 0, 0 );
深度缓存
深度缓存也是这个教程的一个看点。没有它的话,在比较小的轨道中,第二个立方体将总是绘制在第一个立方体的上面,即使当它旋转到第一个立方体的后面的时候。深度缓冲区允许Direct3D检测画在屏幕上每个像素的深度。在Direct3D 11中的默认操作是将要画的每个像素和已经在屏幕上的对应像素的深度进行比较。如果当前像素深度小于等于对应像素的深度,当前像素将覆盖原来的像素。另一方面,如果当前像素深度大于对应像素的深度,当前像素将被丢弃,原来像素保持不变。
下列代码创建一个深度缓冲区(一个深度模板)。它也是创建一个深度缓存DepthStencilView,以至于让Direct3D知道把它作为深度模板来用。
// Create depth stencil texture
D3D11_TEXTURE2D_DESC descDepth;
ZeroMemory( &descDepth, sizeof(descDepth) );
descDepth.Width = width;
descDepth.Height = height;
descDepth.MipLevels = 1;
descDepth.ArraySize = 1;
descDepth.Format = DXGI_FORMAT_D24_UNORM_S8_UINT;
descDepth.SampleDesc.Count = 1;
descDepth.SampleDesc.Quality = 0;
descDepth.Usage = D3D11_USAGE_DEFAULT;
descDepth.BindFlags = D3D11_BIND_DEPTH_STENCIL;
descDepth.CPUAccessFlags = 0;
descDepth.MiscFlags = 0;
hr = g_pd3dDevice->CreateTexture2D( &descDepth, NULL, &g_pDepthStencil );
if( FAILED(hr) )
return hr;
// Create the depth stencil view
D3D11_DEPTH_STENCIL_VIEW_DESC descDSV;
ZeroMemory( &descDSV, sizeof(descDSV) );
descDSV.Format = descDepth.Format;
descDSV.ViewDimension = D3D11_DSV_DIMENSION_TEXTURE2D;
descDSV.Texture2D.MipSlice = 0;
hr = g_pd3dDevice->CreateDepthStencilView( g_pDepthStencil, &descDSV, &g_pDepthStencilView );
if( FAILED(hr) )
return hr;
为了使用新创建的深度模板缓冲,这个教程必须把它绑定到device。我们可以调用OMSetRenderTargets(),把DepthStencilView当做参数传给这个函数。
g_pImmediateContext->OMSetRenderTargets( 1, &g_pRenderTargetView, g_pDepthStencilView );
与渲染目标类似,在渲染之前必须清空深度缓冲区。它确保之前的像素深度不会影响到当前帧的绘制,因为相对于当前帧,上一帧遗留的深度是无效的,必须被丢弃。代码如下:
//
// Clear the depth buffer to 1.0 (max depth)
//
g_pImmediateContext->ClearDepthStencilView( g_pDepthStencilView, D3D11_CLEAR_DEPTH, 1.0f, 0 );(注意这里SDK文档漏泄了,现在补上)
总结
在前面的教程中,这个世界看起来令人厌烦,因为所有的对象以同一种方式显示。在这个教程将介绍简单的光照概念,并介绍如何去应用它。这个技术是方向光。
光照
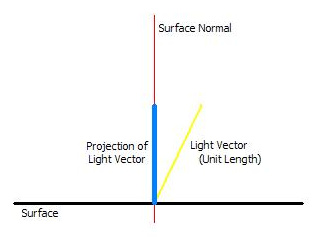
在这个教程中,将介绍最基础的光照类型是方向光。方向光不论对象跟光源的距离,都受到统一的关照。当光照到一个表面时,光照的发射计算这个表面和光线的夹角大小。当光线直接照射到表面时,表面会将所有的光反射回去,显示最高的强度。然而,随着表面与光线的角度增长,反射的光照强度会慢慢暗下来。
为了算出光线照射到表面的反射强度,光线的方向和表面的向量将被用来计算。这是表面的向量将被定义为垂直于表面的向量。这个计算只要把两个向量做一个简单的点乘就可以了,这个计算将返回光线在表面向量的投影的值。如果夹角比较大,那么投影就会比较小。那么这给我们一个正确的功能来调节扩散的光线。
在这个教程中所使用的光源是一种近似的方向光。光线的向量决定了光线的方向。既然说是近似,不论一个对象在哪里,光线的方向都是一样的。就比如太阳的光线。对于任何对象,受到的太阳的光照都是一样的。除此之外,照射在各个对象上将会有不同的光照强度。
还有其他一些光:点光,辐射光,和聚光。
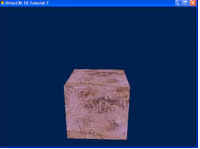
初始化光照
在这个教程中,有两个光源。一个放在立方体的前面向立方体照射,另一个以立方体为中心绕轨道移动。注意,轨道上的立方体用来表示光源的位置。
既然光照由渲染器计算,一些变量必须声明并绑定。在这个例子中,我们只需要光源的方向向量和它的颜色。第一个光源是灰色,第二个是红色。代码如下:
// Setup our lighting parameters
XMFLOAT4 vLightDirs[2] = {
XMFLOAT4( -0.577f, 0.577f, -0.577f, 1.0f ),
XMFLOAT4( 0.0f, 0.0f, -1.0f, 1.0f ),
};
XMFLOAT4 vLightColors[2] = {
XMFLOAT4( 0.5f, 0.5f, 0.5f, 1.0f ),
XMFLOAT4( 0.5f, 0.0f, 0.0f, 1.0f )
};
轨道中旋转的光源与上个教程中的立方体类似。用一个旋转矩阵来改变光源的方向,让这个光源总是向中心照射。注意,XMVector3Transform()函数用于计算向量和矩阵相乘。在前面的教程中,我们只是把多个变换矩阵进行相乘,得到世界变换矩阵,然后传给渲染器进行变换。然而,由于在这个例子中简单的缘故。实际上我们只对灯光做了世界变换。
// Rotate the second light around the origin
XMMATRIX mRotate = XMMatrixRotationY( -2.0f * t );
XMVECTOR vLightDir = XMLoadFloat4( &vLightDirs[1] );
vLightDir = XMVector3Transform( vLightDir, mRotate );
XMStoreFloat4( &vLightDirs[1], vLightDir );
像矩阵一样,把灯光的方向向量和颜色传给渲染器。相关的变量将会被设置,参数也会传进来。
//
// Update matrix variables and lighting variables
//
ConstantBuffer cb1;
cb1.mWorld = XMMatrixTranspose( g_World );
cb1.mView = XMMatrixTranspose( g_View );
cb1.mProjection = XMMatrixTranspose( g_Projection );
cb1.vLightDir[0] = vLightDirs[0];
cb1.vLightDir[1] = vLightDirs[1];
cb1.vLightColor[0] = vLightColors[0];
cb1.vLightColor[1] = vLightColors[1];
cb1.vOutputColor = XMFLOAT4(0, 0, 0, 0);
g_pImmediateContext->UpdateSubresource( g_pConstantBuffer, 0, NULL, &cb1, 0, 0 );
在像素渲染器中显然灯光
一旦我们准备好数据,并且渲染器准备好要读入的数据。我们就可以计算出方向光作用在每个像素的结果。之前我们使用的是点乘的方法。
一旦我们将向量与光线进行点乘,然后我们就可以把结果乘以颜色和光线算出光线作用的最后结果。这些值将通过saturate函数,这个函数将颜色值控制在[0,1]。结果就是两个光光照的效果叠加在一起,算出最后的颜色。
我们没有把表面的材质考虑进去,所以最后的计算结果就是光的颜色。
//
// Pixel Shader
//
float4 PS( PS_INPUT input) : SV_Target{
float4 finalColor = 0;
//do NdotL lighting for 2 lights
for(int i=0; i<2; i++){
finalColor += saturate( dot( (float3)vLightDir[i],input.Norm) * vLightColor[i] );
}
return finalColor;
}
经过像素渲染器的运算,像素的颜色受灯光调节。并且你可以看到每个灯光作用在表面的效果。必须注意的是,我们现在看到的像素显示都是平面的,因为像素在同一个平面上,并且有相同的法向量。对于计算机来讲,漫反射是一个非常简单的光照模型。你可以使用更复杂的模型来实现更丰富,更真实的效果。
总结
在前面的教程中,我们介绍了光照。现在我们为立方体添加纹理。我们将介绍静态缓存的概念,并解释如何使用缓存以最小的带宽来加快处理。
纹理映射
纹理映射是指2D纹理到3D几何模型的投影。我们可以认为它是一种包装。为了完成这项任务,我们不得不确定2D图像跟表面上顶点的关系。
这个立方体比较适合进行纹理坐标的设置。对于复杂的模型,手动地设置纹理坐标是比较困难的。那么,3D建模包一般会算出模型的每个顶点所对应的纹理坐标。既然我们的例子是立方体,那就比较容易地就可以设置所需要的纹理坐标。纹理坐标被定义在顶点,然后为表面上的每个像素进行插值运算。
创建渲染器的纹理资源和采样状态
纹理是来自文件的一张2D图像,并被用来创建一个shader-resource view,以至于它能从渲染器中读取。
hr = D3DX11CreateShaderResourceViewFromFile( g_pd3dDevice, L"seafloor.dds", NULL, NULL,
&g_pTextureRV, NULL );
我们也要创建一个采样状体来控制渲染器如何对纹理进行过滤,筛选,寻址。在这个教程中,我们启动采样状态并进行线性过滤和重叠寻址。为了创建采样状态,我们使用ID3D11Device::CreateSamplerState()函数。
// Create the sample state
D3D11_SAMPLER_DESC sampDesc;
ZeroMemory( &sampDesc, sizeof(sampDesc) );
sampDesc.Filter = D3D11_FILTER_MIN_MAG_MIP_LINEAR;
sampDesc.AddressU = D3D11_TEXTURE_ADDRESS_WRAP;
sampDesc.AddressV = D3D11_TEXTURE_ADDRESS_WRAP;
sampDesc.AddressW = D3D11_TEXTURE_ADDRESS_WRAP;
sampDesc.ComparisonFunc = D3D11_COMPARISON_NEVER;
sampDesc.MinLOD = 0;
sampDesc.MaxLOD = D3D11_FLOAT32_MAX;
hr = g_pd3dDevice->CreateSamplerState( &sampDesc, &g_pSamplerLinear );
定义坐标
在我们把图片映射到立方体之前,我们必须首先立方体每个顶点的纹理坐标。既然纹理能够以任意大小使用,纹理坐标系统将被控制在[0,1]。左上角的纹理坐标是(0,0),右下角的纹理坐标为(1,1)。
在这个例子中,我们使用整个纹理铺满立方体的每个面。这个定义鉴定清晰,没有任何混乱。然而,也完全有可能延展纹理来铺设立方体的六个面,虽然使用定义点更困难。纹理会出现伸展和扭曲。
第一,我们更新这个结构体来定义我们的包含纹理坐标的顶点。
struct SimpleVertex{
XMFLOAT3 Pos;
XMFLOAT2 Tex;
};
接下来,我们修改渲染器的input layout。
// Define the input layout
D3D11_INPUT_ELEMENT_DESC layout[] = {
{ "POSITION", 0, DXGI_FORMAT_R32G32B32_FLOAT, 0, 0, D3D11_INPUT_PER_VERTEX_DATA, 0 },
{ "TEXCOORD", 0, DXGI_FORMAT_R32G32_FLOAT, 0, 12, D3D11_INPUT_PER_VERTEX_DATA, 0 },
};
既然我们的input layout改变了,对应的顶点渲染器也必须修改
struct VS_INPUT{
float4 Pos : POSITION;
float2 Tex : TEXCOORD;
};
最后,我们把纹理坐标添加到顶点中。注意,第二个输入参数D3DXVECTOR2包含纹理坐标。立方体的每个顶点将对应一个纹理坐标。这个纹理映射的创建是把(0,0)(0,1)(1,0)或者(1,1)作为纹理坐标。
// Create vertex buffer
SimpleVertex vertices[] = {
{ XMFLOAT3( -1.0f, 1.0f, -1.0f ), XMFLOAT2( 0.0f, 0.0f ) },
{ XMFLOAT3( 1.0f, 1.0f, -1.0f ), XMFLOAT2( 1.0f, 0.0f ) },
{ XMFLOAT3( 1.0f, 1.0f, 1.0f ), XMFLOAT2( 1.0f, 1.0f ) },
{ XMFLOAT3( -1.0f, 1.0f, 1.0f ), XMFLOAT2( 0.0f, 1.0f ) },
{ XMFLOAT3( -1.0f, -1.0f, -1.0f ), XMFLOAT2( 0.0f, 0.0f ) },
{ XMFLOAT3( 1.0f, -1.0f, -1.0f ), XMFLOAT2( 1.0f, 0.0f ) },
{ XMFLOAT3( 1.0f, -1.0f, 1.0f ), XMFLOAT2( 1.0f, 1.0f ) },
{ XMFLOAT3( -1.0f, -1.0f, 1.0f ), XMFLOAT2( 0.0f, 1.0f ) },
{ XMFLOAT3( -1.0f, -1.0f, 1.0f ), XMFLOAT2( 0.0f, 0.0f ) },
{ XMFLOAT3( -1.0f, -1.0f, -1.0f ), XMFLOAT2( 1.0f, 0.0f ) },
{ XMFLOAT3( -1.0f, 1.0f, -1.0f ), XMFLOAT2( 1.0f, 1.0f ) },
{ XMFLOAT3( -1.0f, 1.0f, 1.0f ), XMFLOAT2( 0.0f, 1.0f ) },
{ XMFLOAT3( 1.0f, -1.0f, 1.0f ), XMFLOAT2( 0.0f, 0.0f ) },
{ XMFLOAT3( 1.0f, -1.0f, -1.0f ), XMFLOAT2( 1.0f, 0.0f ) },
{ XMFLOAT3( 1.0f, 1.0f, -1.0f ), XMFLOAT2( 1.0f, 1.0f ) },
{ XMFLOAT3( 1.0f, 1.0f, 1.0f ), XMFLOAT2( 0.0f, 1.0f ) },
{ XMFLOAT3( -1.0f, -1.0f, -1.0f ), XMFLOAT2( 0.0f, 0.0f ) },
{ XMFLOAT3( 1.0f, -1.0f, -1.0f ), XMFLOAT2( 1.0f, 0.0f ) },
{ XMFLOAT3( 1.0f, 1.0f, -1.0f ), XMFLOAT2( 1.0f, 1.0f ) },
{ XMFLOAT3( -1.0f, 1.0f, -1.0f ), XMFLOAT2( 0.0f, 1.0f ) },
{ XMFLOAT3( -1.0f, -1.0f, 1.0f ), XMFLOAT2( 0.0f, 0.0f ) },
{ XMFLOAT3( 1.0f, -1.0f, 1.0f ), XMFLOAT2( 1.0f, 0.0f ) },
{ XMFLOAT3( 1.0f, 1.0f, 1.0f ), XMFLOAT2( 1.0f, 1.0f ) },
{ XMFLOAT3( -1.0f, 1.0f, 1.0f ), XMFLOAT2( 0.0f, 1.0f ) },
};
当我们进行纹理采样的时候,我们需要受几何模型的材质的调节。
绑定纹理作为渲染器资源
一个纹理和采样状态都是对象,与静态缓存对象类似。在它们能够被渲染器使用之前,它们需要用ID3D11DeviceContext::PSSetSamplers()函数和ID3D11DeviceContext::PSSetShaderResources()函数进行设置。
g_pImmediateContext->PSSetShaderResources( 0, 1, &g_pTextureRV );
g_pImmediateContext->PSSetSamplers( 0, 1, &g_pSamplerLinear );
现在,渲染器可以使用纹理了。
使用纹理
为了将纹理映射到几何模型上,我们将在像素渲染器中调用纹理采样函数。Sample()函数将执行2D纹理的采样功能,并且能返回采样颜色。像素渲染器调用这个函数并且把它乘以模型的颜色(模型的材质),然后输出最后的颜色。
1.当我们将g_TextureRV绑定,txDiffuse是用来保存我们纹理的对象。
2.samLinear在下面描述,是一种纹理的采样模式。
3.当我们确定纹理资源的时候,input.Tex是纹理坐标。
// Pixel Shader
float4 PS( PS_INPUT input) : SV_Target{
return txDiffuse.Sample( samLinear, input.Tex ) * vMeshColor;
}
还有一件我们要记得去做的就是从顶点渲染器中传出纹理坐标。如果我们不这么做,当我们进入像素渲染器时将得不到这些数据。这里,我们只是复制输入的纹理坐标作为输出的纹理坐标,并让硬件来处理其他工作。
// Vertex Shader
PS_INPUT VS( VS_INPUT input ){
PS_INPUT output = (PS_INPUT)0;
output.Pos = mul( input.Pos, World );
output.Pos = mul( output.Pos, View );
output.Pos = mul( output.Pos, Projection );
output.Tex = input.Tex;
return output;
}
静态缓存
在Direct3D中,一个应用程序使用静态缓存来设置渲染器变量。静态缓存将使用类C的语法声明。静态缓存能够减少带宽来更新渲染器,它是通过将静态缓存放在一起,并能同时处理,而不是分开调用。
在前面的教程中,我们使用单一的静态缓存来保存我们需要的渲染器变量。但是最好,最高效的使用方法是用静态缓存来组织渲染器变量,因为他们经常被改动。这样就可以让应用程序以最小的宽带来更新渲染器变量。正如例子所示,这个教程用三个结构体组织变量:一个是每帧值都在改变的变量,一个是只有在窗口大小被改变时才改变的变量,一个是一旦被设置就无法改变的变量。代码如下:
cbuffer cbNeverChanges{
matrix View;
};
cbuffer cbChangeOnResize{
matrix Projection;
};
cbuffer cbChangesEveryFrame{
matrix World;
float4 vMeshColor;
};
为了跟静态缓存一起工作,你需要为每个创建一个ID3D11Buffer对象。然后调用ID3D11DeviceContext::UpdateSubresource()来更新每个静态缓存,而不影响其他静态缓存。
//
// Update variables that change once per frame
//
CBChangesEveryFrame cb;
cb.mWorld = XMMatrixTranspose( g_World );
cb.vMeshColor = g_vMeshColor;
g_pImmediateContext->UpdateSubresource( g_pCBChangesEveryFrame, 0, NULL, &cb, 0, 0 );
