三、python 常用算法,导入函数,函数可变长参数,占位符,装饰器
Python3 range() 函数返回的是一个可迭代对象(类型是对象),而不是列表类型, 所以打印的时候不会打印列表。
Python3 list() 函数是对象迭代器,可以把range()返回的可迭代对象转为一个列表,返回的变量类型为列表。
python装饰器就是用于拓展原来函数功能的一种函数,这个函数的特殊之处在于它的返回值也是一个函数,使用python装饰器的好处就是在不用更改原函数的代码前提下给函数增加新的功能。
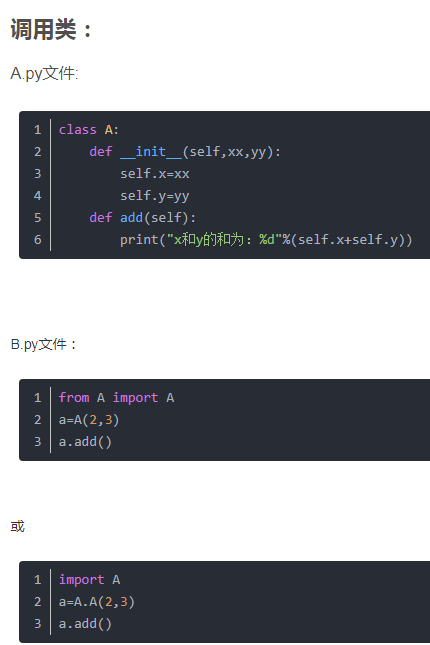
函数调用
在同一个文件下
import A
A.add(1,2)
或者
from A import add
add(1,2)
或者多层的时候,1.py 文件调用module里面的内容
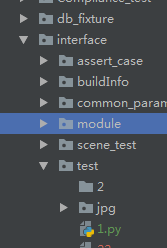
from interface.module.A import add
add(1,2)

Python中函数的参数传递与可变长参数
1.Python中也有像C++一样的默认缺省函数
1 def foo(text,num=0):
2 print text,num
3
4 foo("asd") #asd 0
5 foo("def",100) #def 100
定义有默认参数的函数时,这些默认值参数位置必须都在非默认值参数后面。
调用时提供默认值参数值时,使用提供的值,否则使用默认值。
2.Python可以根据参数名传参数
1 def foo(ip,port):
2 print "%s:%d" % (ip,port)
3
4 foo("192.168.1.0",3306) #192.168.1.0:3306
5 foo(port=8080,ip="127.0.0.1") #127.0.0.1:8080
第4行,没有指定参数名,按照顺序传参数。
第5行,指定参数名,可以按照参数名称传参数。
3.可变长度参数

1 #coding:utf-8 #设置python文件的编码为utf-8,这样就可以写入中文注释
2 def foo(arg1,*tupleArg,**dictArg):
3 print "arg1=",arg1 #formal_args
4 print "tupleArg=",tupleArg #()
5 print "dictArg=",dictArg #[]
6 foo("formal_args")
上面函数中的参数,tupleArg前面“*”表示这个参数是一个元组参数,从程序的输出可以看出,默认值为();dicrtArg前面有“**”表示这个字典参数(键值对参数)。可以把tupleArg、dictArg看成两个默认参数。多余的非关键字参数,函数调用时被放在元组参数tupleArg中;多余的关键字参数,函数调用时被放字典参数dictArg中。
下面是可变长参数的一些用法:
#coding:utf-8 #设置python文件的编码为utf-8,这样就可以写入中文注释
def foo(arg1,arg2="OK",*tupleArg,**dictArg):
print("arg1=",arg1)
print("arg2=",arg2)
for i,element in enumerate(tupleArg):
print("tupleArg %d-->%s" % (i,str(element)))
for key in dictArg:
print("dictArg %s-->%s" %(key,dictArg[key]))
myList=["my1","my2"]
myDict={"name":"Tom","age":22}
foo("formal_args",arg2="argSecond",a=1)
print("*"*40)
foo(123,myList,myDict)
print("*"*40)
foo(123,rt=123,*myList,**myDict)
输出为:

从上面的程序可以看出:
(1)如代码第16行。
参数中如果使用“*”元组参数或者“**”字典参数,这两种参数应该放在参数列表最后。并且“*”元组参数位于“**”字典参数之前。
关键字参数rt=123,因为函数foo(arg1,arg2="OK",*tupleArg,**dictArg)中没有rt参数,所以最后也归到字典参数中。
(2)如代码第14行。
元组对象前面如果不带“*”、字典对象如果前面不带“**”,则作为普通的对象传递参数。
多余的普通参数,在foo(123,myList,myDict)中,123赋给参数arg1,myList赋给参数arg2,多余的参数myDict默认为元组赋给myList。
多个实参,放到一个元组里面,以*开头,可以传多个参数;**是形参中按照关键字传值把多余的传值以字典的方式呈现
*args:(表示的就是将实参中按照位置传值,多出来的值都给args,且以元祖的方式呈现)
示例:
|
1
2
3
4
5
|
def foo(x,*args): print(x) print(args)foo(1,2,3,4,5)#其中的2,3,4,5都给了args |
执行结果是:
|
1
2
|
1(2, 3, 4, 5) |
当args与位置参数和默认参数混用的情况下:(注意三者的顺序)
示例一、(三者顺序是:位置参数、默认参数、*args)
|
1
2
3
4
5
6
|
def foo(x,y=1,*args): print(x) print(y) print(args)foo(1,2,3,4,5)#其中的x为1,y=1的值被2重置了,3,4,5都给了args |
执行结果是:
|
1
2
3
|
12(3, 4, 5) |
示例二、(三者顺序是:位置参数、*args、默认参数)
|
1
2
3
4
5
6
|
def foo(x,*args,y=1): print(x) print(args) print(y)foo(1,2,3,4,5)#其中的x为1,2,3,4,5都给了args,y按照默认参数依旧为1 |
执行结果是:
|
1
2
3
|
1(2, 3, 4, 5)1 |
其中关于*,可以从2个角度来看(需要拆分来看):
1、从形参的角度来看:
示例:
|
1
2
3
|
def foo(*args):#其实这一操作相当于def foo(a,b,c,d,e): print(args)foo(1,2,3,4,5)#其中的1,2,3,4,5都按照位置传值分别传给了a,b,c,d,e |
执行结果是:
|
1
|
(1, 2, 3, 4, 5) |
2、从实参的角度来看:
示例:
|
1
2
3
4
5
6
|
def foo(x,y,z): print(x) print(y) print(z) foo(*(1,2,3))#其中的*(1,2,3)拆开来看就是:foo(1,2,3),都按照位置传值分别传给了x,y,z |
执行结果是:
|
1
2
3
|
123 |
——————————————————————————————————————————————————————————————————————————————————————
**kwargs:(表示的就是形参中按照关键字传值把多余的传值以字典的方式呈现)
示例:
|
1
2
3
4
|
def foo(x,**kwargs): print(x) print(kwargs)foo(1,y=1,a=2,b=3,c=4)#将y=1,a=2,b=3,c=4以字典的方式给了kwargs |
执行结果是:
|
1
2
|
1{'y': 1, 'a': 2, 'b': 3, 'c': 4} |
关于**kwargs与位置参数、*args、默认参数混着用的问题:(注意顺序)
位置参数、*args、**kwargs三者的顺序必须是位置参数、*args、**kwargs,不然就会报错:
示例:
|
1
2
3
4
5
|
def foo(x,*args,**kwargs): print(x) print(args) print(kwargs)foo(1,2,3,4,y=1,a=2,b=3,c=4)#将1传给了x,将2,3,4以元组方式传给了args,y=1,a=2,b=3,c=4以字典的方式给了kwargs |
执行结果是:
|
1
2
3
|
1(2, 3, 4){'y': 1, 'a': 2, 'b': 3, 'c': 4} |
错误示例:(由于顺序错误)
|
1
2
3
4
5
|
def foo(x,**kwargs,*args): print(x) print(args) print(kwargs)foo(1,y=1,a=2,b=3,c=4,2,3,4) |
执行结果就会报错:
|
1
|
SyntaxError: invalid syntax |
位置参数、默认参数、**kwargs三者的顺序必须是位置参数、默认参数、**kwargs,不然就会报错:
示例:
|
1
2
3
4
5
|
def foo(x,y=1,**kwargs): print(x) print(y) print(kwargs)foo(1,a=2,b=3,c=4)#将1按照位置传值给x,y按照默认参数为1,a=2,b=3,c=4以字典的方式给了kwargs |
执行结果是:
|
1
2
3
|
11{'a': 2, 'b': 3, 'c': 4} |
其中关于**,可以从2个角度来看(需要拆分来看):
1、从形参的角度来看:
示例:
|
1
2
3
|
def foo(**kwargs):#其实就是相当于def foo(y,a,b,c) print(kwargs)foo(y=1,a=2,b=3,c=4) |
执行结果是:
|
1
|
{'y': 1, 'a': 2, 'b': 3, 'c': 4} |
2、从实参的角度来看:
示例一:
|
1
2
3
4
5
6
|
def foo(a,b,c,d): print(a) print(b) print(c) print(d)foo(**{"a":2,"b":3,"c":4,"d":5})#**{"a":2,"b":3,"c":4,"d":5}是将字典里的每个值按照关键字传值的方式传给a,b,c,d |
执行结果是:
|
1
2
3
4
|
2345 |
示例二:
|
1
2
3
4
5
6
|
def foo(a,b,c,d=1): print(a) print(b) print(c) print(d)foo(**{"a":2,"b":3,"c":4})#**{"a":2,"b":3,"c":4}是将字典里的每个值按照关键字传值的方式传给a,b,c;d依旧按照默认参数 |
执行结果是:
|
1
2
3
4
|
2341 |
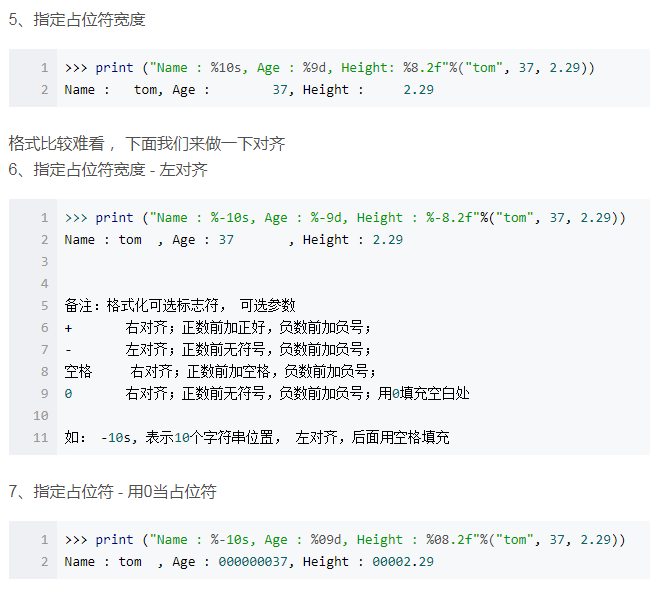
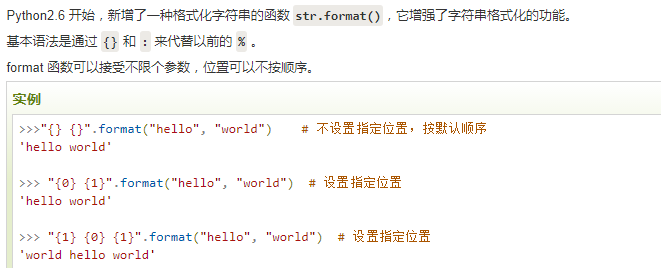
(%s%d)生成格式化的字符串,其中s是一个格式化字符串,d是一个十进制数

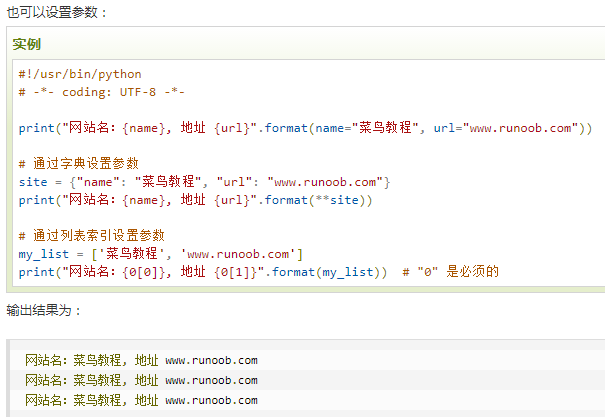
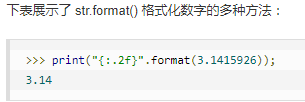
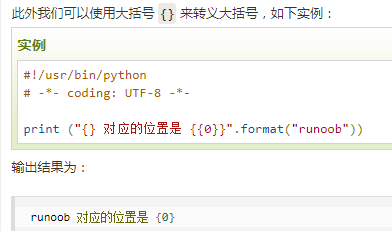



a = input('请输入')
list = []
for i in a:
list.append(i)
list.reverse() #调用reverse方法,将列表反转
'''
join():连接字符串数组。将字符串、元组、列表中的元素以指定的字符(分隔符)
连接生成一个新的字符串
'''
print (''.join(list)) #用 join()函数将list转换成字符串
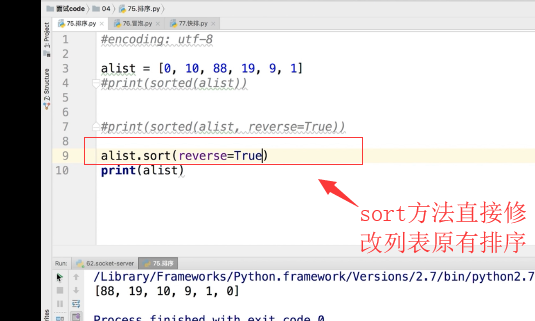
list.reverse()是直接将整个列表进行反转,不是排序
list.sort(reverse=True) 将列表从大到小排序
列表常用方法
# 列表常用方法
list = [1,3,2,4]
#len() 方法返回对象(字符、列表、元组等)长度或项目个数
count = len(list)
print(count)
# 列表切片
print(list[0:-1]) # 打印 [1, 2, 3]
print(list[2:]) # 打印[3,4]
print(list[-1]) # 打印 4
# 删除第三个元素
del list[2]
print(list)
# 把列表转换成字符串
# 方法1 使用join方法
#join()方法用于将序列中的元素以指定的字符连接生成一个新的字符串
li = [ "age","aa", "BB", "dd"]
v1=''.join(li)
print (v1) # 打印ageaaBBdd
li = [ "age","aa", "BB", "dd"]
v1='-'.join(li)
print (v1) # 打印age-aa-BB-dd
#方法2 循环遍历列表转换成str
li2 = [ "age","aa", "BB", "dd",10,12,13]
v3=''
for i in li2:
v3=v3 + str(i)
print(v3)

str = "abcpeeeb"
# type() 函数返回输入的变量类型
print(type(str)) # 打印<class 'str'>
#isinstance() 函数来判断一个对象是否是一个已知的类型,类似 type()
class A:
pass
class B(A):
pass
print(isinstance(A(), A)) # returns True
print(type(A())) == A # returns True
print(isinstance(B(), A)) # returns True
print(type(B()) == A ) # returns False
字符串常用方法
a = "33a bvdd3dd 33"
# strip()方法,去除字符串开头或者结尾的空格
# lstrip()方法,去除字符串开头的空格
# rstrip()方法,去除字符串结尾的空格
print(a.strip("3")) # 打印a bvdd3dd
print(a.lstrip("3")) # 打印a bvdd3dd 33
print(a.rstrip("3")) # 打印33a bvdd3dd
# replace('c1','c2'):把字符串里的c1替换成c2。故可以用replace(' ','')来去掉字符串里的所有空格
print(a.replace(" ","")) # 打印33abvdd3dd33
# String.split() 切割,返回列表 split[split] v.分裂,分开
print(a.split()) # 默认以空格为分割 打印['33a', 'bvdd3dd', '33']
print(a.split("v")) # 打印['33a b', 'dd3dd 33']
# join()方法+split()方法,可以去除全部空格
b = a.split()
print("".join(b)) # 打印 33abvdd3dd33
print("".join(a.split())) # 打印 33abvdd3dd33
# splitlines() 以换行为分割
str = 'hello,\nworld,\nhello'
print(str.splitlines()) # 打印 ['hello,', 'world,', 'hello']
# String.format() 输出指定的内容
user_show_name = 'hello,{name},welcome to here,do you like ,{name}'
print(user_show_name.format(name='yanyan'))
# String.format_map() 将字典中的参数传递进字符串中,输出
hello = "My name is {name},I am {age} years old.I like {hobby}"
# 使用format_map()方法来传递值
print(hello.format_map({'name':'yanyan','age':19,'hobby':'music travel'}))
# 补充,python中的字符串并不允许修改值,只允许覆盖值,或者进行replace替换

# 冒泡排序
# 方法1
list = [6,2,1,4,5,7,3]
count = len(list)
for i in range(0,count):
for j in range(i+1,count):
if list[i]>list[j]:
list[i],list[j] = list[j],list[i]
print(list)
# 方法2
list = [6,2,1,4,5,7,3]
count = len(list)-1
for i in range(count,0,-1): # 等同于for i in [6,5,4,3,2,1,0] :
for j in range(i):
if list[j] > list[j+1]:
list[j],list[j+1] = list[j+1],list[j]
print(list)
#快排
def QuickSort(myList,start,end):
#判断low是否小于high,如果为false,直接返回
if start < end:
i,j = start,end
#设置基准数
base = myList[i]
while i < j:
#如果列表后边的数,比基准数大或相等,则前移一位直到有比基准数小的数出现
while (i < j) and (myList[j] >= base):
j = j - 1
#如找到,则把第j个元素赋值给第个元素i,此时表中i,j个元素相等
myList[i] = myList[j]
#同样的方式比较前半区
while (i < j) and (myList[i] <= base):
i = i + 1
myList[j] = myList[i]
#做完第一轮比较之后,列表被分成了两个半区,并且i=j,需要将这个数设置回base
myList[i] = base
#递归前后半区
QuickSort(myList, start, i - 1)
QuickSort(myList, j + 1, end)
return myList
myList = [49,38,65,97,76,13,27,49]
print("Quick Sort: ")
QuickSort(myList,0,len(myList)-1)
print(myList)
堆排序
完全二叉树 概念 https://www.cnblogs.com/myjavascript/articles/4092746.html
堆排序算法 http://blog.51cto.com/me2xp/1973414
import math
def print_tree(array):
'''
深度 前空格 元素间空格
1 7 0
2 3 7
3 1 3
4 0 1
'''
index = 1
depth = math.ceil(math.log2(len(array))) # 因为补0了,不然应该是math.ceil(math.log2(len(array)+1))
sep = ' '
for i in range(depth):
offset = 2 ** i
print(sep * (2 ** (depth - i - 1) - 1), end='')
line = array[index:index + offset]
for j, x in enumerate(line):
print("{:>{}}".format(x, len(sep)), end='')
interval = 0 if i == 0 else 2 ** (depth - i) - 1
if j < len(line) - 1:
print(sep * interval, end='')
index += offset
print()
# print_tree([0, 30, 20, 80, 40, 50, 10, 60, 70, 90, 22])
# print_tree([0, 30, 20, 80, 40, 50, 10, 60, 70, 90, 22, 33, 44, 55, 66, 77])
# print_tree([0, 30, 20, 80, 40, 50, 10, 60, 70, 90, 22, 33, 44, 55, 66, 77, 88, 99, 11])
# 为了和编码对应,增加一个无用的0在首位
origin = [0, 30, 20, 80, 40, 50, 10, 60, 70, 90]
total = len(origin) - 1 # 初始待排序元素个数,即n
# print(origin)
print_tree(origin)
def heap_adjust(n, i, array: list):
'''
调整当前结点(核心算法)
调整的结点的起点在n//2,保证所有调整的结点都有孩子结点
:param n: 待比较数个数
:param i: 当前结点的下标
:param array: 待排序数据
:return: None
'''
while 2 * i <= n:
# 孩子结点判断 2i为左孩子,2i+1为右孩子
lchile_index = 2 * i
max_child_index = lchile_index # n=2i
if n > lchile_index and array[lchile_index + 1] > array[lchile_index]: # n>2i说明还有右孩子
max_child_index = lchile_index + 1 # n=2i+1
# 和子树的根结点比较
if array[max_child_index] > array[i]:
array[i], array[max_child_index] = array[max_child_index], array[i]
i = max_child_index # 被交换后,需要判断是否还需要调整
else:
break
# print_tree(array)
# heap_adjust(total, total // 2, origin)
# print(origin)
# print_tree(origin)
def max_heap(total,array:list):
for i in range(total//2,0,-1):
heap_adjust(total,i,array)
return array
print_tree(max_heap(total,origin))
def sort(total, array:list):
while total > 1:
array[1], array[total] = array[total], array[1] # 堆顶和最后一个结点交换
total -= 1
if total == 2 and array[total] >= array[total-1]:
break
heap_adjust(total,1,array)
return array
print_tree(sort(total,origin))
二分查找又称折半查找,binary search,是一种效率较高的查找方法。
'''
__Author__:Bao
功能:二分查找-方法1
'''
def binary_search(array,num):
'''
二分查找
'''
num_list.sort()
print(num_list)
left,right = 0,len(array)-1
while left <= right:
mid = (left + right) // 2
if array[mid] > num :
right = mid - 1
elif array[mid] < num :
left = mid + 1
else:
return "待查元素{0}在列表中位置是:{1}" .format(num,mid)
return "待查元素%d不在列表中" %num
if __name__ == '__main__':
num_list = [0,34, 6, 78, 9, 23, 56, 177, 33, 2, 6, 30, 99, 83, 21, 17]
print(binary_search(num_list,177))
"""
__Author__ : Bao
功能 : 二分查找-方法2
"""
def binarySearch(mylist,item):
mylist.sort()
left,right = 0, len(mylist)
while left < right:
mid = int((left+right)/2)
if mylist[mid] == item:
return "待查元素{item}在列表中位置是:{mid}" .format(item=item,mid=mid)
elif mylist[mid] > item:
right = mid
else:
left = mid + 1
return '待查找元素%s不存在指定列表中' %mid
mylist=[1,3,5,7,9,11,13,15]
B=binarySearch(mylist,15)
print(B)
"""
__Author__ : Bao
功能 : 二分查找-方法3
"""
import time
def cal_time(func): #装饰器,用于显示运行时间
def wrapper(*args, **kwargs):
t1 = time.time()
result = func(*args, **kwargs)
t2 = time.time()
print("running time:",func.__name__, t2 - t1)
return result
return wrapper
@cal_time
def BinarySearch2(target,array,left,right):
if left > right:
return False
mid = (left+right)//2
if array[mid] == target:
return "mid的值是: %s" %mid
elif array[mid] > target and (left <= mid-1):
return BinarySearch2(target,array,left,mid-1)
elif array[mid] < target and (left+1 <= right):
return BinarySearch2(target,array,left+1,right)
else:
return "该数值{}不存在".format(target)
SortedList = [17, 20, 26, 31, 44, 54, 55, 77, 93]
res = BinarySearch2(94, SortedList, 0, len(SortedList)-1)
print(res)

"""
__Author__: Bao
功能:查找素数方法一
"""
def prime(list):
list2 = []
for i in list:
if i == 0 or i ==1:
continue
else:
for j in range(2,i):
if i%j == 0 :
break
else:
list2.append(i)
return list2
list = list(range(15))
list2 = prime(list)
print(list2)
"""
__Author__: Bao
功能:查找素数方法二
"""
from math import sqrt
def is_prime(num):
if num < 2:
return False
else:
for j in range(2, int(sqrt(num))+1):
if num % j ==0:
break
else:
return True
list = list(range(1,15))
for i in list:
if is_prime(i):
print(i)
"""
__Author__: Bao
功能:查找素数方法三
"""
from math import sqrt
def is_prime(number):
if number > 1:
if number == 2:
return True
if number % 2 == 0:
return False
for current in range(3, int(sqrt(number) + 1), 2): # 步长为2
if number % current == 0:
return False
return True
return False
list = list(range(1,15))
for i in list:
if is_prime(i):
print(i)
