


ELK实战搭建+x-pack安全认证
阅读目录:
ELK日志平台入门简介
1.1 ELK原理拓扑图
1.2 Elasticsearch安装配置
1.3 Kibana安装配置
1.4 Kibana汉化及时区修改
1.5 Logstash安装配置
1.6 Kafka/Redis服务数据存储
1.7 Filebeat安装及启动
1.8 Filebeat收集access日志、应用日志、多行合并及过滤
1.9 AWS网络日志监控elk配置
1.10 Kibana批量日志收集
1.11 Kibana安全认证
1.12 logstash之正则表达式
1.13 logstash之multiline插件,匹配多行日志
1.14 logstash之filter,正则匹配过滤日志
1.15 Elasticsearch 定期清理索引丶缓存丶集群分片数
ELK日志平台入门简介
作为运维工程师,我们每天需要对服务器进行故障排除,那么最先能帮助我们定位问题的就是查看服务器日志,通过日志可以快速的定位问题。
目前我们说的日志主要包括系统日志、应用程序日志和安全日志。系统运维和开发人员可以通过日志了解服务器软硬件信息、检查配置过程中的错误及错误发生的原因。经常需要分析日志可以了解服务器的负荷,性能安全性,从而及时采取措施纠正错误。而且日志被分散的储存不同的设备上。
如果你管理数上百台服务器,我们登录到每台机器的传统方法查阅日志。这样是不是感觉很繁琐和效率低下。当务之急我们使用集中化的日志管理,例如:开源的syslog,将所有服务器上的日志收集汇总。
集中化管理日志后,日志的统计和检索又成为一件比较麻烦的事情,一般我们使用find、grep、awk和wc等Linux命令能实现检索和统计,但是对于要求更高的查询、排序和统计等要求和庞大的机器数量依然使用这样的方法难免有点力不从心。
今天给大家分享的开源实时日志分析ELK平台能够完美的解决我们上述的问题,ELK由ElasticSearch、Logstash和Kiabana三个开源工具组成。
ELK=elasticsearch+Logstash+kibana
1) Elasticsearch是个开源分布式搜索引擎,它的特点有:分布式,零配置,自动发现,索引自动分片,索引副本机制,restful风格接口,多数据源,自动搜索负载等,ELK官网:https://www.elastic.co/
2) Logstash 主要是用来日志的搜集、分析、过滤日志的工具,支持大量的数据获取方式。工作方式为C/S架构,Client端安装在需要收集日志的主机上,Server端负责将收到的各节点日志进行过滤、修改等操作在一并发往Elasticsearch服务器。
3) Kibana 也是一个开源和免费的工具,它Kibana可以为 Logstash 和 ElasticSearch 提供的日志分析友好的 Web 界面,可以帮助您汇总、分析和搜索重要数据日志;
4) FileBeat是一个轻量级日志采集器,Filebeat属于Beats家族的6个成员之一,早期的ELK架构中使用Logstash收集、解析日志并且过滤日志,但是Logstash对CPU、内存、IO等资源消耗比较高,相比Logstash,Beats所占系统的CPU和内存几乎可以忽略不计;
5) Logstash和Elasticsearch是用Java语言编写,而Kibana使用node.js框架,在配置ELK环境要保证系统有JAVA JDK开发库;
6) Redis/kafka 负责消息队列机制,存储数据,缓解高并发,即使远端Logstash server因故障停止运行,数据将会先被存储下来,从而避免数据丢失。
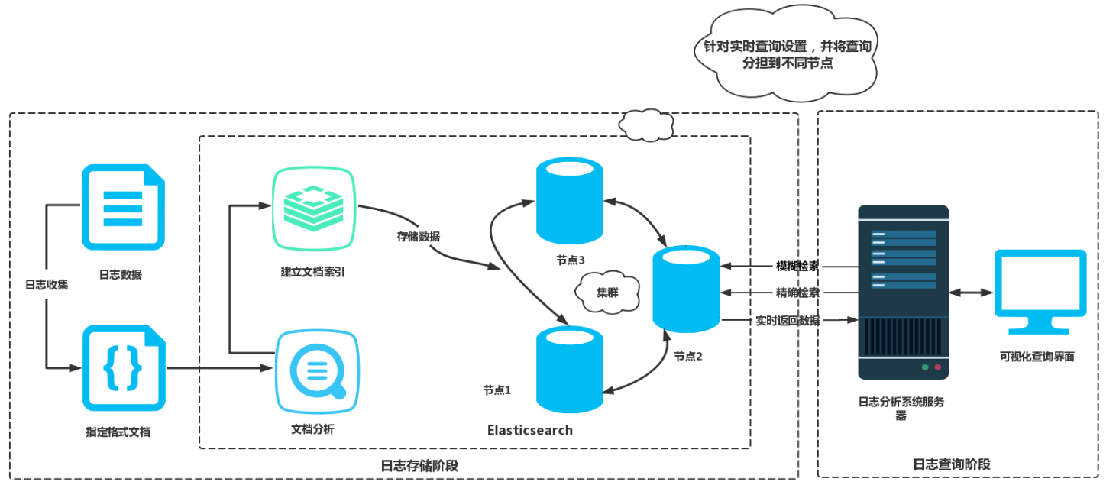
1.1 ELK原理拓扑图
今天带大家一起来学习EKL企业分布式实时日志平台的构建.
如果使用Filebeat,Logstash从FileBeat获取日志文件。Filebeat作为Logstash的输入input将获取到的日志进行处理,将处理好的日志文件输出到Elasticsearch进行处理,
1) ELK工作流程
通过logstash收集客户端APP的日志数据,将所有的日志过滤出来,存入Elasticsearch 搜索引擎里,然后通过Kibana GUI在WEB前端展示给用户,用户需要可以进行查看指定的日志内容。
下图为EKL企业分布式实时日志平台结构图,如果没有使用Filebeat,Logstash收集日志,进行过滤处理,并且将数据发往elasticsearch,结构图如下:
同时也可以加入kafka/redis通信队列:
图一:
图二:亿级建议采用模式三
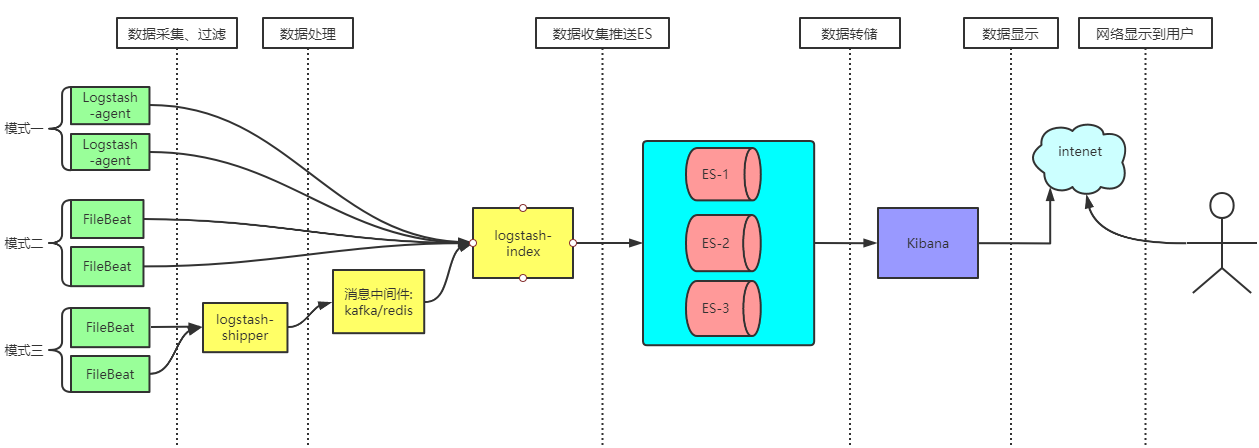
2) 加入kafka/Redis队列后工作流程
FileBeat负责收集及过滤日志存储到kafka/redis中,Logstash包含Index和Agent(shipper) ,Agent负责客户端监控和数据处理,而Index负责收集中间件日志并将日志交给ElasticSearch,ElasticSearch将日志存储本地,建立索引、提供搜索,kibana可以从ES集群中获取想要的日志信息。
1.2 Elasticsearch安装配置
安装ELK之前,需要先安装JDK (Java Development Kit) 是 Java 语言的软件开发工具包(SDK)),这里选择jdk-8u102-linux-x64.rpm ,bin文件安装跟sh文件方法一样,rpm -ivh jdk-8u102-linux-x64.rpm ,回车即可,默认安装到/usr/java/jdk1.8.0_102目录下。
配置java环境变量,参考博客篇:https://www.cnblogs.com/zhangan/p/10901192.html
修改操作系统的内核优化,参考博客篇:https://www.cnblogs.com/zhangan/p/10956138.html#x3
注释:java环境与操作系统的内核优化必须做,不然启动程序会报错。
另外修改操作系统的内核配置文件sysctl.conf(2台),sysctl - p 生效
[root@es-master local]# vim /etc/sysctl.conf
#在配置文件最后面添加如下内容
vm.max_map_count=262144
vm.swappiness=0
解释:max_map_count文件包含限制一个进程可以拥有的VMA(虚拟内存区域)的数量。虚拟内存区域是一个连续的虚拟地址空间区域。在进程的生命周期中,每当程序尝试在内存中映射文件,链接到共享内存段,或者分配堆空间的时候,这些区域将被创建。当进程达到了VMA上线但又只能释放少量的内存给其他的内核进程使用时,操作系统会抛出内存不足的错误。
swappiness,Linux内核参数,控制换出运行时内存的相对权重。swappiness参数值可设置范围在0到100之间。 低参数值会让内核尽量少用交换,更高参数值会使内核更多的去使用交换空间。默认值为60,对于大多数操作系统,设置为100可能会影响整体性能,而设置为更低值(甚至为0)则可能减少响应延迟。
vm.swappiness=1;进行最少量的交换,而不禁用交换。如果设置为 0 的话,则等同于禁用 swap
特别提醒:
Elasticsearch-7版本最低支持jdk版本为JDK1.11
Elasticsearch-7.4.2该版本内置了JDK,而内置的JDK是当前推荐的JDK版本。当然如果你本地配置了JAVA_HOME那么ES就是优先使用配置的JDK启动ES。(言外之意,你不安装JDK一样可以启动,我试了可以的。)
ES推荐使用LTS版本的JDK(这里只是推荐,JDK8就不支持),如果你使用了一些不支持的JDK版本,ES会拒绝启动。
由于我们日常的代码开发都是使用的JDK1.8,而且可能JAVA_HOME配置成JDK1.8,那么解决方法我们只需更改Elasticsearch的启动文件,使它指向Elasticsearch-7.4.2该版本内置了JDK,或者也可以参照jdk安装文档升级jdk高版本
修改启动配置文件
[root@localhost bin]# pwd
/data/elasticsearch/bin
[root@localhost bin]# vi elasticsearch

#配置es自带的jdk路径
export JAVA_HOME=/usr/local/elasticsearch-node1/jdk
export PATH=$JAVA_HOME/bin:$PATH
#添加jdk判断
if [ -x "$JAVA_HOME/bin/java" ]; then
JAVA="/usr/local/elasticsearch-node1/jdk/bin/java"
else
JAVA=`which java`
fi
分别下载ELK软件包:
|
wget https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-7.4.2-linux-x86_64.tar.gz wget https://artifacts.elastic.co/downloads/logstash/logstash-7.4.2.tar.gz Wget https://artifacts.elastic.co/downloads/kibana/kibana-7.4.2-linux-x86_64.tar.gz wget http://117.128.6.27/cache/download.redis.io/releases/redis-4.0.14.tar.gz?ich_args2=522-03101307057974_3dd269048c70bdf875dc9acff1b71955_10001002_9c89622bd3c4f7d69f33518939a83798_c8a912a80ccc397fec935bfecdb1cca8 wget https://archive.apache.org/dist/kafka/2.4.1/kafka_2.12-2.4.1.tgz wget https://artifacts.elastic.co/downloads/beats/filebeat/filebeat-7.4.2-linux-x86_64.tar.gz
|
1) ELK安装信息
|
192.168.111.128 Elasticsearch 192.168.111.129 Kibana 192.168.111.130 Logstash-shipper + kafka 192.168.111.131 Logstash-index |
2) 192.168.111.128上安装elasticsearch-node1
|
wget https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-7.4.2-linux-x86_64.tar.gz tar xf elasticsearch-7.4.2.tar.gz -C /usr/local/ cd /usr/local/ mv elasticsearch-7.4.2 elasticsearch-node1 |
3) 配置
注意:由于elasticsearch启动的时候不能直接用root用户启动,所以需要创建普通用户
|
useradd elk chown -R elk:elk /usr/local/elasticsearch-node1 |
分别创建两个elasticsearch节点的数据目录和日志目录
| mkdir -pv /usr/local/elasticsearch-node1/{data,logs} chown -R elk:elk /usr/local/elasticsearch-node1 |
修改elasticsearch节点的配置文件jvm.options
|
cd /usr/local/elasticsearch-node1/config/ vi jvm.options |
修改如下两个选项:
- -Xms512m #elasticsearch启动时jvm所分配的初始堆内存大小
- -Xmx512m #elasticsearch启动之后允许jvm分配的最大堆内存大小,生产环境中可能需要调大
注意:
1. 最大值和最小值设置为一样的值,否则在系统使用的时候会因jvm值变化而导致服务暂停
2. 过多的内存,会导致用于缓存的内存越多,最终导致回收内存的时间也加长
3. 设置的内存不要超过物理内存的50%,以保证有足够的内存留给操作系统
4. 不要将内存设置超过32GB
修改elasticsearch节点的配置文件elasticsearch.yml
#表示集群标识,同一个集群中的多个节点使用相同的标识 cluster.name: es-cluster #节点名称 node.name: "elasticsearch-node1" #数据存储目录 path.data: /usr/local/elasticsearch-node1/es_data #日志目录 path.logs: /usr/local/elasticsearch-node1/es_logs #节点所绑定的IP地址,并且该节点会被通知到集群中的其他节点 network.host: 192.168.111.128 #绑定监听的网络接口,监听传入的请求,可以设置为IP地址或者主机名 network.bind_host: 192.168.111.128 #发布地址,用于通知集群中的其他节点,和其他节点通讯,不设置的话默认可以自动设置。必须是一个存在的IP地址 network.publish_host: 192.168.111.128 #es7.x 之后新增的配置,初始化一个新的集群时需要此配置来选举master,配置一个主节点 cluster.initial_master_nodes: ["192.168.111.128"] #集群通信端口 transport.tcp.port: 9300 transport.tcp.compress: true #设置是否压缩tcp传输时的数据,默认为false #对外提供服务的http端口,默认为9200 http.port: 9200 #集群中主节点的初始列表,当主节点启动时会使用这个列表进行非主节点的监测 discovery.seed_hosts: ["192.168.111.128:9300","192.168.111.128:9301"] cluster.fault_detection.leader_check.interval: 15s discovery.cluster_formation_warning_timeout: 30s cluster.join.timeout: 30s cluster.publish.timeout: 60s #cache缓存大小,10%(默认),可设置成百分比,也可设置成具体值,如256mb。 indices.queries.cache.size: 30% #索引期间的内存缓存,有利于索引吞吐量的增加。 indices.memory.index_buffer_size: 30% #开启了内存地址锁定,为了避免内存交换提高性能。但是Centos6不支持SecComp功能,启动会报错,所以需要将其设置为false bootstrap.memory_lock: true #设置在集群中最大允许同时进行分片分布的个数,默认为2,也就是说整个集群最多有两个分片在 进行重新分布。 cluster.routing.allocation.cluster_concurrent_rebalance: 60 #设置在节点中最大允许同时进行分片分布的个数,默认为2 cluster.routing.allocation.node_concurrent_recoveries: 60 #设置指定初始每个节点。由于多数情况下是使用local的gateway,这应该会更快 cluster.routing.allocation.node_initial_primaries_recoveries: 60 #设置该节点是否具有成为主节点的资格以及是否存储数据。 node.master: true node.data: true node.ingest: true xpack.monitoring.exporters.my_local.type: local xpack.monitoring.exporters.my_local.use_ingest: false #默认配置为:节点每隔1s同master发送1次心跳,超时时间为30s,测试次数为3次,超过3次,则认为该节点同master已经脱离了。以上为elasticsearch的默认配置。在实际生产环境中,每隔1s,太频繁了,会产生太多网络流量,如下优化: discovery.zen.fd.ping_timeout: 300s discovery.zen.fd.ping_retries: 8 discovery.zen.fd.ping_interval: 60s #queue_size允许控制没有线程执行它们的挂起请求队列的初始大小。 thread_pool.search.queue_size: 1024 #size参数控制线程数,默认为核心数乘以5。 thread_pool.search.size: 200 #min_queue_size设置控制queue_size可以调整到的最小量。 thread_pool.search.min_queue_size: 40 #max_queue_size设置控制queue_size可以调整到的最大量。 thread_pool.search.max_queue_size: 1000 #auto_queue_frame_size设置控制在调整队列之前进行测量的操作数。它应该足够大,以便单个操作不会过度偏向计算。 thread_pool.search.auto_queue_frame_size: 2000 #target_response_time是时间值设置,指示线程池队列中任务的目标平均响应时间。如果任务通常超过此时间,则将调低线程池队列以拒绝任务。 thread_pool.search.target_response_time: 6s #允许集群最大索引分片 cluster.max_shards_per_node: 900000
4) 192.168.111.128上安装elasticsearch-node2
|
cd /usr/local/ cp -r elasticsearch-node1 elasticsearch-node2 |
修改vim /usr/local/elasticsearch-node2/config/elasticsearch.yml文件
cluster.name: es-cluster node.name: "elasticsearch-node2" path.data: /usr/local/elasticsearch-node2/es_data path.logs: /usr/local/elasticsearch-node2/es_logs network.host: 192.168.111.128 network.bind_host: 192.168.111.128 network.publish_host: 192.168.111.128 cluster.initial_master_nodes: ["192.168.111.128"] transport.tcp.port: 9301 transport.tcp.compress: true #设置是否压缩tcp传输时的数据,默认为false http.port: 9201 discovery.seed_hosts: ["192.168.111.128:9300","192.168.111.128:9301"] cluster.fault_detection.leader_check.interval: 15s discovery.cluster_formation_warning_timeout: 30s cluster.join.timeout: 30s cluster.publish.timeout: 60s indices.queries.cache.size: 30% indices.memory.index_buffer_size: 30% bootstrap.memory_lock: true cluster.routing.allocation.cluster_concurrent_rebalance: 60 cluster.routing.allocation.node_concurrent_recoveries: 60 cluster.routing.allocation.node_initial_primaries_recoveries: 60 node.master: true node.data: true node.ingest: true xpack.monitoring.exporters.my_local.type: local xpack.monitoring.exporters.my_local.use_ingest: false discovery.zen.fd.ping_timeout: 300s discovery.zen.fd.ping_retries: 8 discovery.zen.fd.ping_interval: 60s thread_pool.search.queue_size: 1024 thread_pool.search.size: 200 thread_pool.search.min_queue_size: 40 thread_pool.search.max_queue_size: 1000 thread_pool.search.auto_queue_frame_size: 2000 thread_pool.search.target_response_time: 6s cluster.max_shards_per_node: 900000
5) 启动
首先切换为elk用户
|
su - elk /usr/local/elasticsearch-node1/bin/elasticsearch -d /usr/local/elasticsearch-node2/bin/elasticsearch -d |
启动后如下图:

使用curl测试节点是否可以正常访问,
curl 192.168.111.128:9200
curl 192.168.111.128:9201
查看状态
curl "http://127.0.0.1:9200/_status?pretty=true"
查看集群健康
curl "http://127.0.0.1:9201/_cat/health?v"
至此ES配置完毕
1.3 Kibana安装配置
下载解压安装:
|
wget https://artifacts.elastic.co/downloads/kibana/kibana-7.4.2-linux-x86_64.tar.gz tar xf kibana-7.4.2-linux-x86_64.tar.gz -C /usr/local |
修改kibana的配置文件kibana.yml
|
[root@localhost local]# cd kibana/config #设置请求时长 |
启动kibana
|
[root@localhost config]# cd /usr/local//bin |
如果启动正常,在浏览器端访问http://192.168.111.129:5601,即可看到图形化操作工具
1.4 Kibana汉化及时区修改
|
vi kibana.yml i18n.locale: "zh-CN" |
时区修改步骤:
进入kibana界面-》管理-》高级设置-》设置日期格式的时区
默认:Browser
可修改为:Asia/Shanghai
重启即可!
1.5 Logstash安装配置
1、wget https://artifacts.elastic.co/downloads/logstash/logstash-7.4.2.tar.gz
解压logstash:
|
tar xzf logstash-7.4.2.tar.gz mv logstash-7.4.2 /usr/local/logstash/ |
2、logstash的优化pipelines.yml丶logstash.yml配置
可以优化的参数,可根据自己的硬件进行优化配置:
①pipeline线程数,官方建议是等于CPU内核数
- 默认配置 ---> pipeline.workers: 20;
- 可优化为 ---> pipeline.workers: CPU内核数(或几倍CPU内核数)。
②实际output时的线程数
- 默认配置 ---> pipeline.output.workers: 15;
- 可优化为 ---> pipeline.output.workers: 不超过pipeline线程数。
③每次发送的事件数
- 默认配置 ---> pipeline.batch.size: 125;
- 可优化为 ---> pipeline.batch.size: 1000。
④发送延时(单位是毫秒)
- 默认配置 ---> pipeline.batch.delay: 50;
- 可优化为 ---> pipeline.batch.delay: 100。
总结:
- 通过设置-w参数指定pipeline worker数量,也可直接修改配置文件logstash.yml。这会提高filter和output的线程数,如果需要的话,将其设置为cpu核心数的几倍是安全的,线程在I/O上是空闲的。
- 默认每个输出在一个pipeline worker线程上活动,可以在输出output中设置workers设置,不要将该值设置大于pipeline worker数。
- 还可以设置输出的batch_size数,例如ES输出与batch size一致。
- filter设置multiline后,pipline worker会自动将为1,如果使用filebeat,建议在beat中就使用multiline,如果使用logstash作为shipper,建议在input中设置multiline,不要在filter中设置multiline。
Logstash中的jvm.options配置文件:
Logstash是一个基于Java开发的程序,需要运行在JVM中,可以通过配置jvm.options来针对JVM进行设定。比如内存的最大最小、垃圾清理机制等等。JVM的内存分配不能太大不能太小,太大会拖慢操作系统。太小导致无法启动。默认如下:
- Xms256m#最小使用内存;
- Xmx1g#最大使用内存。
1.6 Kafka/Redis服务数据存储
(1) redis数据存储
|
wget http://117.128.6.27/cache/download.redis.io/releases/redis-4.0.14.tar.gz?ich_args2=522-03101307057974_3dd269048c70bdf875dc9acff1b71955_10001002_9c89622bd3c4f7d69f33518939a83798_c8a912a80ccc397fec935bfecdb1cca8 tar zxf redis-4.0.14.tar.gz -C /usr/local cd redis-3.0.5 make make install |
将/usr/local/redis/bin/目录加入至环境变量配置文件/etc/profile末尾,然后Shell终端执行source /etc/profile让环境变量生效。
|
export PATH=/usr/local/redis/bin:$PATH |
配置:
|
vim redis.conf #修改以下内容,不是必须的 bind 127.0.0.1 192.168.111.130 #两台主机分别改为自己的IP logfile "/usr/local/src/redis-3.0.3/redis.log" daemonize yes #启用守护模式 #requirepass "admin.123" #设置redis登录密码 这个看自己需求可以不要 |
Redis做ELK缓冲队列的优化:
- bind 0.0.0.0 #监听本地ipv4ip端口;
- requirepass ilinux.io #加密码,为了安全运行(看自己需求);
- 只做队列,没必要持久存储,把所有持久化功能关掉:
- 关闭快照(RDB文件)和追加式文件(AOF文件),性能更好;
- save "" 禁用快照;
- appendonly no 关闭RDB。
- 把内存的淘汰策略关掉,把内存空间最大
- maxmemory 0 #maxmemory为0的时候表示我们对Redis的内存使用没有限制。
- vm.overcommit_memory = 1 写入 /etc/sysctl.conf,执行sysctl -p 即可。
启动及停止Redis服务命令:
|
/usr/local/redis/bin/redis-server /usr/local/redis/redis.conf /usr/local/redis/bin/redis-cli -p 6379 shutdown |
查看redis内存使用情况:redis-cli -r 100 -i 1 info Memory |grep "used_memory_human"
(2)kafka数据存储
参考博客篇:https://www.cnblogs.com/zhangan/p/10986226.html
重点:filebeat收集的日志数据会存放在某一个topic里面,因为kafka数据存储在本地磁盘,切记设置该topic数据的过期时间,可以不需要重启kafka,防止磁盘爆增!
1.7 Filebeat安装及启动
|
wget https://artifacts.elastic.co/downloads/beats/filebeat/filebeat-7.4.2-linux-x86_64.tar.gz tar -zxvf filebeat-7.4.2-linux-x86_64.tar.gz -C /usr/local/ mv filebeat-7.4.2-linux-x86_64 filebeat |
启动方式如下:
./filebeat -e -c ../filebeat.yml
-c:配置文件位置
-path.logs:日志位置
-path.data:数据位置
-path.home:家位置
-e:关闭日志输出
-d 选择器:启用对指定选择器的调试。 对于选择器,可以指定逗号分隔的组件列表,也可以使用-d“*”为所有组件启用调试.例如,-d“publish”显示所有“publish”相关的消息。
后台启动filebeat
nohup ./filebeat -e -c ../filebeat.yml >/dev/null 2>&1 & 将所有标准输出及标准错误输出到/dev/null空设备,即没有任何输出
nohup ./filebeat -e -c ./filebeat.yml > filebeat.log &
1.8 Filebeat收集access日志、应用日志、多行合并及过滤
建议:Tomcat配置文件server.xml对accesss日志输出格式优化如下:
<Valve className="org.apache.catalina.valves.AccessLogValve" directory="logs" prefix="app" suffix=".access" pattern="{"access_time":"%{yyyy-MM-dd'T'HH:mm:ss.SSSXXX}t","host_local":"%v","username":"%u","fwd_for":"%{x-forwarded-for}i","host_remote":"%h","ip_remote":"%a","ip_local":"%A","port":"%p","method":"%m","status":"%s","uri":"%U","qstr":"%q","bytes":%B,"latency":%D,"con_st":"%X"}" />
输出josn样式:
{"access_time":"[28/Apr/2021:13:50:51 +0800]","host_local":"tc-xxxx.g-net.net","username":"-","fwd_for":"220.114.11.74","host_remote":"192.168.13.12","ip_remote":"192.168.13.12","ip_local":"192.168.118.156","port":"80","method":"GET","status":"200","uri":"/xxx/services/vehicle/status/vehicleModel/123123","qstr":"?source=tc&altitude=0&latitude=82719093&longitude=408227025&radius=30","bytes":13981,"latency":87,"con_st":"+"}
1) filebeat客户端日志采集 --> 存入logstash-shipper:
配置文件:/usr/local/filebeat/config/filebeat.yml:
filebeat.yml文件内容:
filebeat.inputs: - type: log enabled: true paths: - /opt/csp/app/tc/apache-tomcat-tc/logs/localhost_access_log.* json.keys_under_root: true json.overwrite_keys: true exclude_files: ['.gz$'] tail_files: true close_older: 24h scan_frequency: 1s idle_timeout: 5s fields: # 重要,appnamne最终决定入到的ex index名称 appname: tc log_type: access fields_under_root: true - type: log enabled: true paths: - /opt/csp/logs/hmac/TC.log exclude_lines: ["DEBUG","Dictionary","kpi","invoke:method=execute","profile","Sftp","channel","directory","connected"] tail_files: true close_older: 24h scan_frequency: 1s idle_timeout: 5s fields: appname: tc log_type: app fields_under_root: true multiline.pattern: '^\[' multiline.negate: true multiline.match: after - type: log enabled: true paths: - /opt/ddi/dispatcher/dispatcher-connector/log/dispatcher-connector.log exclude_lines: ["WARN","Code=100005","TRS"] tail_files: true close_older: 24h scan_frequency: 1s idle_timeout: 5s fields: appname: dispatcher-connector log_type: app fields_under_root: true multiline.pattern: '^\d{4}-\d{1,2}-\d{1,2}\s\d{1,2}:\d{1,2}:\d{1,2}' multiline.negate: true multiline.match: after processors: - drop_fields: #删除字段,不再kibana里面展示,默认情况kibana里面会自动展示这些beat字段 fields: ["@version","offset","@metadata","ecs","agent","log","input.type"] - drop_event: #删除事件,匹配uri 删除以tc-message开头的事件 when: regexp: uri: "^/tc-message" output.logstash: enabled: true # logstsh的ip地址 hosts: ["192.168.111.130:5600"] loadbalance: true worker: 3
主要配置项说明:
enabled:true 代表开启这个配置节
paths: 监控指定目录下的文件,支持模糊搜索
tail_files: true :第一次读取的是最新内容,不需要整个文件读取 (可选)
fields_under_root:如果该选项设置为true,则新增fields成为顶级目录,而不是将其放在fields目录下。自定义的field会覆盖filebeat默认的field
exclude_lines: 指定正则表达式,用来指定不要匹配的行,在输入中排除符合正则表达式列表的那些行,可以有几个。(可选)
include_lines: 指定正则表达式,用来指定匹配的行,在输入中排除符合正则表达式列表的那些行,可以有几个。(可选)
close_older: 如果一个文件在某个时间段内没有发生过更新则关闭监控的文件handle。默认1h,change只会在下一次scan才会被发现(可选)
scan_frequency: Filebeat以多快的频率去prospector指定的目录下面检测文件更新比如是否有新增文件如果设置为0s则Filebeat会尽可能快地感知更新占用的CPU会变高。默认是10s。
harvester_buffer_size: 每个harvester监控文件时使用的buffer的大小。(可选)
max_bytes: 日志文件中增加一行算一个日志事件max_bytes限制在一次日志事件中最多上传的字节数多出的字节会被丢弃。The default is 10MB.(可选)
idle_timeout: 后台刷新超时时间,超过定义时间后强制发送,不管spool_size后台事件计数阈值是否达到,默认5秒。
fields: 增加fields额外字段,附加的可选字段,以向output添加额外的信息。output里面可以使用这个变量
multiline: 多行日志监控,下面配置的意思是:不以[开头的行都合并到上一行的末尾(正则写的不好,忽略忽略)
pattern:正则表达式
negate:true 或 & false;默认是false,匹配pattern的行合并到上一行;true,不匹配pattern的行合并到上一行
match:after 或 before,合并到上一行的末尾或开头
drop_fields: #删除字段,不再kibana里面展示,默认情况kibana里面会自动展示这些beat字段
output.logstash: 配置host指定logstash地址
loadbalance: true 每一条message都随机负载均衡到logstash
2) Logstash-shipper --> 存入kafka:
shipper.conf文件内容:
#logstash shipper for access log input { # 监听多个端口 beats { port => 5600 } beats { port => 5601 } } filter { grok { match => {"message" => "%{TIMESTAMP_ISO8601:access_time}\s*%{LOGLEVEL:level}\s*%{UUID:uuid}\s*%{WORD:word}\s*%{HOSTNAME:hostname}\s*\[%{DATA:work}\]\s*(?<api>([\S+]*))\s*(?<TraceID>([\S+]*))\s*%{GREEDYDATA:message_data}"} match => {"message" => "%{TIMESTAMP_ISO8601:access_time}\s*%{LOGLEVEL:level}\s*%{WORD:word}\s*%{HOSTNAME:hostname}\s*(?<TraceID>([\S+]*))\s*(?<api>([\S+]*))\s*(?<brackets>([\S+]*))\s*%{GREEDYDATA:message_data}"} remove_field =>["message","level","uuid","word","hostname","work","brackets","api","TraceID"] } #使用grok规则转化数据为KV模式 if [appname] == "ocsp_jboss" { grok { match => {"message" => "%{TIME:date}\s*%{LOGLEVEL:level}\s*\[%{DATA:thread}]\s*(?<http>([\S+]*))\s*%{WORD:a}\s*%{WORD:a1}\s*%{WORD:b}\s*%{WORD:c}\s*%{WORD:d}\s*%{WORD:e}\s*%{WORD:f}:\s*(?<serNo>([\S+]*)),\s*%{WORD:g}\s*%{WORD:h}:\s*%{WORD:issuerNameHash}.\s*%{WORD:j}\s*%{WORD:k}\s*%{IP:ip}"} remove_field =>["message","level","thread","a","a1","b","c","d","e","f","g","h","j","k","http"] } } #ruby { code => "event.set('timestamp', event.get('@timestamp').time.localtime + 8*60*60)" } # 如果含有access_time,要识别出来作为@timestamp date { timezone => "Asia/Shanghai" match => ["access_time","ISO8601","[dd/MMM/yyyy:HH:mm:ss Z]"] target => "@timestamp" } #如果程序输出日志格式为KV模式,则可以直接转化输出为josn格式 if [appname] == "connectioneventlog" { json { source => "message" } mutate { remove_field => [ "message" ] } } # 消息,特殊处理 if [agent][type] == "filebeat" { mutate { remove_field => ["access_time", "input", "host", "ecs", "log", "tags", "@version", "version"] add_field => { "hostname"=>"%{[agent][hostname]}" } remove_field => ["agent"] } } } output { # 调试用的 #stdout { codec => rubydebug } kafka { bootstrap_servers=>"192.168.111.130:9092" codec => json { charset => "UTF-8" } topic_id=> "elk-pipe-access" # 是否要开启压缩,节省带宽,2s 一个批次压缩,预期70%的压缩率 #linger_ms=>2000 #compression_type=>"snappy" } }
然后启动logstash-shipper:../bin/logstash -f logstash-shipper.conf
查看启动进程:ps -ef |grep logstash
注意:所有指定新建索引名称必须是小写,否则会报错 "Could not index event to Elasticsearch"
3) Logstash-index --> 存入ES;
index.conf文件内容:
input { kafka { bootstrap_servers => ["192.168.116.81:9092,192.168.116.82:9092,192.168.116.83:9092"] group_id => "es-indexer" consumer_threads => 2 topics => ["elk-pipe-access", "elk-pipe-applog"] codec => json { charset => "UTF-8" } } } # 新增filter解决logstash创建索引晚8小时的问题 filter{ ruby { code => "event.set('index_date', (event.get('@timestamp').time.localtime).strftime('%Y.%m.%d.%H'))" } } output { elasticsearch { hosts => ["http://192.168.116.211:9200","http://192.168.116.212:9200","http://192.168.116.213:9200","http://192.168.116.214:9200","http://192.168.116.215:9200","http://192.168.116.216:9200"] user => "elastic" password => "XleBzj3GmE" # 按照appname字段区分index,按小时切分 index => "logstash-csp-%{[log_type]}-%{[appname]}-%{index_date}" } }
注意:YYYY.MM.dd.HH 是以小时为单位切割索引文件
然后启动logstash-index:../bin/logstash -f logstash-index.conf
查看启动进程:ps -ef |grep logstash
1.9 aws网络日志监控elk配置
AWS的网络日志存储在S3,可以通过logstash的S3插件获取,经过过滤器后,输出到elasticsearch,如下从s3直接采集的csv的配置方法:
# Sample Logstash configuration for creating a simple input { s3 { region => "cn-north-1" access_key_id => "access_key" secret_access_key => "secret_key" bucket => "vpc-sp1" prefix => "AWSLogs/781402671718/vpcflowlogs/cn-north-1/2021/" additional_settings => { "force_path_style" => true "follow_redirects" => false } } } filter { csv { #version account-id interface-id srcaddr dstaddr srcport dstport protocol packets bytes start end action log-status ##2 7804012311238 eni-f51e30ae 173.17.219.128 172.11.23.76 45039 10744 6 1 40 1611969092 1611969147 ACCEPT OK separator=>" " skip_header=>true autodetect_column_names=>false columns => ["version","account-id","interface-id","srcaddr","dstaddr","srcport","dstport","protocol","packets","bytes","start","end","action","log-status"] convert => { "packets"=>"integer" "bytes"=>"integer" "start"=>"integer" "end"=>"integer" } } if [action] == "-" { drop{} } if [bytes] == "-" { drop{} } if [bytes] == " " { drop{} } date { match => ["start", "yyyy-MM-dd HH:mm:ss,SSS", "UNIX"] target => "@timestamp" # locale => "cn" } date { match => ["end", "yyyy-MM-dd HH:mm:ss,SSS", "UNIX"] target => "endtime" # locale => "cn" } mutate { add_field => { "src" => "%{srcaddr}:%{srcport}" "dst" => "%{dstaddr}:%{dstport}" "geoip.ip" => "%{dstaddr}" } remove_field => ["@version", "message", "version", "account-id", "start", "end"] } } output { # stdout { codec => rubydebug } elasticsearch { hosts => ["http://192.168.111.128:9200","http://192.168.111.128:9201"] user => "elastic" password => "XleBzj3GmE" # 按照appname字段区分index,按小时切分 index => "logstash-csp-vpc-sp1-%{+YYYY.MM.dd.HH}" } }
然后启动logstash-vpc: ../bin/logstash -f logstash-vpc.conf
1.10 Kibana批量日志收集
如上配置可以正常收集单台服务器的日志,如何批量收集其他服务器的日志信息呢,方法步骤是什么呢?
可以基于SHELL脚本将配置完毕的logstash文件夹同步至其他服务器,或者通过ansible、saltstack服务器均可。
例如收集Nginx日志,index.conf和agent.conf内容保持不变即可:
1.11 Kibana安全认证
第一种密码访问方式:x-pack密钥
从 7.1.0 版本开始, Elastic Stack安全功能免费提供。用户现在能够对网络流量进行加密、创建和管理用户、定义能够保护索引和集群级别访问权限的角色,并且使用 Spaces 为 Kibana 提供全面保护。
配置 TLS 和身份验证
我们要做的第一件事是生成证书,通过这些证书便能允许节点安全地通信。您可以使用企业 CA 来完成这一步骤,但是在此演示中,我们将会使用一个名为 elasticsearch-certutil 的命令,通过这一命令,您无需担心证书通常带来的任何困扰,便能完成这一步。
第 1步:清理数据目录data(这一步是最重要的初始化操作,如果不清理启动主节点时可能会报错master not discovered or elected yet, an election requires at least 2 nodes)
第 2步:在 Elasticsearch 主节点上配置 TLS
使用 cd 命令更改至 master 目录,然后运行下列命令:
bin/elasticsearch-certutil cert -out config/elastic-certificates.p12 -pass ""
接下来,打开文件 config/elasticsearch.yaml。将下列代码行粘贴到文件末尾,每个节点都要加。
xpack.security.enabled: true
xpack.security.transport.ssl.enabled: true
xpack.security.transport.ssl.verification_mode: certificate
xpack.security.transport.ssl.keystore.path: elastic-certificates.p12
xpack.security.transport.ssl.truststore.path: elastic-certificates.p12
保存文件,现在我们便可以启动主节点了
第 3 步:Elasticsearch 集群密码
一旦主节点开始运行,便可以为集群设置密码了。运行命令 bin/elasticsearch-setup-passwords auto。这将会为不同的内部堆栈用户生成随机密码。或者,您也可以跳过 auto 参数,改为通过 interactive 参数手动定义密码。请记录这些密码,我们很快就会再次用到这些密码。


注意点:在主节点生成p12文件、配置重启,生成密码完成前,千万不能操作其他节点。
第 4 步:在 Elasticsearch 节点上配置 TLS
在第1步运行bin/elasticsearch-certutil cert -out config/elastic-certificates.p12 -pass ""
该命令的时候 将会在config下生成elastic-certificates.p12文件,将此文件cp -a到其他两个节点的config目录,然后重启节点。
我们将看到其加入集群。而且,如果看一下主节点的终端窗口,我们会看到有一条消息显示已有一个节点加入集群。现在,我们的两节点集群便开始运行了。
注意点:一定要注意p12文件的权限属主
第 5 步:在 Kibana 中实现安全性
要做的最后一件事是为 Kibana 配置用户密码。我们可以从之前 setup-passwords 命令的输出内容中找到密码。打开 config/kibana.yml 文件。找到类似下面的代码行
#elasticsearch.username: "user"
#elasticsearch.password: "pass"
对 username 和 password 字段取消注释,方法是删除代码行起始部分的 # 符号。将 "user" 更改为 "kibana",然后将 "pass" 更改为 setup-passwords 命令告诉我们的任何 Kibana 密码。保存文件,然后我们便可通过运行 bin/kibana启动 Kibana 了。

登录后可以在此页面创建用户及控制用户权限,还可以对超级用户进行密码修改

然后相应的logstash收集过滤日志也需要配置用户密码,不然输出日志到elasticsearch失败,写法如下:
output {
stdout {
codec => json_lines
}
if [fields][log_topic] == "dispatcher-connector_zone2" {
elasticsearch {
hosts => ["192.168.115.98:9200","192.168.115.87:9200","192.168.115.126:9200"]
user => "elastic"
password => "Ericss0n"
index => "logstash_%{[fields][log_topic]}-%{+YYYY.MM.dd}"
}
}
}
第二种方式:Apache的密码认证进行安全配置。通过访问Nginx转发kibana服务器地址。
当我们安装完ES、Kibana启动进程,可以直接在浏览器访问,这样不利于数据安全,接下来我们利用Apache的密码认证进行安全配置。通过访问Nginx转发只ES和kibana服务器。
Kibana服务器安装Nginx:
|
yum install openssl openssl-devel pcre-devel pcre zlib zlib-devel –y wget -c http://nginx.org/download/nginx-1.8.1.tar.gz tar -xzf nginx-1.8.1.tar.gz cd nginx-1.8.1 useradd www ;./configure --user=www --group=www --prefix=/usr/local/nginx --with-pcre --with-pcre-jit --with-http_sub_module --with-http_stub_status_module --with-http_ssl_module --with-http_flv_module --with-http_realip_module --with-http_spdy_module --with-http_gunzip_module --with-http_gzip_static_module make make install #自此Nginx安装完毕 /usr/local/nginx/sbin/nginx -t 检查nginx配置文件是否正确,返回OK即正确。 |
修改Nginx.conf配置文件代码如下:
|
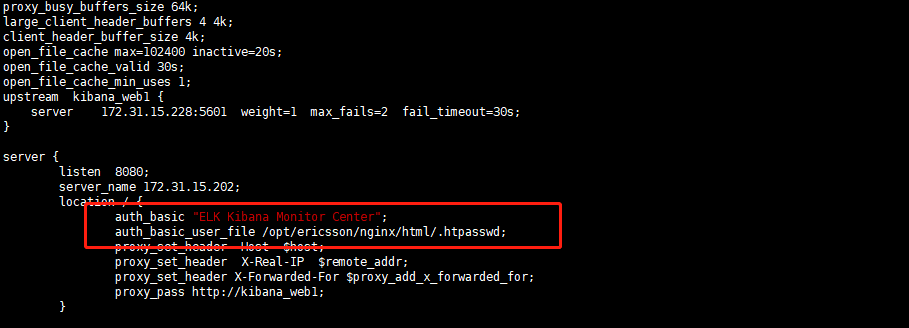
#user www www; worker_processes 2; worker_cpu_affinity 00000001 00000010; error_log /opt/ericsson/nginx/logs/error.log crit; pid /opt/ericsson/nginx/nginx.pid; worker_rlimit_nofile 102400; events { use epoll; worker_connections 102400; multi_accept on; } http { include mime.types; log_format main '$remote_addr - $remote_user [$time_local] "$request" ' '$status $body_bytes_sent "$http_referer" ' '"$http_user_agent" "$request_time"'; default_type application/octet-stream; access_log logs/access.log main ; sendfile on; tcp_nopush on; tcp_nodelay on; keepalive_timeout 60; gzip on; gzip_min_length 1k; gzip_buffers 4 16k; gzip_http_version 1.1; gzip_comp_level 4; gzip_types text/plain application/x-javascript text/css application/xml; gzip_vary on; client_max_body_size 10m; client_body_buffer_size 128k; proxy_connect_timeout 90; proxy_send_timeout 90; proxy_read_timeout 90; proxy_buffer_size 4k; proxy_buffers 4 32k; proxy_busy_buffers_size 64k; large_client_header_buffers 4 4k; client_header_buffer_size 4k; open_file_cache max=102400 inactive=20s; open_file_cache_valid 30s; open_file_cache_min_uses 1; upstream kibana_web1 { server 172.31.15.228:5601 weight=1 max_fails=2 fail_timeout=30s; }
server { listen 8080; server_name 172.31.15.202; location / { auth_basic "ELK Kibana Monitor Center"; auth_basic_user_file /opt/ericsson/nginx/html/.htpasswd; proxy_set_header Host $host; proxy_set_header X-Real-IP $remote_addr; proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for; proxy_pass http://kibana_web1; } } } |
修改kibana配置文件监听IP为127.0.0.1:

重启kibana和Nginx服务,通过Nginx 80端口访问如下:

添加Nginx权限认证:
Nginx.conf配置文件location /中加入如下代码:
|
auth_basic "ELK Kibana Monitor Center"; auth_basic_user_file /usr/local/nginx/html/.htpasswd; |
通过Apache加密工具htpasswd生成用户名和密码:
需要安装:yum -y install httpd-tools
htpasswd -c /usr/local/nginx/html/.htpasswd admin
重启Nginx web服务,访问如下:

用户名和密码正确,即可登录成功,
1.12 logstash之正则表达式
1,普通正则表达式如下:
| . 任意一个字符 * 前面一个字符出现0次或者多次 [abc] 中括号内任意一个字符 [^abc] 非中括号内的字符 [0-9] 表示一个数字 [a-z] 小写字母 [A-Z] 大写字母 [a-zA-Z] 所有字母 [a-zA-Z0-9] 所有字母+数字 [^0-9] 非数字 ^xx 以xx开头 xx$ 以xx结尾 \d 任何一个数字 \s 任何一个空白字符 |
2,扩展正则表达式,在普通正则符号再进行了扩展
| 扩展正则表达式,在普通正则符号再进行了扩展 ? 前面字符出现0或者1次 + 前面字符出现1或者多次 {n} 前面字符匹配n次 {a,b} 前面字符匹配a到b次 {,b} 前面字符匹配0次到b次 {a,} 前面字符匹配a或a+次 (string1|string2) string1或string2 |
简单提取IP
114.114.114.114 255.277.277.277
1-3个数字.1-3个数字.1-3个数字.1-3个数字
[0-9]{1,3}\.[0-9]{1,3}\.[0-9]{1,3}\.[0-9]{1,3}
1.13 logstash之multiline插件,匹配多行日志
在外理日志时,除了访问日志外,还要处理运行时日志,该日志大都用程序写的,一个异常的日志是多行的,我们目的是要把有这样的日志合并成一条
安装插件命令是 # logstash-plugin install logstash-filter-multiline
# logstash-plugin install logstash-filter-multiline
Validating logstash-filter-multiline
Installing logstash-filter-multiline
Installation successfu
|
在logstash filter中使用multiline插件(不推荐):
不推荐的原因:
- filter设置multiline后,pipline worker会自动降为1;
- 5.5 版本官方把multiline 去除了,要使用的话需下载;
在filter中,加入以下代码:
filter {
multiline { }
}
在logstash input中使用multiline插件(没有filebeat时推荐):
multiline字段属性:
对于multiline插件来说,有三个设置比较重要:negate , pattern 和 what
codec =>multiline {
charset=>... #可选 字符编码(UTF-8)
max_bytes=>... #可选 bytes类型 设置最大的字节数
max_lines=>... #可选 number类型 设置最大的行数,默认是500行
pattern=>... #必选 string类型 设置匹配的正则表达式
patterns_dir=>... #可选 array类型 可以设置多个正则表达式
negate=>... #必选 boolean类型 默认false不显示,可设置ture
what=>... #必选 向前previous , 向后 next
auto_flush_interval => 30 # 如果在规定时候内没有新的日志事件就不等待后面的日志事件
}
下面看看这两个例子:
1.一个java的报错:

input可以设置如下:
input {
file {
type => "TC"
start_position => "end"
path => "/opt/ericsson/csp/logs/TC.log"
codec => multiline {
pattern => "^\["
negate => true
what => "previous"
charset => "UTF-8"
}
}
}
说明:区配以"["开头的行,如果不是,那肯定是属于前一行的
2.比如一个java应用产生的异常日志是这样:
input可以设置如下:
input {
file {
type => "tsc-remote-status"
start_position => "end"
path => "/opt/qweq/logs/tsc-remote-status.log"
codec => multiline {
pattern => "^\d{4}-\d{1,2}-\d{1,2}\s\d{1,2}:\d{1,2}:\d{1,2}"
negate => true
what => "previous"
charset => "UTF-8"
}
}
}
说明:目的匹配以 “2017-11-15 14:32:03” 这种时间格式开头的日志,如果不是,那肯定是属于前一行的
1.14 logstash之filter,正则匹配过滤日志
1,条件判断
使用条件来决定filter和output处理特定的事件。logstash条件类似于编程语言。条件支持if、else if、else语句,可以嵌套。
比较操作有:
- 相等:
==,!=,<,>,<=,>= - 正则:
=~(匹配正则),!~(不匹配正则) - 包含:
in(包含),not in(不包含)
布尔操作:
and(与),or(或),nand(非与),xor(非或)
一元运算符:
!(取反)()(复合表达式),!()(对复合表达式结果取反)
2,常用的过滤器为:
- Grok 是 Logstash 最重要的插件,grok 是一个十分强大的 logstash filter 插件,他可以解析任何格式的文本,他是目前 logstash 中解析非结构化日志数据最好的方式。
- mutate:对字段进行转换。例如对字段进行删除、替换、修改、重命名等。
- drop:丢弃一部分events不进行处理。
- date:时间处理
mutate插件:使用最频繁的操作,可以对字段进行各种操作,比如重命名、删除、替换、更新等,主要参数如下:
- convert #类型转换
- gsub #字符串替换
- split/join/merge #字符串切割、数组合并为字符串、数组合并为数组
- rename #字段重命名
- update/replace #字段内容更新或替换
- remove_field #删除字段
filter { mutate { convert => { "local_port" => "integer" "bytes" => "integer" "latency_ms" => "integer" } rename => { "[host][name]" => "host" } remove_field => ["type","prospector","source","input","beat","version","@version","offset"] } }
drop插件:丢弃一部分events不进行处理,匹配筛选多余日志。
filter {
#dispatcher
if([message]=~ "DEBUG") or ([message]=~ "traceLogger") or ([message]=~ "^20.*\ WARN\ .*\ by\ regular\ expression.*"){
drop{}
}
#tsc
if([message]=~ ".*\ The\ HTTP\ headers\ are.*") or ([message]=~ "with Queue depth: 0$") or ([message]=~ "%$") or ([message]=~ "execute...$"){
drop{}
}
#tc
if([message]=~ "\[]$") or ([message]=~ "invoke:method=execute") {
drop{}
}
#等等
}
date:时间处理
处理2条不同格式时间日志示例如下:
2019-09-16 21:59:18.131 [TSC_MESSAGE] [INFO] [c.e.c.t.m.r.RemoteControllMessageResourceImpl] [csp] [Add message] [LB37722Z5KH038111] [OPERATION_SUCCESS] []
192.168.112.24 - - [16/Sep/2019:21:58:16 +0800] "GET /services/serviceconnection/ HTTP/1.1" 200 1836
date使用:
filter {
grok {
match => {"message" => "%{TIMESTAMP_ISO8601:access_time}"}
match => {"message" => "%{IP:ip}\s*%{DATA:a}\s*\[%{HTTPDATE:access_time}\]"}
}
date { # 这个才是真正的access发生时间,识别为记录的@timestamp
timezone => "Asia/Shanghai"
match => [ "access_time","ISO8601","dd/MMM/yyyy:HH:mm:ss Z"]
}
}
注:match => [ "access_time", "ISO8601"] } 注意:时区偏移量只需要用一个字母 Z 即可。
ISO8601 - 应解析任何有效的ISO8601时间戳 如:2019-09-16 21:59:18.131
dd/MMM/yyyy:HH:mm:ss Z - 应解析为16/Sep/2019:21:58:16 +0800的时间格式
date介绍:
就是将匹配日志中时间的key替换为@timestamp的时间,因为@timestamp的时间是日志送到logstash的时间,并不是日志中真正的时间。
Grok插件:
详细语法参照博客篇: https://www.cnblogs.com/zhangan/p/11395056.html
语法解释:
%{HOSTNAME},匹配请求的主机名
%{TIMESTAMP_ISO8601:time},代表时间戳
%{LOGLEVEL},代表日志级别
%{URIPATHPARAM},代表请求路径
%{DATA},代表任意数据
%{INT},代表字符串整数数字大小
%{NUMBER}, 可以匹配整数或者小数
%{IP}, 匹配ip
%{WORD}, 匹配请求的方式
%{GREEDYDATA},匹配所有剩余的数据
(?([\S+]*)),自定义正则
\s*或者\s+,代表多个空格
\S+或者\S*,代表多个字符
大括号里面:xxx,相当于起别名
(?<class_info>([\S+]*)), 自定义正则匹配多个字符
举例1,在日志文件中原生日志时间是这样子的:2019-03-19 13:08:07.782
重点是后面的”.782“,后面附加以毫秒为单位的。
那么grok插件中可以这样子定义匹配的规则:
grok {
match => {"message" => "%{TIMESTAMP_ISO8601:access_time}"}
}
举例2,操作如下:
[2019-08-22 12:25:51.441] [TSC_IHU] [ERROR] [c.e.c.t.i.t.s.IhuTsaUplinkServiceImpl] Activation/Bind uplink, query UserSession by Token failure!
grok {
match => {"message" => "\[%{TIMESTAMP_ISO8601:time}\]\s*%{DATA:name}\s*\[%{LOGLEVEL:level}\]\s*%{GREEDYDATA:data}"}
}
举例3,操作如下:
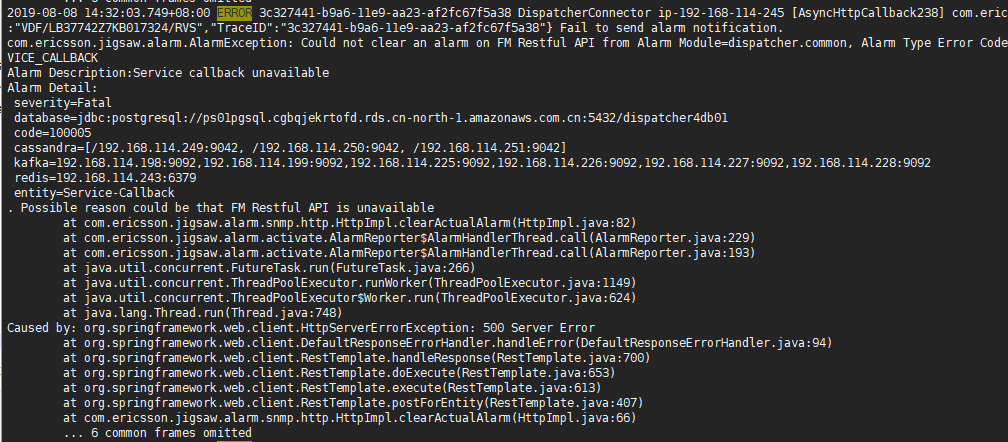
2019-09-12 14:16:36.320+08:00 INFO 930856f7-c78f-4f12-a0f1-83a2610b2dfc DispatcherConnector ip-192-168-114-244 [Mqtt-Device-1883-worker-18-1] com.ericsson.sep.dispatcher.api.transformer.v1.MessageTransformer {"TraceID":"930856f7-c78f-4f12-a0f1-83a2610b2dfc","clientId":"5120916600003466K4GA1059","username":"LB37622Z3KX609880"}
grok {
match => {"message" => "%{TIMESTAMP_ISO8601:access_time}\s*%{LOGLEVEL:level}\s*%{UUID:uuid}\s*%{WORD:word}\s*%{HOSTNAME:hostname}\s*\[%{DATA:work}\]\s*(?<api>([\S+]*))\s*(?<TraceID>([\S+]*))\s*%{GREEDYDATA:message_data}"}
}
举例4,操作如下:
192.168.125.138 - - [12/Sep/2019:14:10:58 +0800] "GET /backend/services/ticketRemind/query?cid=&msgType=1&pageSize=100&pageIndex=1&langCode=zh HTTP/1.1" 200 91
grok {
match => {"message" => "%{IP:ip}\s*%{DATA:a}\s*\[%{HTTPDATE:access_time}\]\s*%{DATA:b}%{WORD:method}\s*%{URIPATH:url}%{URIPARAM:param}\s*%{URIPROTO:uri}%{DATA:c}%{NUMBER:treaty}%{DATA:d}\s*%{NUMBER:status}\s*%{NUMBER:latency_millis}"}
}
举例5,操作如下:
[08/Nov/2019:11:40:24 +0800] tc-com.g-netlink.net - - 192.168.122.58 192.168.122.58 192.168.125.135 80 GET 200 /geelyTCAccess/tcservices/capability/L6T7944Z0JN427155 ?pageIndex=1&pageSize=2000&vehicleType=0 21067 17
grok { match => { "message"=> "\[%{HTTPDATE:access_time}\] %{DATA:hostname} %{DATA:username} %{DATA:fwd_for} %{DATA:remote_hostname} %{IP:remote_ip} %{IP:local_ip} %{NUMBER:local_port} %{DATA:method} %{DATA:status} %{DATA:uri} %{DATA:query} %{NUMBER:bytes} %{NUMBER:latency_ms}"} }
grok同时处理多种日志不同行的写法:
filter {
if [fields][log_topic] == "dispatcher-connector" {
grok {
match => {"message" => "%{TIMESTAMP_ISO8601:time}\s*%{LOGLEVEL:level}\s*%{UUID:uuid}\s*%{WORD:word}\s*%{HOSTNAME:hostname}\s*\[%{DATA:work}\]\s*(?<api>([\S+]*))\s*(?<TraceID>([\S+]*))\s*%{GREEDYDATA:message_data}"}
match => {"message" => "%{TIMESTAMP_ISO8601:time}\s*%{LOGLEVEL:level}\s*%{WORD:word}\s*%{HOSTNAME:hostname}\s*(?<TraceID>([\S+]*))\s*(?<api>([\S+]*))\s*(?<brackets>([\S+]*))\s*%{GREEDYDATA:message_data}"}
remove_field =>["message","time","level","uuid","word","hostname","brackets","work","api","TraceID"]
}
}
}
1.15 Elasticsearch 定期清理索引丶缓存及索引写入优化
1,ES数据定期删除
#!/bin/bash #es-index-clear #只保留20天内的日志索引 ip="192.168.1.211 192.168.1.212 192.168.1.213 192.168.1.214 192.168.1.215 192.168.1.216" LAST_DATA=`date -d "-20 days" "+%Y.%m.%d"` #删除上个月份所有的索引(根据自己的索引格式编写) for i in ${ip} do curl -XDELETE -uelastic:XleBzj3GmE http://${i}:9200/*-${LAST_DATA}.* echo "curl -XDELETE -uelastic:XleBzj3GmE http://${i}:9200/*-${LAST_DATA}.*" done
crontab -e添加定时任务:每天的凌晨清除索引。
0 1 * * * /search/odin/elasticsearch/scripts/es-index-clear.sh
2,ES定期清理cache
为避免fields data占用大量的jvm内存,可以通过定期清理的方式来释放缓存的数据。释放的内容包括field data, filter cache, query cache
curl -XPOST "ip:port/_cache/clear"
curl -XPOST -uelastic:Ericss0n "ip:port/_cache/clear"
crontab -e添加定时任务:每天的凌晨清除缓存
3,ES索引写入优化---修改elasticsearch映射模板——替换默认的logstash映射模板
使用kibana提供的ES的控制台获取logstash模板:GET _template/logstash
控制台导入如下 (修改logstash模板入es集群默认优化配置):
PUT _template/logstash { "version" : 60002, "index_patterns" : [ "logstash-*" ], "settings" : { "index" : { "refresh_interval" : "60s", "number_of_shards" : "5", "translog" : { "flush_threshold_size" : "1024mb", "sync_interval" : "180s", "durability" : "async" }, "number_of_replicas" : "1", "merge" : { "scheduler" : { "max_thread_count" : "1" }, "policy" : { "floor_segment" : "100mb", "segments_per_tier" : "20", "max_merged_segment": "100m" } } } }, "mappings" : { "dynamic_templates" : [ { "message_field" : { "path_match" : "message", "mapping" : { "norms" : false, "type" : "text" }, "match_mapping_type" : "string" } }, { "string_fields" : { "mapping" : { "norms" : false, "type" : "text", "fields" : { "keyword" : { "ignore_above" : 256, "type" : "keyword" } } }, "match_mapping_type" : "string", "match" : "*" } } ], "properties" : { "@timestamp" : { "type" : "date" }, "geoip" : { "dynamic" : true, "properties" : { "ip" : { "type" : "ip" }, "latitude" : { "type" : "half_float" }, "location" : { "type" : "geo_point" }, "longitude" : { "type" : "half_float" } } }, "@version" : { "type" : "keyword" } } }, "aliases" : { } }
4,修改集群分片数,默认只允许1000个分片,不免后期分片数不足丢失数据
curl -XPUT 'ip:9200/_cluster/settings' -H "Content-Type: application/json" -d '{"persistent":{"cluster":{"max_shards_per_node":10000}}}'
pattern="{"access_time":"%{yyyy-MM-dd'T'HH:mm:ss.SSSXXX}t","host_local":"%v","username":"%u","fwd_for":"%{x-forwarded-for}i","host_remote":"%h","ip_remote":"%a","ip_local":"%A","port":"%p","method":"%m","status":"%s","uri":"%U","qstr":"%q","bytes":%B,"latency":%D,"con_st":"%X"}"
