hbase和mapreduce开发 WordCount
代码:
/** * hello world by world 测试数据 * @author a * */ public class DefinedMapper extends Mapper<LongWritable, Text, Text, LongWritable>{ @Override protected void map(LongWritable key, Text value, Mapper<LongWritable, Text, Text, LongWritable>.Context context) throws IOException, InterruptedException { long num=1L; if(null!=value){ String strValue=value.toString(); String arrValue[]=strValue.split(" "); if(arrValue.length==4){ for(int i=0;i<arrValue.length;i++){ context.write(new Text(arrValue[i].toString()), new LongWritable(num)); } } } } }
public class DefinedReduce extends TableReducer{ @Override protected void reduce(Object arg0, Iterable values, Context arg2) throws IOException, InterruptedException { if(null!=values){ long num=0l; Iterator<LongWritable> it=values.iterator(); while(it.hasNext()){ LongWritable count=it.next(); num+=Long.valueOf(count.toString()); } Put put=new Put(String.valueOf(arg0).getBytes());//设置行键 put.add("context".getBytes(), "count".getBytes(), String.valueOf(num).getBytes()); arg2.write(arg0, put); } } }
package com.zhang.hbaseandmapreduce; import java.io.IOException; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.Path; import org.apache.hadoop.hbase.HBaseConfiguration; import org.apache.hadoop.hbase.HColumnDescriptor; import org.apache.hadoop.hbase.HTableDescriptor; import org.apache.hadoop.hbase.client.HBaseAdmin; import org.apache.hadoop.hbase.mapreduce.TableOutputFormat; import org.apache.hadoop.io.LongWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; public class HBaseAndMapReduce { public static void createTable(String tableName){ Configuration conf=HBaseConfiguration.create(); HTableDescriptor htable=new HTableDescriptor(tableName); HColumnDescriptor hcol=new HColumnDescriptor("context"); try { HBaseAdmin admin=new HBaseAdmin(conf); if(admin.tableExists(tableName)){ System.out.println(tableName+" 已经存在"); return; } htable.addFamily(hcol); admin.createTable(htable); System.out.println(tableName+" 创建成功"); } catch (IOException e) { e.printStackTrace(); } } public static void main(String[] args) { String tableName="workCount"; Configuration conf=new Configuration(); conf.set(TableOutputFormat.OUTPUT_TABLE, tableName); conf.set("hbase.zookeeper.quorum", "192.168.177.124:2181"); createTable(tableName); try { Job job=new Job(conf); job.setJobName("hbaseAndMapReduce"); job.setJarByClass(HBaseAndMapReduce.class);//jar的运行主类 job.setOutputKeyClass(Text.class);//mapper key的输出类型 job.setOutputValueClass(LongWritable.class);//mapper value的输出类型 job.setMapperClass(DefinedMapper.class); job.setReducerClass(DefinedReduce.class); job.setInputFormatClass(org.apache.hadoop.mapreduce.lib.input.TextInputFormat.class); job.setOutputFormatClass(TableOutputFormat.class); FileInputFormat.addInputPath(job, new Path("/tmp/dataTest/data.text")); System.exit(job.waitForCompletion(true) ? 0:1); } catch (Exception e) { e.printStackTrace(); } } }
打成jar包,放到linux主机服务器上
执行下面命令
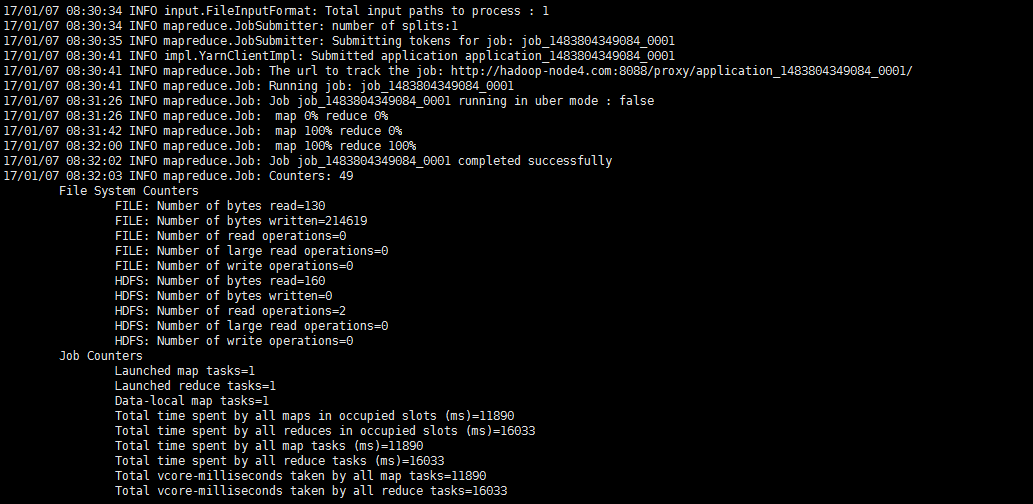
[root@node4 Desktop]# hadoop jar hbaseAndMapR.jar com.zhang.hbaseandmapreduce.HBaseAndMapReduce
遇到问题:
注意:
job.setOutputKeyClass(Text.class); job.setOutputValueClass(LongWritable.class);
这两行代码设置的key,value类型,是设置mapper的输出key和value.
---------------------------------------------------------------------
》1:出现了三种异常
这个是在hadoop-root-namenode-node4.out出现的异常
(1)2017-01-07 06:53:33,493 INFO org.apache.hadoop.yarn.server.nodemanager.containermanager.monitor.ContainersMonitorImpl: Memory usage of ProcessTree 14615 for container-id container_1483797859000_0001_01_000001: 80.9 MB of 2 GB physical memory used; 1.7 GB of 4.2 GB virtual memory used
(2)Detected pause in JVM or host machine (eg GC): pause of approximately 3999ms
(3)AttemptID:attempt_1462439785370_0055_m_000001_0 Timed out after 600 secs
同时hbase的日志中也出现异常
MB of 1 GB physical memory used; 812.3 MB of 2.1 GB virtual memory used
从日志上这些日志都是在说内存的问题,在看了hadoop的异常日志发现内存挺正常的,所以觉得应该不是hadoop的内存不够才导致出现这种异常,但是发现hadoop有超时的异常,所以我修改了mapper的超时时间;既然不是hadoop的内存问题那就应该是hbase的内存问题了,所以我修改了hbase的配置
<property>
<name>mapred.task.timeout</name>
<value>180000</value>
</property>
在habse--env.sh 修改了以下内容
# The maximum amount of heap to use. Default is left to JVM default. export HBASE_HEAPSIZE=2G # Uncomment below if you intend to use off heap cache. For example, to allocate 8G of # offheap, set the value to "8G". export HBASE_OFFHEAPSIZE=2G
再次运行成功


 浙公网安备 33010602011771号
浙公网安备 33010602011771号