4
1.用图与自己的话,简要描述Hadoop起源与发展阶段。
从与谷歌系统的关系,关键时间节点,1.x,2.x与3.x的区别,不同公司发行版本等方面来讲。
(1)Hadoop最早起源于lucene下的Nutch。Nutch的设计目标是构建一个大型的全网搜索引擎,包括网页抓取、索引、查询等功能,但随着抓取网页数量的增加,遇到了严重的可扩展性问题——如何解决数十亿网页的存储和索引问题。
(2)2003年、2004年谷歌发表的三篇论文为该问题提供了可行的解决方案。
——分布式文件系统(GFS),可用于处理海量网页的存储
——分布式计算框架MAPREDUCE,可用于处理海量网页的索引计算问题。
——分布式的结构化数据存储系统Bigtable,用来处理海量结构化数据。
(3) Doug Cutting基于这三篇论文完成了相应的开源实现HDFS和MAPREDUCE,并从Nutch中剥离成为独立项目HADOOP,到2008年1月,HADOOP成为Apache顶级项目(同年,cloudera公司成立),迎来了它的快速发展期。
从狭义上来说,Hadoop就是单独指代Hadoop这个软件(HDFS+MAPREDUCE)
从广义上来说,Hadoop指代大数据的一个生态圈(Hadoop生态圈),包括很多其他的软件。

Hadoop的历史版本
0.x系列版本:Hadoop当中最早的一个开源版本,在此基础上演变而来的1.x以及2.x的版本
1.x版本系列:Hadoop版本当中的第二代开源版本,主要修复0.x版本的一些bug等
2.x版本系列:架构产生重大变化,引入了yarn平台等许多新特性

2.用图与自己的话,简要描述名称节点、第二名称节点、数据节点的主要功能及相互关系
数据节点是分布式文件系统HDFS的工作节点,负责数据的存储和读取,会根据客户端或者是名称节点的调度来进行数据的存储和检索,并且向名称节点定期发送自己所存储的块的列表
在HDFS中,名称节点(NameNode)负责管理分布式文件系统的命名空间(Namespace),保存了两个核心的数据结构,即FsImage和EditLog
第二名称节点:是HDFS架构中的一个组成部分,它是用来保存名称节点中对HDFS 元数据信息的备份,并减少名称节点重启的时间。
SecondaryNameNode一般是单独运行在一台机器上
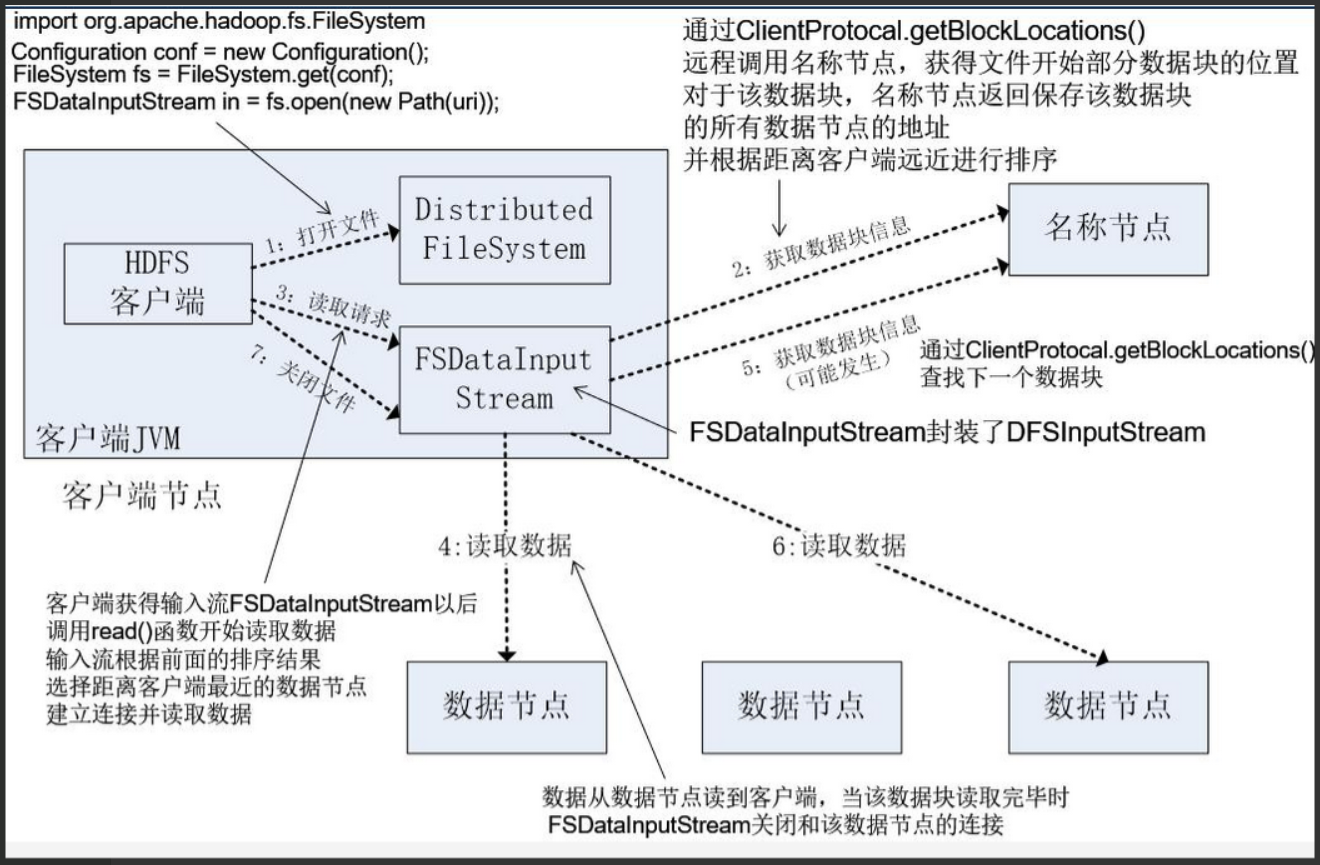
3.分别从以下这些方面,梳理清楚HDFS的 结构与运行流程,以图的形式描述。
- 客户端与HDFS
- 客户端读
- 客户端写
- 数据结点与集群
- 数据结点与名称结点
- 名称结点与第二名称结点
- 数据结点与数据结点
- 数据冗余
- 数据存取策略
- 数据错误与恢复

3.分别从以下这些方面,梳理清楚HDFS的 结构与运行流程,以图的形式描述。
- 客户端与HDFS
- 客户端读
- 客户端写
- 数据结点与集群
- 数据结点与名称结点
- 名称结点与第二名称结点
- 数据结点与数据结点
- 数据冗余
- 数据存取策略
- 数据错误与恢复
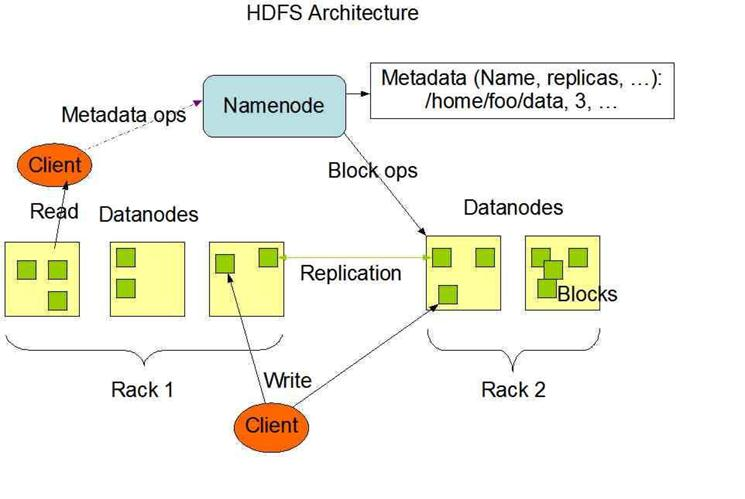
- 客户端与HDFS
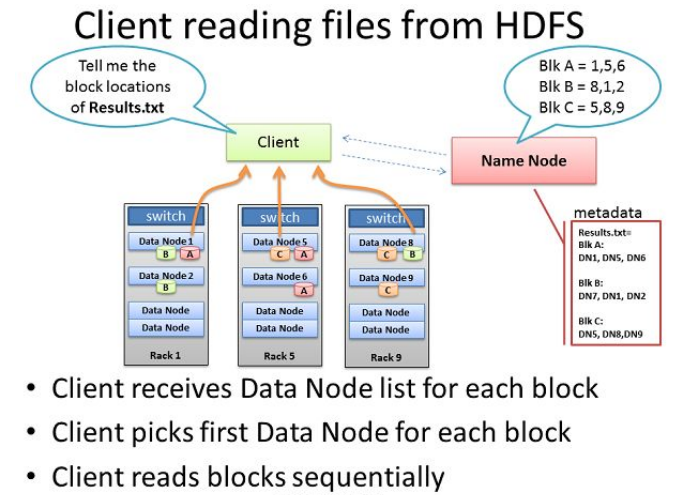
- 客户端读
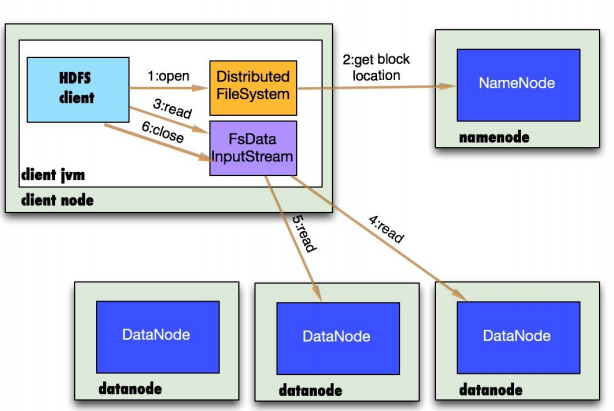
- 客户端写
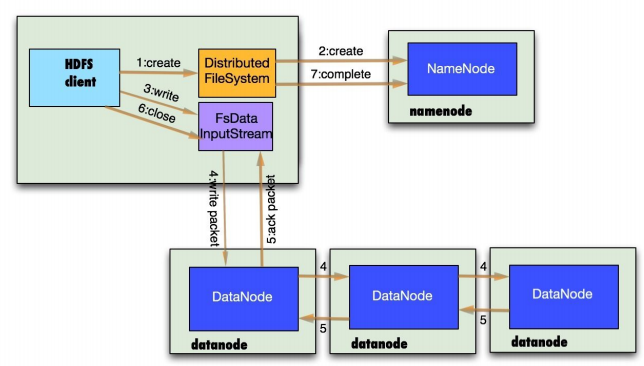
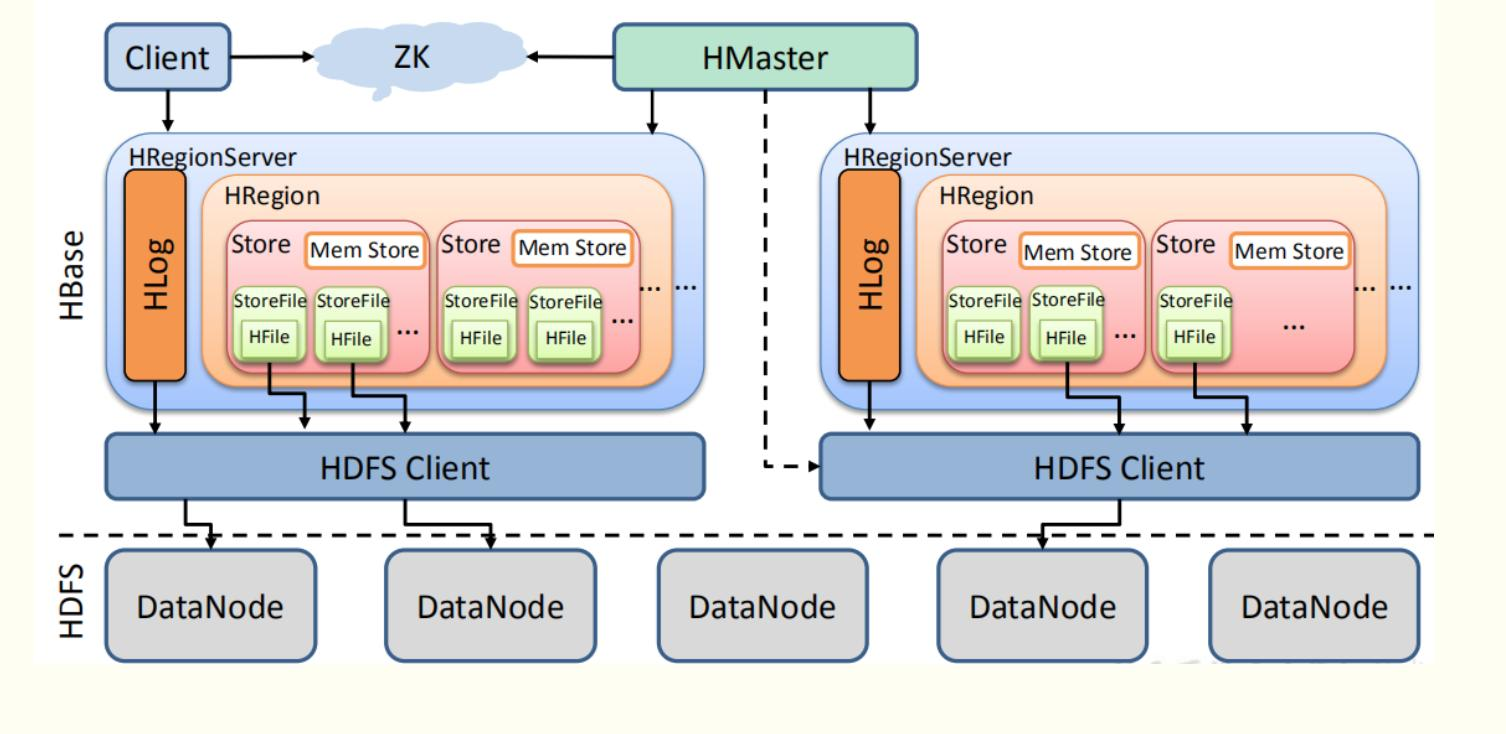
4.梳理HBase的结构与运行流程,以用图与自己的话进行简要描述,图中包括以下内容:
(1)Master主服务器的功能
①为Region server分配region
②负责Region server的负载均衡
③发现失效的Region server并重新分配其上的region。
④HDFS上的垃圾文件回收。
⑤处理schema更新请求。
(2)Region服务器的功能
①维护master分配给他的region,处理对这些region的io请求。
②负责切分正在运行过程中变的过大的region。
(3)Zookeeper协同的功能
①保证任何时候,集群中只有一个master
②存储所有Region的寻址入口
③实时监控Region server的上线和下线信息。并实时通知给master
④存储HBase的schema和table元数据
(4)Client客户端的请求流程
写流程
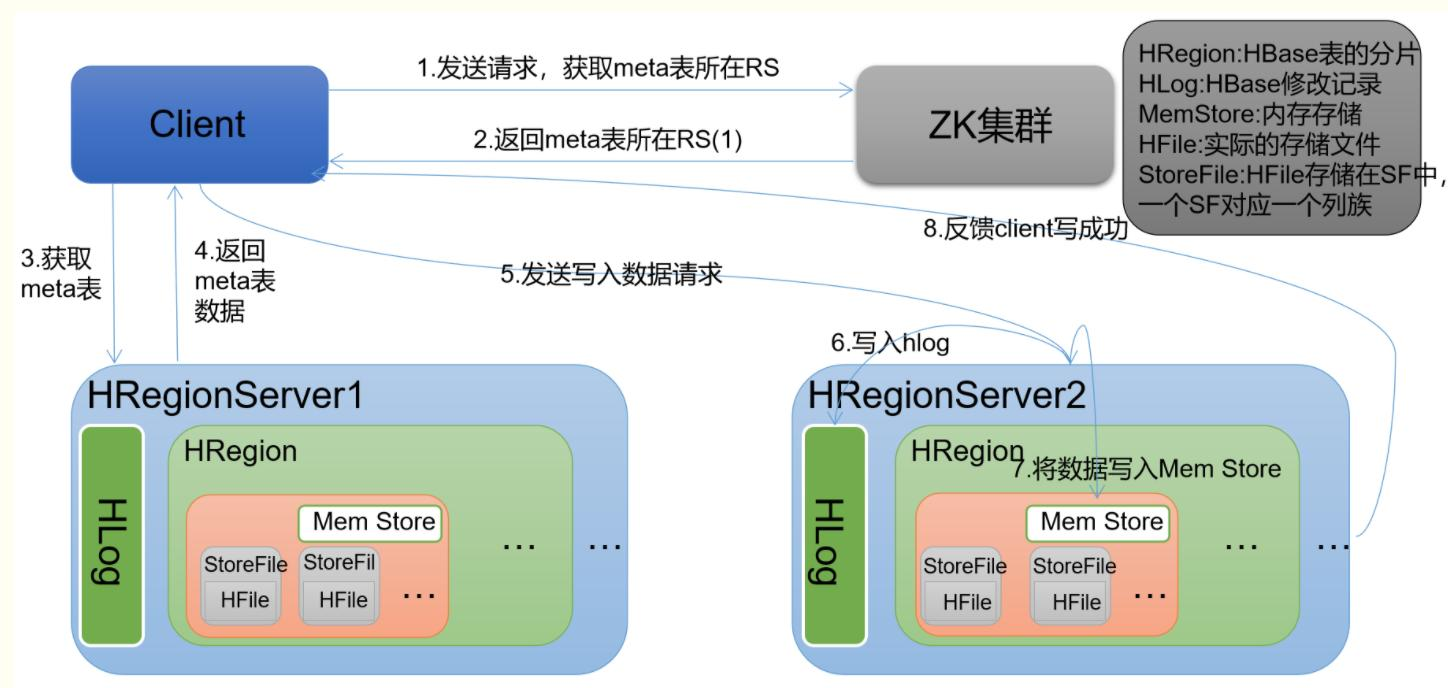
读流程

(5)四者之间的相系关系
(6)与HDFS的关联
5.理解并描述Hbase表与Region与HDFS的关系。
1)一个HBase表被划分成多个Region;
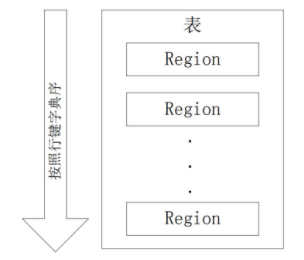
一个Region会分裂成多个新的Region;

不同的Region可以分布在不同的Region服务器上;

6.理解并描述Hbase的三级寻址。
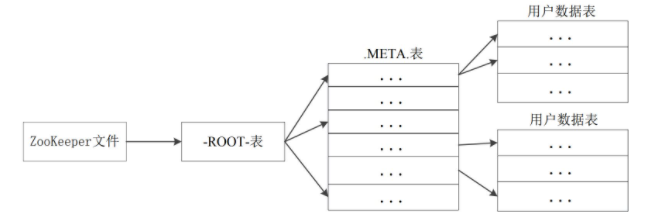
7.假设.META.表的每行(一个映射条目)在内存中大约占用1KB,并且 ,通过HBase的三级寻址方式,理论上Hbase的数据表最大有多大?
一个-ROOT-表最多只能有一个Region,也就是最多只能有2GB,按照每行(一个映射条目)占用1KB内存计算,2GB空间可以容纳2GB/1KB=231行,也就是说,一个-ROOT-表可以寻址231个.META.表的Region。
同理,每个.META.表的 Region可以寻址的用户数据表的Region个数是2GB/1KB=231。
最终,三层结构可以保存的Region数目是(2GB/1KB) × (2GB/1KB) = 2100个Region,即理论上Hbase表最大273G。
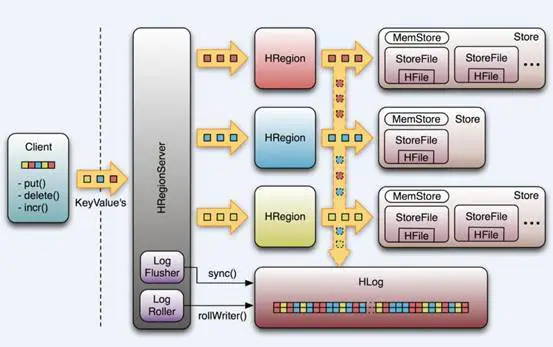
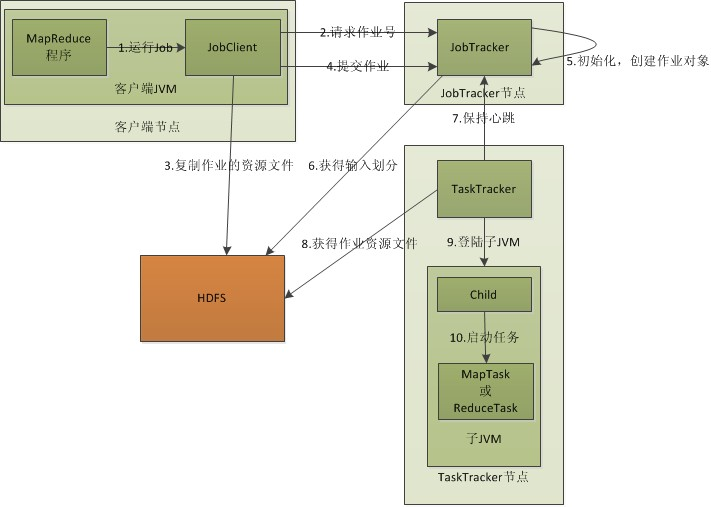
8.MapReduce的架构,各部分的功能,以及和集群其他组件的关系。
同HDFS一样,Hadoop MapReduce也采用了Master/Slave(M/S)架构,主要由4个组件构成:Client、JobTracker、TaskTracker和Task。

1)Client:
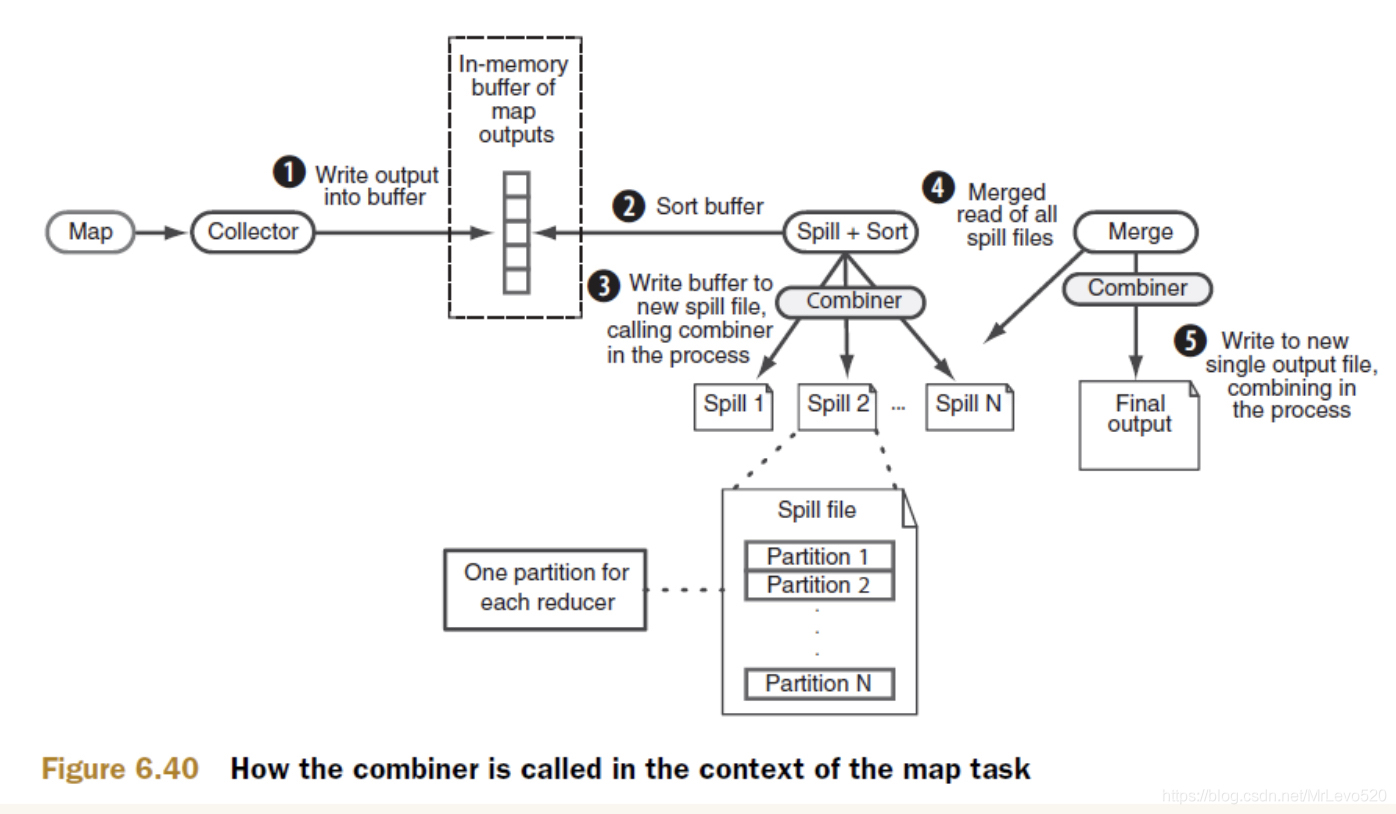
9.MapReduce的工作过程,用自己词频统计的例子,将split, map, partition,sort,spill,fetch,merge reduce整个过程梳理并用图形表达出来。
MapReduce程序运行流程分析
词频分析:
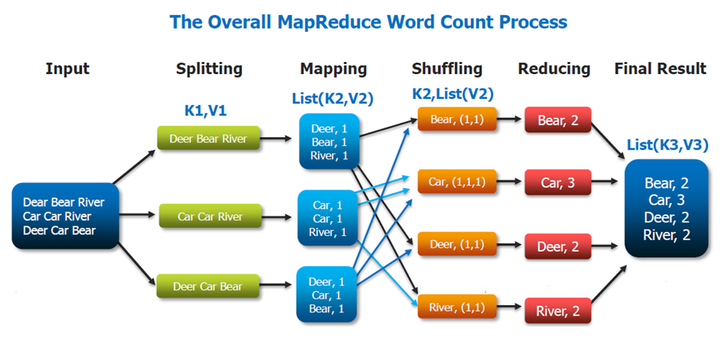
MapTask并行度决定机制: 一个job的map阶段MapTask并行度(个数),由客户端提交job时的切片个数决定。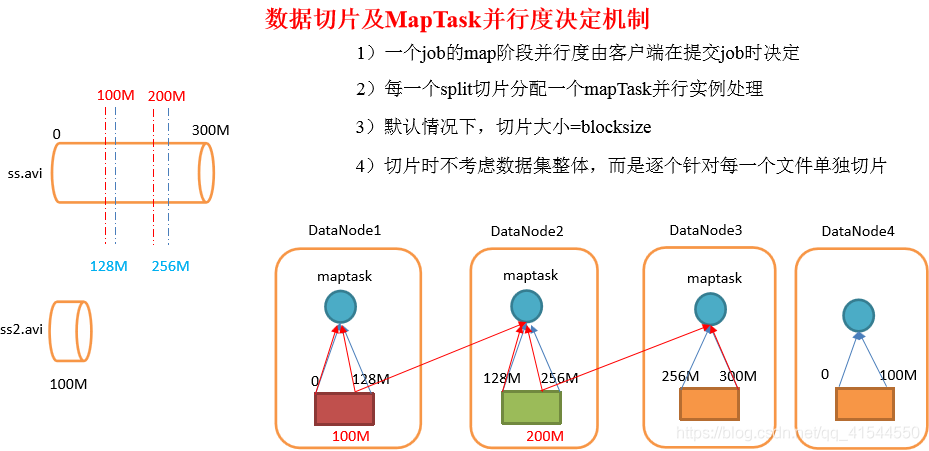
shuffle机制:Mapreduce确保每个reducer的输入都是按键排序的。系统执行排序的过程(即将map输出作为输入传给reducer)称为shuffle。


reduce端
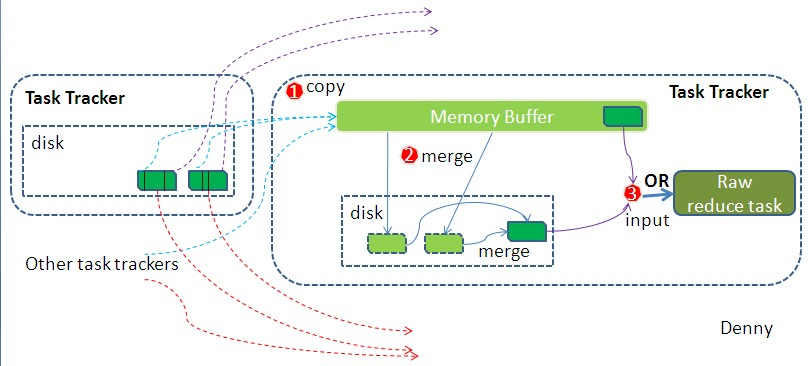
Combiner合并