SQL Server 索引碎片维护
一、产生原因及影响
索引是数据库引擎中针对表(有时候也针对视图)建立的特别数据结构,用来帮助查找和整理数据,它的重要性体现在能够使数据库引擎快速返回查询结果。当对索引所在的基础数据表进行增删改时,若存储的数据进行了不适当的跨页(SQL Server中存储的最小单位是页,页是不可再分的),就会导致索引碎片的产生。随着索引碎片的不断增多,查询响应时间就会变慢,性能也因此而下降。要解决这个问题,可以通过重新生成或重新组织索引来解决。
二、碎片分类
2.1、外部碎片
当索引页不在逻辑顺序上时就会产生外部碎片。索引创建时,索引键按照逻辑顺序放在一组索引页上。当新数据插入索引时,新的键可能放在存在的键之间。为了让新的键按照正确的顺序插入,可能会创建新的索引页来存储需要移动的那些存在的键。这些新的索引页通常物理上不会和那些被移动的键原来所在的页相邻。创建新页的过程会引起索引页偏离逻辑顺序。
2.2、内部碎片
当索引页没有用到最大量时就产生了内部碎片。虽然在一个有频繁数据插入的应用程序里这也许有帮助,然而设置一个fill factor(填充因子)会在索引页上留下空间,服务器内部碎片会导致索引尺寸增加,从而在返回需要的数据时要执行额外的读操作。这些额外的读操作会降低查询的性能。
三、维护方法
1、删除索引并重建。
2、使用DROP_EXISTING语句重建索引。
3、使用ALTER INDEX REBUILD重新生成索引。(推荐)
4、使用ALTER INDEX REORGANIZE重新组织索引。(推荐)
四、注意事项
| 碎片率 | 采用方法 |
| >30% | ALTER INDEX REBUILD WITH(ONLINE = ON) |
| >5% 且 <=30% | ALTER INDEX REORGANIZE |
重新生成索引可以联机执行,也可以脱机执行。
重新组织索引始终联机执行。这些值提供了一个大致指导原则,用于确定应在ALTER INDEX REORGANIZE和ALTER INDEX REBUILD之间进行切换的点。不过,实际值可能会随情况而变化,必须要通过试验来确定最适合您环境的阈值。
非常低的碎片级别(小于5%)不应通过这些命令来解决,因为删除如此少量的碎片所获得的收益始终远低于重新生成或重新组织索引的开销。
切记:所有索引碎片维护一定要在凌晨(非业务高峰期间)进行!!!
五、优化指导原则
5.1、如何知道是否发生了索引碎片?
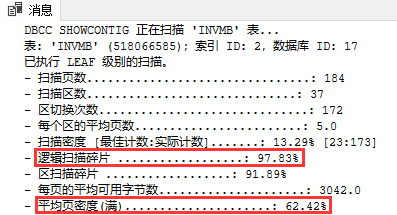
在SQL Server数据库中,可以通过DBCC SHOWCONTIG WITH ALL_INDEXES或DBCC SHOWCONTIG(表ID或者表名) WITH ALL_INDEXES来检查索引碎片情况。

--方法一
--目标数据库
USE DB_NAME
--创建变量指定要查看的表
DECLARE @TABLE_ID INT
SET @TABLE_ID=OBJECT_ID('TABLE_NAME')
--执行
DBCC SHOWCONTIG(@TABLE_ID) WITH ALL_INDEXES
--方法二
USE DB_NAME
DBCC SHOWCONTIG('TABLE_NAME') WITH ALL_INDEXES
5.2、索引碎片判断标准
通过对逻辑扫描碎片(过高)、平均页密度(满)(过低)的结果分析,判定是否需要进行索引处理,如下所示:
逻辑扫描碎片 ..................:97.83% 该百分比应该在0%到10%之间,高了则说明有外部碎片。
平均页密度(满) ..................:62.42% 该百分比应该尽可能靠近100%,低了则说明有外部碎片。
六、优化实践
6.1、手动方式
第一步:查询数据库所有表的索引信息。
SELECT
OBJECT_NAME( B.OBJECT_ID ) 表名,
B.NAME 索引名称,
A.INDEX_TYPE_DESC 索引类型,
ROUND( A.AVG_FRAGMENTATION_IN_PERCENT, 2 ) 碎片率
FROM
sys.dm_db_index_physical_stats ( DB_ID( ), NULL, NULL, NULL, NULL ) A
INNER JOIN sys.indexes B ON A.OBJECT_ID = B.OBJECT_ID
AND A.INDEX_ID= B.INDEX_ID
WHERE
1 = 1
AND A.AVG_FRAGMENTATION_IN_PERCENT> 30
-- AND A.AVG_FRAGMENTATION_IN_PERCENT>5 AND A.AVG_FRAGMENTATION_IN_PERCENT<=30
ORDER BY
OBJECT_NAME( B.OBJECT_ID ),
A.AVG_FRAGMENTATION_IN_PERCENT DESC
第二步:生成数据库所有表的索引处理的SQL语句。
SELECT
OBJECT_SCHEMA_NAME( B.OBJECT_ID ) 架构,
OBJECT_NAME( B.OBJECT_ID ) 表名,
B.NAME 索引名,
ROUND( A.AVG_FRAGMENTATION_IN_PERCENT, 2 ) 碎片率,
CASE
WHEN A.AVG_FRAGMENTATION_IN_PERCENT> 30 THEN
N'重新生成索引' ELSE N'重新组织索引'
END 处理方式,
'ALTER INDEX ' + QUOTENAME( B.NAME ) + ' ON ' + QUOTENAME( OBJECT_SCHEMA_NAME( B.OBJECT_ID ) ) + '.' + QUOTENAME( OBJECT_NAME( B.OBJECT_ID ) ) + ' ' +
CASE
WHEN A.AVG_FRAGMENTATION_IN_PERCENT> 30 THEN
'REBUILD' ELSE 'REORGANIZE'
END 生成SQL语句
FROM
sys.dm_db_index_physical_stats ( DB_ID( ), NULL, NULL, NULL, NULL ) A
INNER JOIN sys.indexes B ON A.OBJECT_ID = B.OBJECT_ID
AND A.INDEX_ID= B.INDEX_ID
WHERE
A.AVG_FRAGMENTATION_IN_PERCENT> 5
AND B.INDEX_ID> 0
AND OBJECT_NAME( B.OBJECT_ID ) IN ( 'TimeDetails' ) --指定表
ORDER BY
CASE
WHEN A.AVG_FRAGMENTATION_IN_PERCENT> 30 THEN
N'重新生成索引' ELSE N'重新组织索引'
END,
OBJECT_NAME( B.OBJECT_ID ),
B.INDEX_ID
批量整理索引碎片
SET NOCOUNT ON; DECLARE @objectid INT; DECLARE @indexid INT; DECLARE @partitioncount bigint; DECLARE @schemaname nvarchar ( 130 ); DECLARE @objectname nvarchar ( 130 ); DECLARE @indexname nvarchar ( 130 ); DECLARE @partitionnum bigint; DECLARE @partitions bigint; DECLARE @frag FLOAT; DECLARE @command nvarchar ( 4000 ); -- Conditionally select tables and indexes from the sys.dm_db_index_physical_stats function -- and convert object and index IDs to names. SELECT object_id AS objectid, index_id AS indexid, partition_number AS partitionnum, avg_fragmentation_in_percent AS frag INTO #work_to_do FROM sys.dm_db_index_physical_stats ( DB_ID( ), NULL, NULL, NULL, 'LIMITED' ) WHERE avg_fragmentation_in_percent > 10.0 AND index_id > 0; -- Declare the cursor for the list of partitions to be processed. DECLARE partitions CURSOR FOR SELECT * FROM #work_to_do; -- Open the cursor. OPEN partitions; -- Loop through the partitions. WHILE ( 1 = 1 ) BEGIN; FETCH NEXT FROM partitions INTO @objectid, @indexid, @partitionnum, @frag; IF @@FETCH_STATUS < 0 BREAK; SELECT @objectname = QUOTENAME( o.name ), @schemaname = QUOTENAME( s.name ) FROM sys.objects AS o JOIN sys.schemas AS s ON s.schema_id = o.schema_id WHERE o.object_id = @objectid; SELECT @indexname = QUOTENAME( name ) FROM sys.indexes WHERE object_id = @objectid AND index_id = @indexid; SELECT @partitioncount = COUNT ( * ) FROM sys.partitions WHERE object_id = @objectid AND index_id = @indexid; -- 30 is an arbitrary decision point at which to switch between reorganizing and rebuilding. IF @frag < 30.0 SET @command = N'ALTER INDEX ' + @indexname + N' ON ' + @schemaname + N'.' + @objectname + N' REORGANIZE'; IF @frag >= 30.0 SET @command = N'ALTER INDEX ' + @indexname + N' ON ' + @schemaname + N'.' + @objectname + N' REBUILD'; IF @partitioncount > 1 SET @command = @command + N' PARTITION=' + CAST ( @partitionnum AS nvarchar ( 10 ) ); EXEC ( @command ); PRINT N'Executed: ' + @command; END; -- Close and deallocate the cursor. CLOSE partitions; DEALLOCATE partitions; -- Drop the temporary table. DROP TABLE #work_to_do; GO
七、更新统计信息
作用:UPDATE STATISTICS更新统计信息来提高查询效率。建议放在索引碎片计划任务执行完成之后进行。
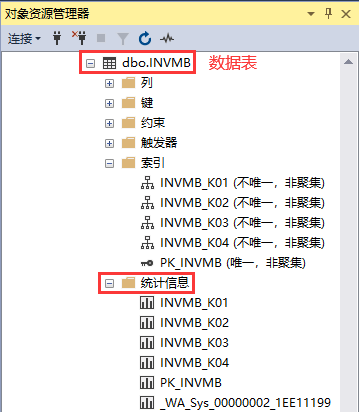
查看:查看某个表的统计信息,可以在SSMS下面查看。
执行:
--方法一:UPDATE STATISTICS 表名 UPDATE STATISTICS INVMB --方法二:执行存储过程SP_UPDATESTATS(更新所有表) EXEC sp_updatestats
原文:https://www.cnblogs.com/atomy/p/15268589.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号