UI自动化(一)
一、Selenium
Selenium是非常优秀的WEB(UI)自动化测试框架;selenium=WevbDriver+Selenium
最新的版本是Selenium4.x;
Selenium支持主流的浏览器自动化测试,具体是Chrome,IE,Firefox等浏览器
Selenium也是支持主流的开发语言,如Python,Java,Net,PHP
二、环境搭建
1、google浏览器
A、安装Selenium的库,命令为:pip3 install selenium
B、按照Google浏览器
C、按照Google浏览器驱动
2、Chrome浏览器
A、安装Selenium的库,命令为:pip3 install selenium
B、按照Chrome浏览器
C、按照Chrome浏览器驱动
3、安装Chrome浏览器驱动
A、查看Chrome浏览器版本;
B、到淘宝源下载与浏览器匹配的Driver;
C、下载成功后,进行解压,并且以管理员身份执行;
D、把这个driver放到Python的安装目录下。
4、具体安装步骤
A、查看浏览器版本号
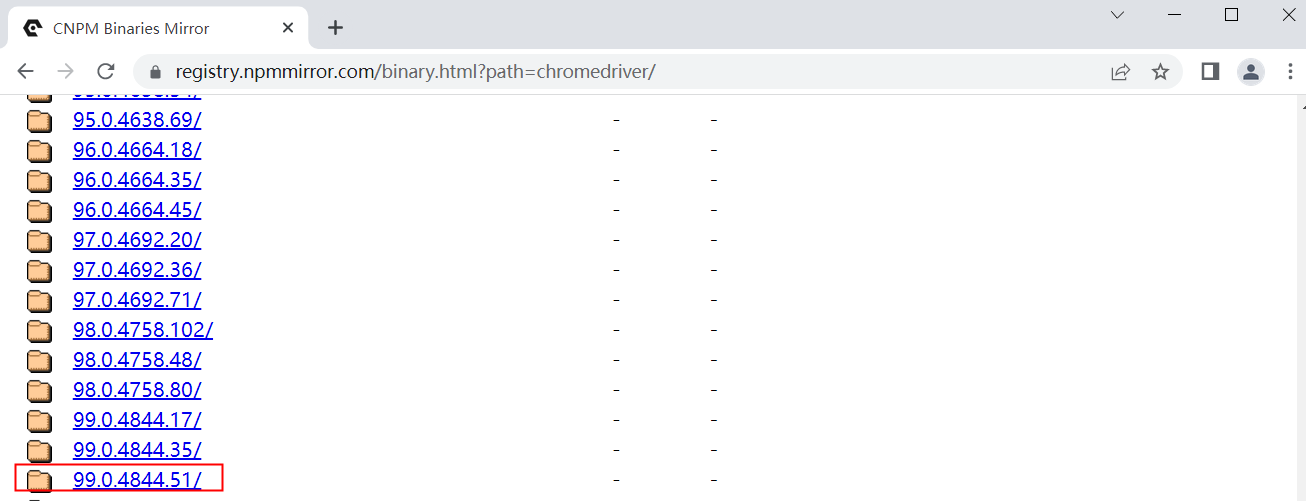
B、搜索淘宝源(网址为:https://registry.npmmirror.com/binary.html?path=chromedriver/)

C、选择距版本最接近的版本,点击进入,找到win文件,点击下载,得到压缩文件chromedriver_win32.zip
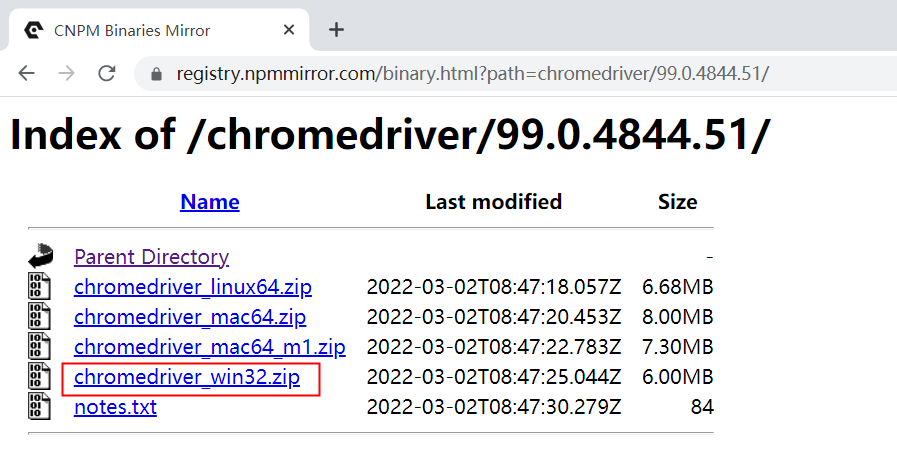
D、下载成功后解压,运行该文件chromedriver.exe。


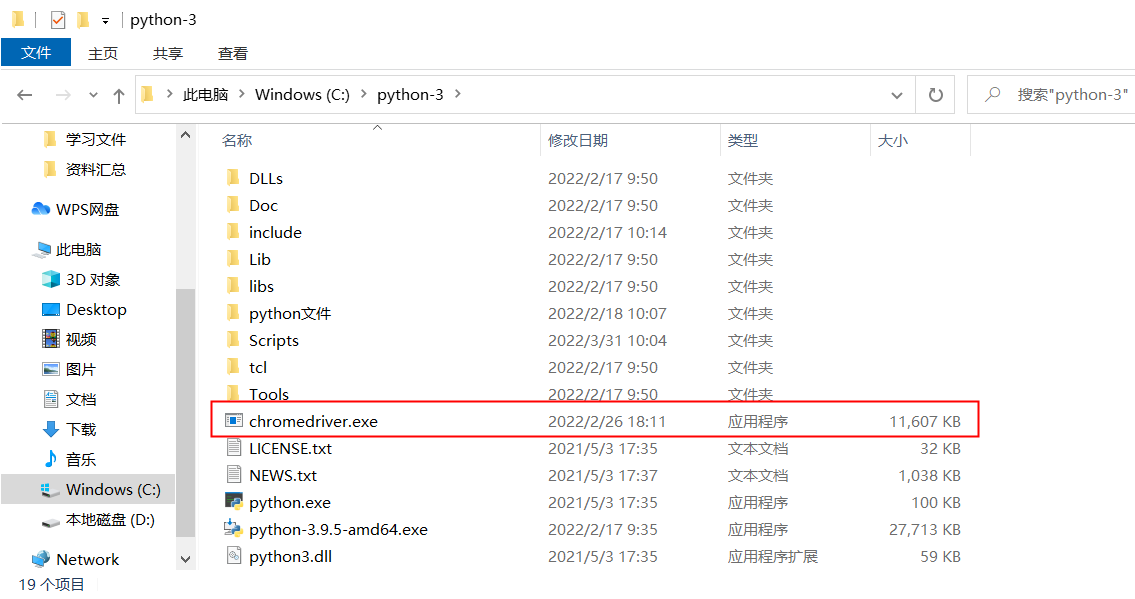
E、运行成功后,将该文件复制入python-3文件夹里(python环境文件里)
三、WEB自动化测试(理论)
1、有关运行错误的问题
如果测试过程中出现问题,则是以下两点原因:
A、安装版本和浏览器版本不符合
B、安装环境有问题
2、有关面试问题
css与xpath的区别
css选择是依据页面的数据样式定位的,有标签选择, 类选择, id选择, 或者他们的交并集, 除此之外没有其他的辅助元素了;
而xpath是路径表达式,所有元素和内容都可以成为路径的一部分.
两种定位方式功能基本一致, 但是xpath明显更强大, 只是xpath写起来较复杂,css写起来容易些
3、元素属性(重点)
元素属性的方法有以下几种:
ID = "id":ID是不能为1的
NAME = "name"
CLASS_NAME = "class name"
XPATH = "xpath"
CSS_SELECTOR = "css selector"
LINK_TEXT = "link text":超链接
PARTIAL_LINK_TEXT = "partial link text":超链接,但是模糊搜索
TAG_NAME = "tag name"注意:
操作浏览器是通过webdriver进行操作的,而因为webdriver操作浏览器的前提是需要定位到被操作的元素属性,之后就可以对浏览器做各种操作
4、查询元素属性的值
元素属性的具体数据需要查询,如图所示
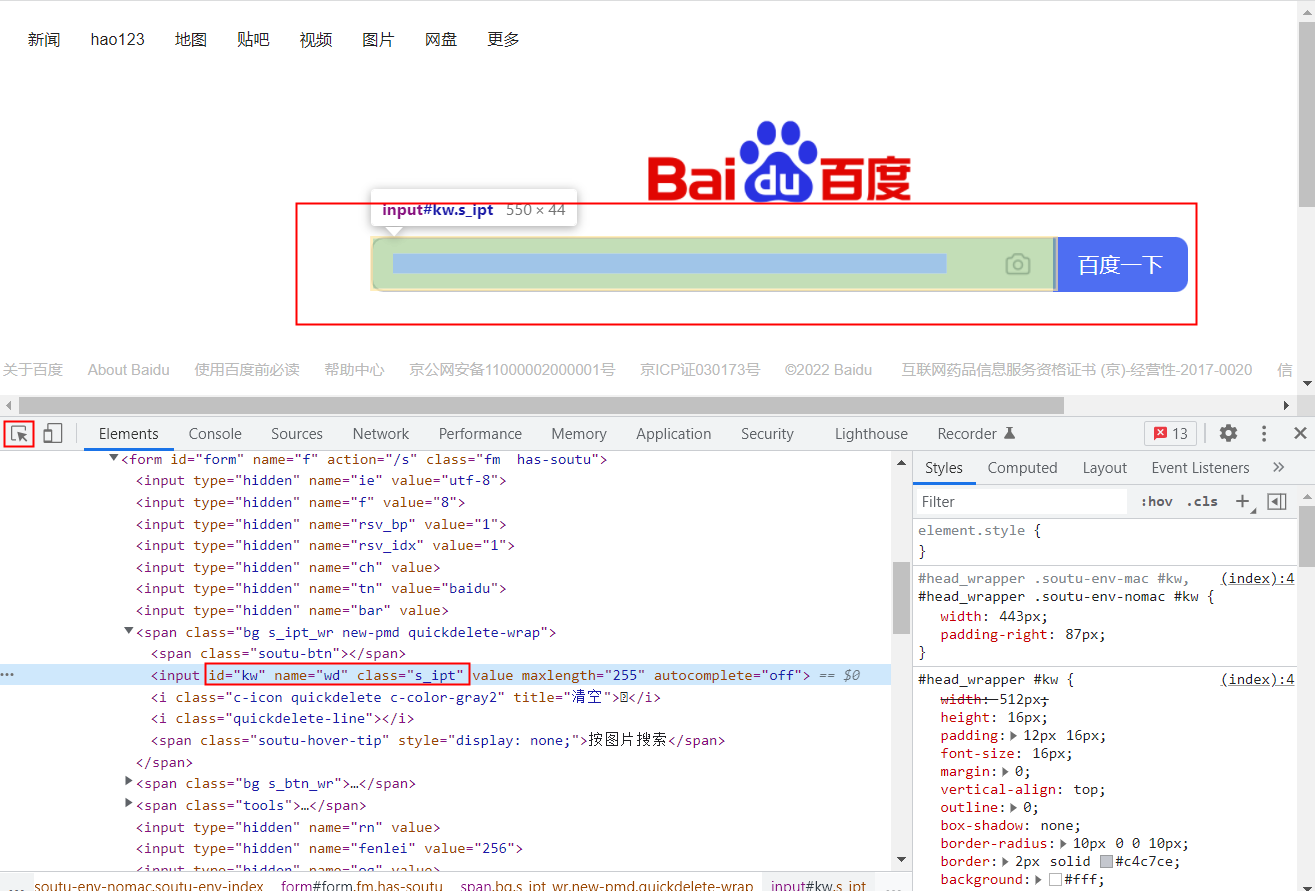
5、元素属性css和xpath
当你使用id,那么,class_name都定义不到的时候,这时考虑使用css or xpath
其中:
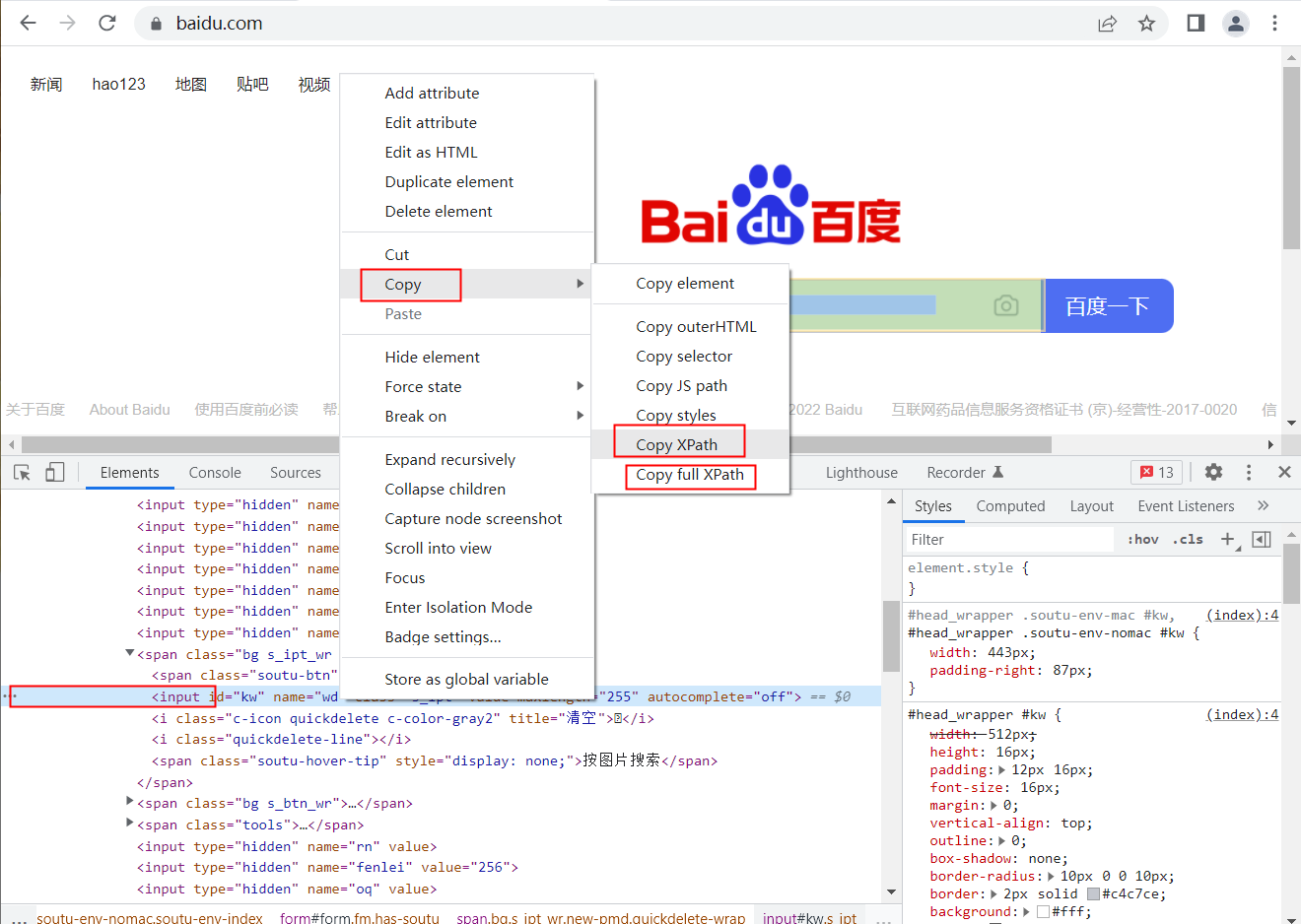
Xpath的两种类型:
A、Copy full Xpath:/html/body/div[1]/div[1]/div[5]/div/div/form/span[1]/input
B、Copy Xpath://*[@id="kw"]
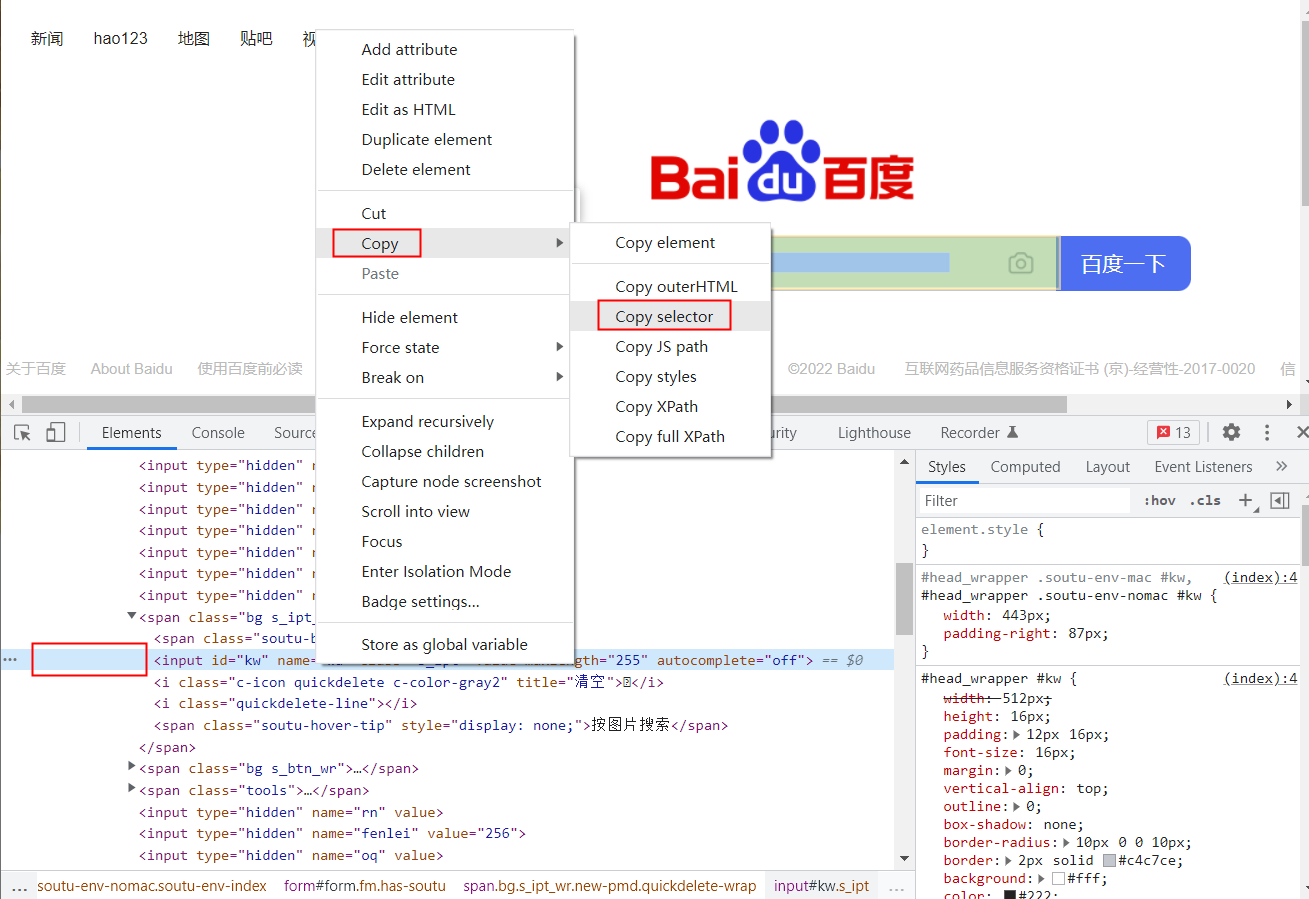
css类型(一种)
Copy selector:#kw
6、元素定位的分类
1、单个元素定位
2、多个元素定位
A、多个元素定位指的是元素的属性都一致,
B、它返回的是列表,那么这时候可以根据列表的索引来定位元素属性
注意:
不管是单个元素定位还是多个元素定位,它的方法都是8种,具体见上文
7、多窗口的解决思路
A、先打开当前页面
B、然后获取当前页面放在一个变量中
C、打开新的页面
D、获取所有页面并且放在一个变量中
E、循环所有页面,判断如果不是当前,那么就是在新的页面
四、WEB自动化测试(实战)
前缀:类与time的调用
import time
from selenium import webdriver1、测试指定网址
#指定浏览器
driver=webdriver.Chrome()
#对webdriver进行实例化,并指定测试网址
driver.get('http://www.baidu.com')
#休眠3秒
time.sleep(3)
#关闭浏览器
driver.quit()2、元素属性ID
driver=webdriver.Chrome()
driver.get('http://www.baidu.com')
#对元素id进行定位,并输入内容‘zhangli’
driver.find_element_by_id('kw').send_keys('zhangli')
time.sleep(3)
driver.quit()3、元素属性class_name
driver=webdriver.Chrome()
driver.get('http://www.baidu.com')
#对元素class_name进行定位,并输入内容‘zhangli’
driver.find_element_by_class_name('s_ipt').send_keys('zhangli')
time.sleep(3)
driver.quit()4、元素属性name
driver=webdriver.Chrome()
driver.get('http://www.baidu.com')
#对元素name进行定位,并输入内容‘zhangli’
driver.find_element_by_name('wd').send_keys('zhangli')
time.sleep(3)
driver.quit()5、元素属性Xpath
#第一种方法:Xpath
driver=webdriver.Chrome()
driver.get('http://www.baidu.com')
#对元素Xpath进行定位,并输入内容‘zhangli’
driver.find_element_by_xpath('//*[@id="kw"]').send_keys('ZHANGLI')
time.sleep(3)
driver.quit()
#第二种方法:fullXpath
driver=webdriver.Chrome()
driver.get('http://www.baidu.com')
#对元素Xpath进行定位,并输入内容‘zhangli’
driver.find_element_by_xpath('/html/body/div[1]/div[1]/div[5]/div/div/form/span[1]/input').send_keys('zhangli')
time.sleep(3)
driver.quit()6、元素属性css selector
driver=webdriver.Chrome()
driver.get('http://www.baidu.com')
#对元素css进行定位,并输入内容‘zhangli’
driver.find_element_by_css_selector('#kw').send_keys('zhangli')
time.sleep(3)
driver.quit()css selector7、元素属性:超链接link_text
driver=webdriver.Chrome()
driver.get('http://www.baidu.com')
#对元素link_text进行定位,并打开
driver.find_element_by_link_text('新闻').click()
time.sleep(3)
driver.quit()8、元素属性:超链接(模糊)partial_link_text
driver=webdriver.Chrome()
driver.get('http://www.baidu.com')
#对元素partial_link_text进行定位,并打开
driver.find_element_by_partial_link_text('图').click()
time.sleep(3)
driver.quit()
9、元素属性:tag_name
driver=webdriver.Chrome()
driver.get('http://www.baidu.com')
#多个元素是调用属性时,需有后缀s
#对元素partial_link_text进行定位,并进行赋值
#提取所有的input,并放入集合里
tags=driver.find_elements_by_tag_name('input')
#通过索引调用第七条数据
tags[7].send_keys('无涯 接口测试')
time.sleep(3)
driver.quit()10、获取测试地址:current_url(获取网址)
driver=webdriver.Chrome()
driver.get('http://www.baidu.com')
#关键字:current_url
print(driver.current_url)
time.sleep(3)
driver.quit()11、获取当前页面代码:page_source(获取页面代码)
driver=webdriver.Chrome()
driver.get('http://www.baidu.com')
print(driver.current_url)
#判断
assert driver.current_url.endswith('baidu.com/')
time.sleep(3)
driver.quit()12、获取页面的title


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 10年+ .NET Coder 心语 ── 封装的思维:从隐藏、稳定开始理解其本质意义
· 地球OL攻略 —— 某应届生求职总结
· 提示词工程——AI应用必不可少的技术
· Open-Sora 2.0 重磅开源!
· 周边上新:园子的第一款马克杯温暖上架