lxml库之xpath的使用
xpath实例测试
第一步:导包
from lxml import etree

第二步:设置一些测试数据,方便xpath使用
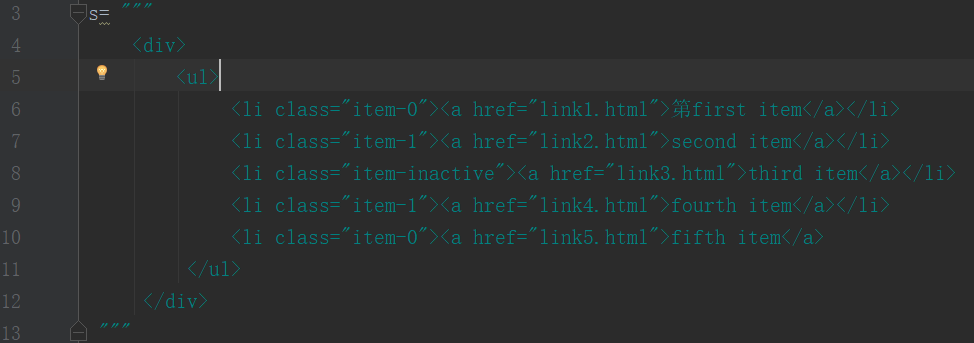
s= """ <div> <ul> <li class="item-0"><a href="link1.html">第first item</a></li> <li class="item-1"><a href="link2.html">second item</a></li> <li class="item-inactive"><a href="link3.html">third item</a></li> <li class="item-1"><a href="link4.html">fourth item</a></li> <li class="item-0"><a href="link5.html">fifth item</a> </ul> </div> """
第三步:将以上的字符串进行解析
tree = etree.HTML(s)
第四步:根据指定的xpath语法查找相关的信息
res = tree.xpath("//a/text()")
第五步:返回结果
for i in res: print(i)
最终效果:

解析(以上用到的路径表达式):
// 从全局查找指定的标签
/ 从当前标签下查找指定的标签
[num]表示要父级目录下的指定顺序的标签
[限制条件] 根据限制条件来找到指定的标签
text() 打印标签中的内容
@ 标签属性指定相关属性
整体代码:


from lxml import etree s= """ <div> <ul> <li class="item-0"><a href="link1.html">第first item</a></li> <li class="item-1"><a href="link2.html">second item</a></li> <li class="item-inactive"><a href="link3.html">third item</a></li> <li class="item-1"><a href="link4.html">fourth item</a></li> <li class="item-0"><a href="link5.html">fifth item</a> </ul> </div> """ tree = etree.HTML(s) #将指定的字符串进行解析 res = tree.xpath("//a/text()") #根据指定的xpath语法查找相关的信息 # res = tree.xpath("//div/ul/li/a") #根据指定的xpath语法查找相关的信息 for i in res: print(i) #下面方法是对应上面的res = tree.xpath("//div/ul/li/a")内容 #decode 解码 #显示element对象需要用到etree.tostring函数 # print(etree.tostring(i, encoding="utf8").decode("utf8"))

 浙公网安备 33010602011771号
浙公网安备 33010602011771号