
利用异构语言学图增强汉语预训练语言模型
GCN图卷积模型
论文中用到了GCN图卷积模型,GCN最早提出了一种可以在图(Graph)上执行卷积操作的方法,虽然图上卷积计算实现与图像(image)中的卷积不同,但是其背后隐含的思想是相同的,其都是从周围提取信息然后通过执行某种操作而获得新信息。
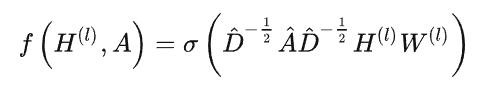
以上公式为GCN的计算公式 其中A为邻接矩阵,H为图节点的特征,A的波浪为A+I,I为单位矩阵,这是为了GCN计算某一结点下一层特征时候,不仅结合他的邻接节点同时还结合它自己输出节点的特征。D是度矩阵,因为如果直接让A和H相乘 会改变特征原来的分布,在两边都乘D能够得到一个归一化的矩阵。
引言
中文预训练模型利用上下文字符信息学习表示,却忽略了语言学知识,如单词和句子信息。因此,我们提出了一个称为异构语言学图(HLG)的增强模块,通过整合语言学知识来增强预先训练的汉语模型。具体而言,我们构建了一个层次异质图来建模汉语的特征语言学结构,并采用基于图的方法来总结和具体化汉语语言学层次的不同粒度的信息。实验结果表明,我们的模型能够在10个基准数据集的6个自然语言处理任务上提高vanilla BERT、BERTwwm和ERNIE 1.0的性能。此外,详细的实验分析已经证明,与以前的强基线MWA相比,这种建模实现了更多的改进。同时,我们的模型引入的参数要少得多(约为MWA的一半),训练/推理速度比MWA快约7倍。
另一种方法是在下游任务的微调阶段,将汉语特有的语言学知识直接整合到预先训练的PLM中。根据这一想法,通过在PLM中添加额外的适配器来集成外部知识,无任务增强模块在微调阶段被广泛使用(Li et al.,2020)。如图1所示,增强模块插入在PLM和特定任务模块之间,其输入是PLM的隐藏表示和外部知识的嵌入。为了在微调阶段实现将外部知识集成到PLM中的目标,增强模块应具有以下特性。首先,作为微调阶段的插件适配器模块,它应该与PLM保持一致的输出公式。其次,它不应该为训练和推理引入不可接受的时间或空间复杂性。第三,应普遍提高下游任务的绩效。
为了解决上述限制,我们提出了异构语言学图(HLG),这是一种基于图神经网络(GNN)的方法,用于集成CWS信息以增强PLM。具体来说,层次化的CWS信息首先由异构图进行,该异构图包含字符节点、单词节点和句子节点。节点之间的边缘表示语法结构在语言层次之间的包含关系。然后,提出了一种简单而有效的多步骤信息传播(MSIP),结合异构图的语言学知识,对汉语PLM进行归纳增强。通过这种方式,我们可以在字符、单词和句子之间获得足够的信息交互。此外,HLG的内部实现具有高度的并行性,有利于GPU的加速和提高操作效率
总之,我们为PLM抽象出了一个名为增强模块的适配器组件,以在微调阶段集成外部知识。在这种范式中,我们进一步引入HLG来精细地集成CWS信息,并通过有效的MSIP对其进行建模。在6个NLP任务的10个基准数据集上进行的大量实验表明,我们的模型显著而稳定地优于BERT、BERTwwm和ERNIE 1.0。与MW A相比,我们的模型在相同的信息下实现了稳步的改进。MW A是一个强大的基线,也包含了CWS信息来增强PLM。同时,与之前的工作MW A相比,我们提出的HLG只引入了一半的额外参数,并且训练/推理速度大约快了7倍
3异构图
本节介绍了我们的模型HLG的组件,该模型通过利用CWS信息来实例化增强模块。我们首先简要地解释了图卷积网络作为我们的基本编码器,然后描述了HLG的图构造。最后,我们给出了将CWS信息集成到PLM中的多步骤信息传播(MSIP)的细节。
图卷积网络公式
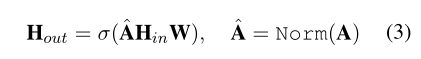
异质图构造
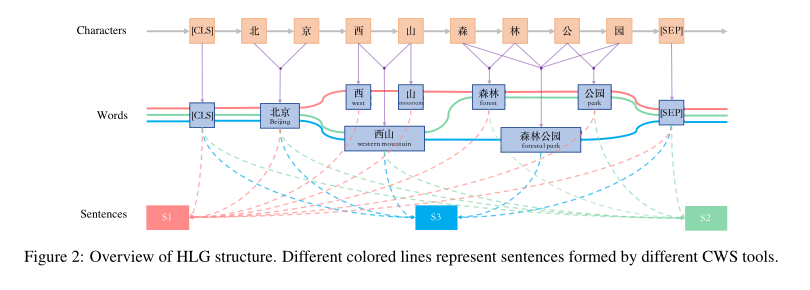
叫做异构图的原因是它从三个粒度对中文进行了建模。
我们建立了一个异构图G=(C,W,S,E)来对汉语语言结构进行建模,其中C,W、S,E分别表示字符节点集、单词节点集、句子节点集和边缘集。此外,和同构图不同,HLG以层次的方式对语言的三个粒度之间的关系进行建模。
如图2所示,G由三个层次组成,包括字符、单词和句子。在这种情况下,我们使用了三种不同的CWS工具,得到了三个不同的分割结果,这导致了三个语义略有不同的句子。请注意,不同CWS工具在相同位置获得的相同分词结果将被视为相同的单词节点,以增强交互(例如,图2中的北京和公园)。这个目的是去噪由分词错误带来的错误字节点。如果一个单词同时被多个分割器分割,那么对应的单词节点将具有更高的顶点度。这种具有较高介数中心性的节点将对后续信息传播产生更强的影响,并直观地达到去噪的效果,就像基于投票的多模型集成一样。
在HLG中,只有一个邻接矩阵A不足以描述字符、单词和句子之间的层次关系。还需要两个相互作用矩阵 ,
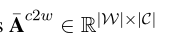 和
和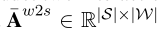 表示字符和单词,单词和句子之间的关系,
表示字符和单词,单词和句子之间的关系,
多步骤信息传播
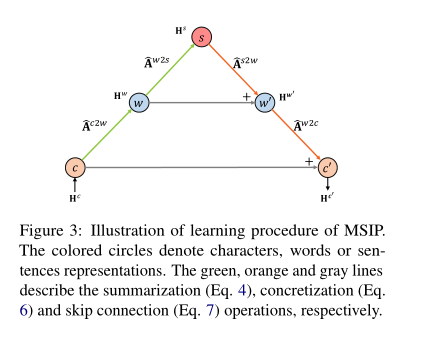
为了对G中的粒度层次关系进行建模,我们设计了一个多步骤的信息传播来学习语言学知识。在CWS中,划分和分组过程可以分别被视为语义表示的划分和分离语义的聚合(详见§2.2)。受CWS过程的启发,我们在MSIP中引入了两种操作来模拟这类过程,并命名为摘要和具体化。图3显示了MSIP的信息传播过程。
摘要 摘要操作侧重于概括分层的单词和句子表示(例如,从字符级别到单词级别)。具体地,给定来自PLM的异构图G和相应的字符表示Hc,概括操作可以公式化如下:
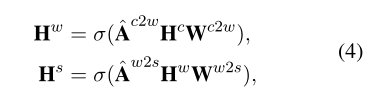
具体化 具体化是摘要的逆运算,它用于将语义从高级重新划分到低级(例如。从句子级别到单词级别)。为此,我们首先计算归一化的相互作用矩阵As2w和576 Aw2c,这可以通过首先转置然后分别归一化预定义的相互作用基质Aw2s和Ac2w来简单地获得。
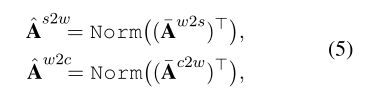
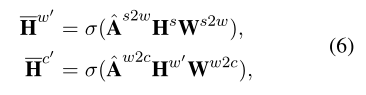
skip连接 直观地说,很难直接从高级表示生成令人满意的低级表示。例如,从几十个单词表征中学习几个句子表征是容易的,但从几个句子表征中生成几十个单词表示是困难的。为了缓解这个问题,在本文中,我们引入了跳跃连接来增强MSIP,即模拟普通GCN中的自循环。如图3所示,我们直接在摘要表示和具体化表示之间添加了跳过连接。形式上,跳过连接可以简单地表示为:
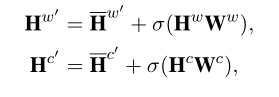
实验
三种常用的中文PLM:BERT(Devlin et al.,2019)、ERNIE 1.0(Sun et al.,2017)和BERTwwm(Cui et al.,2019a)被用作增强的基本PLM。
三种CWS工具:thulac(Sun et al.,2016a)、ictclas(Zhang et al.,2003)和hanlp(He,2014)用于获得分割信息。实验报告中忽略了包括应用CWS工具在内的预处理时间。在生产过程中,预处理和推理可以并行异步执行(当推理一批数据时,子序列数据可以用多进程进行预处理)(Cheng et al.,2019),我们介绍的所有三种CWS工具都足够快,可以实现这一效果。
具体来说,我们将增强模块实例化为HLG,并与下游任务特定模型结合在一起。为了验证HLG的有效性,我们对6个NLP任务的10个基准数据集进行了5次微调,并报告了平均得分。任务包括情感分类(SC)、文档分类(DC)、命名实体识别(NER)、句对匹配(SPM)、自然语言推理(NLI)和机器阅读理解(MRC)。具体而言,选择以下基准数据集来评估性能:
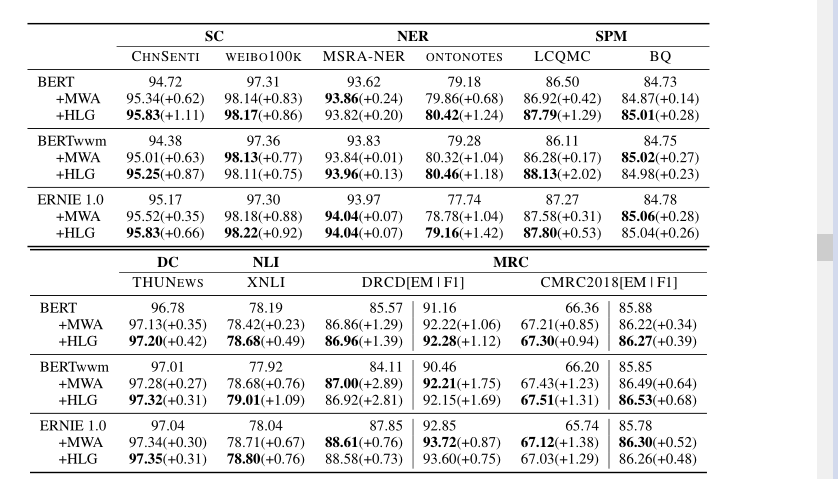
本文提出HLG作为增强中文的预训练语言模型,利用中文语言学信息增强中文预训练模型,首先使用多种分词工具进行分词,然后以中文字符、单词和句子三个层次进行建模,使用多步传播机制对不同粒度层次之间进行建模。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号