
文档级方面情感分析
在文献中,已有的研究总是将方面情感分类(Aspect emotion Classification, ASC)看作是一个独立的句子级逐方面分类问题,在很大程度上忽略了文档级情感偏好信息,尽管这些信息显然对于缓解ASC中的信息不足问题至关重要。本文探讨了文档内部的两种情感偏好信息,即同一方面的语境情感一致性(即方面内情感一致性)和所有相关方面的语境情感倾向(即方面间情感倾向)。在此基础上,提出了一种合作图注意网络(CoGAN)方法,用于方面相关句子表示的合作学习。具体而言,利用两个图注意网络分别对上述两种文档级情感偏好信息进行建模,并通过交互机制对两种偏好进行整合。详细的评估表明,与最新基线相比,所提出的ASC方法具有巨大的优势。这证明了文档级情感偏好信息对ASC的重要性,以及我们捕获此类信息的方法的有效性。
一方面,我们假设文档中涉及同一方面的句子在该方面倾向于具有相同的情感极性。例如,在文档1中,句子S1和S2都涉及方面AMBIENCE#GENERAL。虽然在S2中通过“without it trying to be that”这句话很难推断出方面AMBIENCE#GENERAL的负面情绪,但我们可以根据S1推断出方面AMBIENCE#GENERAL的情绪更有可能是负面的。这是因为通过S1中的从句“interior could use some help”更容易推断出AMBIENCE#GENERAL方面的否定。因此,一个行为良好的方法应该捕获上下文情绪一致性。
另一方面,我们假设文档中的句子在所有相关方面倾向于具有相同的情感极性。以文档2为例,句子S2涉及多个方面,很难准确预测每个方面的情感极性。但是,从上下文来看,S2中每个方面的情感极性都有很大可能是积极的,因为相邻的句子都表达了各自方面的积极情感极性。因此,一个行为良好的模型应该捕捉上下文情感倾向,即所有相关的方面(即方面间倾向)信息。
2模型
在本节中,我们将方面情绪分类(ASC)任务制定如下。在每个句子为si{s1,s2,…,sI}的文档D中,给定一个句子sI,i∈{1,2,…,i}及其方面ak,k∈{1,2…,k},ASC任务旨在通过自动学习与方面相关的句子si的表示ri来预测方面ak的情感极性。这里,I是句子si的数量,K是文档中方面ak的数量。
在本文中,我们提出了一种合作图注意力网络(CoGAN)方法,该方法具有两种类型的图注意力网络,分别包含两倍的偏好信息。图2显示了CoGAN方法的总体架构,该方法由五个主要块组成:编码块,方面内一致性模块,方面间趋势模块,交互模块,softmax解码模块,
2.1编码模块
使用bert对方面和句子进行编码,方面编码。由于方面ak由实体eentity和属性eatalign组成(Pontiki et al.,2015),我们将实体-属性对(eentity,eatalign)处理为BERT的输入对格式,如下所示:
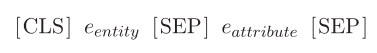
然后,我们将实体-属性对馈送到BERT中,并将标记“[CLS]”表示视为方面ak的方面向量ek∈Rd。
句子编码。我们借用了Sun等人提出的方法。(2019)生成方面相关的句子表示,这在ASC任务中取得了很好的性能。根据Sun等人(2019),我们首先将句子si及其相应的方面ak处理为BERT的输入对格式,如下所示:

question()句子构造:
3.3方面内一致性模块
在我们的方法中,我们提出了一个一致性感知GAN来对方面内一致性进行建模。给定一个包含句子{s1,s2,…,sI}的文档D,一致性感知的GAN表示为二部图
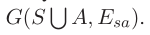 这里,S和A是两个不相交的顶点集,分别表示句子顶点和方面顶点。Esa是文档D中句子si∈S与其对应方面ak∈A之间的边的集合。
这里,S和A是两个不相交的顶点集,分别表示句子顶点和方面顶点。Esa是文档D中句子si∈S与其对应方面ak∈A之间的边的集合。
方面内一致性被公式化为句子顶点共享相同的方面顶点ak,并且同一文档中的句子对此方面具有相同的情感。然而,仍然存在情绪不一致的情况。
考虑到上述所有场景,我们使用图注意力机制来测量偏好度,其中注意力权重(偏好度)被计算为文档中句子顶点si和方面顶点ak之间的边缘权重。具体而言,根据等式(1),句子si和方面ak之间的注意力权重αik计算如下:

中,句子si被编码为与方面相关的表示,

3.4方面间趋势模块
给定具有句子{s1,s2,…sI}的文档D,趋势感知GAN被表示为无向图G(S,Ess)。这里,S是句子顶点的集合。Ess是文档D中句子si∈S和句子sj∈S之间的边的集合。在此基础上,方面间趋势假设被公式化为句子顶点si倾向于与同一文档内的相邻句子顶点{sj}Ij=1具有相同的情感。类似于方面内一致性建模块,根据等式(1),应用以下公式来计算来自同一文档的句子顶点si和句子顶点sj之间的注意力权重αij:

作为G(S,Ess)中的一个顶点,根据等式。(1),句子si被编码为新的句子表示,即。
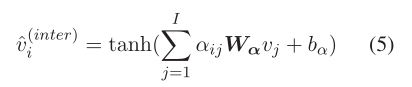
3.5交互模块
由于上述两倍偏好可以共同影响si中对方面ak的情绪,我们使两倍偏好成对地相互作用,以协同提高性能。
特别是,在从上述两重偏好建模块中获得句子si的两个句子表示(vv(inter)i和vv(intra)i)后,我们提出了一种交互机制来在两个向量之间进行交互,而不是简单地将它们连接起来。这是因为简单的向量串联不能考虑双重偏好的潜在特征之间的任何相互作用,这不足以对双重偏好进行合作建模。详细地说,这种互动机制利用了两种策略来学习句子表征。
两种策略:
金字塔层:对于更高层使用少量隐藏单元的模型可以学习更抽象的特征。受此启发,我们在级联向量上添加了金字塔隐藏层(见图2),用于交互双重偏好的潜在特征,其中底层最宽,每个连续层的神经元数量较少。
自适应融合机制:为了充分融合不同抽象级别的句子表示,提出了一种自适应融合机制来融合所有层的表示,以计算顶点si的最终句子向量ri∈Rd,如下所示:
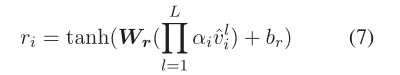
 表示多层向量的串联,α=[α1,…,αL]是用于对每一层进行加权的归一化权重向量,在训练过程中学习.
表示多层向量的串联,α=[α1,…,αL]是用于对每一层进行加权的归一化权重向量,在训练过程中学习.
3.6 softmax解码层
在获得句子si的最终句子向量ri后,我们将其馈送到softmax分类器m=W ri+b,其中m∈RC是输出向量;W和b是可训练的参数。
3.7模型训练
给定来自语料库C的一组训练数据(si,ak,yi),我们使用交叉熵损失函数来端到端地训练我们的模型,其中si是要预测的第i个句子,ak是其对应的方面,yi是方面ak的基本事实情感极性。
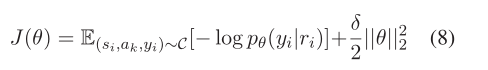
4实验
4.1对比实验结果
Clause-Level ATT, CADMN and IMN,表现优于 TC-LSTM.这一结果证明了使用适当的注意力机制来学习与方面相关的句子表示以执行ASC任务的有效性。此外,我们的方法CoGAN w/o IntraAspect Consistency和CoGAN w/o InterAspect Trendy优于上述大多数最先进的方法。这鼓励对ASC任务的方面内一致性或方面间趋势信息进行建模。

相比之下,当结合两倍情绪偏好信息时,我们的方法CoGAN在所有四个数据集上都优于所有上述基线方法,甚至显著优于(p值<0.05)来自SemEval-2015任务12和SemEval-2016任务5的所有三个表现最好的系统,即Sentiue、XRCE和IIT-TUDA。令人印象深刻的是,与TCLSTM相比,我们的方法在两个餐厅数据集上实现了11.6%(准确度)、14.3%(MacroF1)的平均改进,在两个笔记本电脑数据集上分别实现了9.1%(准确率)、12.6%(Macro-F1)的平均改进。显著性检验表明,这些改进都是显著的(p值<0.01)。这些结果突出了在ASC任务的文档中纳入方面内一致性和方面间趋势信息的重要性。
