
基于方面情感分析的双语法感知图注意力网络
摘要
基于方面的情感分析极具挑战性,因为一个句子可能包含多个方面或复杂的关系。利用图神经网络挖掘依赖语法信息已成为最流行的趋势,尽管取得了成功,但严重依赖依赖树的方法在准确建模方面及其表示情绪的词语的一致性方面带来了挑战,因为依赖树可能会提供不相关联的嘈杂信号。为了缓解这一问题,提出双语法感知的图注意力网络,充分利用句子构成树的语法信息(短语分割和层次结构),对每个方面的情感感知上下文(内上下文)和跨方面的情感关系(上下文间)进行建模,以供学习。
1介绍
为了缓解这个问题,已经有几项工作(Wang et al.,2020a;Chen et al.,2020)致力于研究如何通过图神经网络(GNN)有效地利用非序列信息(例如,依赖树等句法信息)。通常,依赖树(即Dep.tree)将方面术语与语法相关的单词联系起来,在远距离依赖问题中保持有效。然而,Dep.Tree结构的固有性质可能会引入噪音,就像子句之间的不相关关系一样,例如图2中“伟大”和“可怕”之间的“conj”关系,这阻碍了捕捉每个方面的情感感知上下文,即上下文内。Dep.Tree结构只揭示单词之间的关系,因此,在大多数情况下,它无法建模复杂的句子关系(例如,条件关系、协调关系或对抗关系),因此无法捕捉各方面之间的情感关系,即上下文之间的情感关系。
因此,在本文中,我们考虑充分利用组成树的语法信息来解决这个问题。通常,组成树(即Con.tree)通常包含精确且有区别的短语分割和层次结构,这有助于正确地对齐各方面及其对应的表示情绪的单词。前者可以将复杂的句子自然地划分为多个分句,后者可以区分不同方面之间的不同关系,从而推断不同方面的情感关系。我们在图3中举了一个例子来说明这一点:(1)“食物很棒”和“服务和环境很糟糕”这两个条款被短语分割术语“但是”分割;(2) 在第一层中,术语“和”表示“服务”和“环境”的协调关系,而第三层中的术语“但是”反映了对“食物”和“服务”(或“环境”)的对立关系。
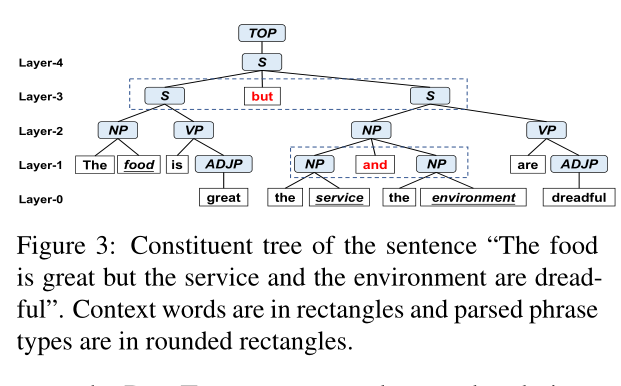
因此,为了更好地协调方面术语和相应的情感,我们提出了一个新的框架,即双语法感知图注意力网络(BiSyn-GAT+),通过建模上下文内和上下文间信息来有效地利用组成树的语法信息。特别地,BiSyn GA T+采用:1)语法图嵌入,以自下而上的方式基于同一子句内的融合语法信息对每个方面的内部上下文进行编码,该方式组合了其组成树的短语级语法信息和其依赖树的子句级语法信息。
2) 由短语分割术语和所有方面组成的方面上下文图,用于对每个方面的内部上下文进行建模。具体而言,它根据当前方面与其相邻方面之间的影响来聚合其他方面的情感信息,该影响是基于分别从方面上下文图上的双向关系中学习的方面表示来计算的。
我们的主要贡献如下:
1.据我们所知,这是第一项利用构成树的语法信息(例如,短语分割和层次结构)与GNN进行ABSA的工作。此外,它在表示情感的方面和相应单词之间的对齐方面显示出优越性。
2.我们提出了一个框架,即双语法感知图注意力网络(BiSyn-GAT+),通过建模每个方面的情感上下文和跨方面的情感关系,来充分利用组成树(或,和依赖树)的语法信息。
2相关工作
分为两类:没有语法信息的方法和有语法信息的方法
没有语法信息的方法:
具有注意力机制的神经网络(Wang et al.,2016;Chen et al.,2017;Song et al.,2019)已被广泛使用。Chen等人(2017)采用了多重注意力机制来捕捉情绪特征。Song等人。(2019)使用注意力编码器网络(AEN)从单词嵌入中挖掘丰富的语义信息。
基于语法的方法:
最近,利用GNN的依赖性信息已经成为ABSA的一种有效方式。Zhang等人(2019)使用图卷积网络(GCN)从Dep.Tree学习节点表示。Tang等人。(2020)通过联合考虑来自变压器和相应的依赖图的表示,提出了一种依赖图增强的双变压器网络(DGEDT)。Wang等人(2020a)构建了面向方面的依赖树,并提出了R-GA T,扩展了图注意力网络以编码具有标记边的图。Li等人(2021)提出了一个双图卷积网络(DualGCN)模型,同时考虑了语法结构和语义相关性。上述所有工作都使用了Dep.Tree的语法信息,正如我们之前所说,这可能会引入噪声。因此,我们利用GNN来利用Con.Tree的语法信息。确切地说,我们遵循Con.Tree以自下而上的方式聚合来自相同短语中的单词的信息,并捕获上下文内的信息。
我们提出了一个由所有方面和短语分割术语组成的方面-上下文图,以对上下文间信息进行建模。
具有组成树的GNN:据我们所知,我们是第一个将构成树用于ABSA任务的工作。但是,在预测文本中给定预定义类别的情感极性的方面类别情感分析任务中,Li等人(2020b)提出了一种句子结构感知网络(SCAN),该网络生成Con.Tree中节点的表示。与SCAN不同,我们将解析的短语视为输入文本的不同跨度,而不是单个节点。因此,我们不将Con.Tree的任何内部节点(例如,图3中的“NP”、“VP”)引入表示空间,从而减少了计算开销。
3模型
3.1概述
设s={wi}n和A={aj}m是一个句子和一个预定义的方面集,其中n和m分别是s中的单词数量和A中的方面数量。对于每个s,As={ai|ai∈A,ai∈s}表示s中包含的方面。为了简单起见,我们将每个多词方面视为一个单词,因此ai也意味着s的第i个单词。ABSA的目标是预测每个方面ai∈As的情感极性yi∈{正、负、神经}。
如图4所示,我们提出的架构以句子和文本中出现的所有方面作为输入,并输出这些方面的情绪预测。它包含三个组件:1)上下文内模块对输入{wi}进行编码,以获得目标方面的方面特定表示,该模块包含两个编码器:输出上下文单词表示的上下文编码器和利用解析的组成树(或,和依赖树)的语法信息的语法编码器。2) 上下文间模块包括应用于所构建的方面上下文图以输出关系增强表示的关系编码器。方面-上下文图构成给定句子和短语分割项的所有方面,这些术语是从应用于构成树的设计的基于规则的映射函数中获得的。3) 情绪分类器采用上述两个模块的输出表示来进行预测。
3.2上下文内模块
在这一部分中,我们使用上下文编码器和语法编码器来对每个方面的情感感知上下文进行建模,并为每个方面生成特定于方面的表示。注意,对于多方面的句子,我们多次使用这个模块,因为每次都涉及一个方面。
3.2.1上下文编码器
我们使用BERT(Devlin et al.,2019)来生成上下文单词表示。给定目标方面at,我们遵循BERT-SPC(Song et al.,2019)构建基于BERT的序列:

然后通过以下方式获得输出表示,
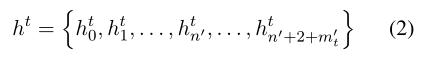
注意,wi可以被BERT标记器拆分为多个子词。因此,我们计算wi的上下文表示如下,


3.2.2语法编码器
上述表示只考虑了语义信息,因此提出了一种语法编码器来利用丰富的语法信息,语法编码器由HGAT块组成,每个块由多个图注意力网络组成,语法编码器在依赖树的指导下对语法信息进行层次编码,
图的构建

 浙公网安备 33010602011771号
浙公网安备 33010602011771号