
使用多步情节马尔可夫决策过程提取长文档摘要
我们介绍了MemSum(多步情景马尔可夫决策过程提取汇总器),这是一种基于强化学习的提取汇总器,在每一步都丰富了当前提取历史的信息。当MemSum迭代地选择摘要中的句子时,它考虑了一个广泛的信息集,该信息集也可以直观地被人类用于该任务:1)句子的文本内容,2)文档其余部分的全局文本上下文,以及3)由已经提取的句子集组成的提取历史。凭借轻量级架构,MemSum在总结来自PubMed、arXiv和GovReport的长文档时获得了最先进的测试集性能(ROUGE)。消融研究证明了局部、全局和历史信息的重要性。人类评估证实了生成的摘要的高质量和低冗余性,这源于MemSum对提取历史的了解。
自动文本摘要是将长文档自动摘要为相对短的文本,同时保留大部分信息的任务(Tas和Kiyani,2007)。文本摘要方法可分为抽象摘要和提取摘要(Gambir和Gupta,2017;Nenkova和McKeown,2012)给定一个由N个句子的有序列表组成的文档d,提取式摘要旨在提取M(M≪N) 作为文件摘要的句子。提取的摘要往往在语法和语义上都比抽象摘要更可靠(Liu*等人,2018;Liu和Lapata,2019a;Luo等人,2019;Liao等人,2020),因为它们是直接从源文本中选择的。
提取摘要通常被建模为两个连续阶段(Zhou等人,2018):1)句子评分和2)句子选择。
句子评分阶段,通过诸如双向RNN(Dong等人,2018;Narayan等人,2018年;Luo等人,2019年;Xiao和Carenini,2019年)或BERT(Zhang等人,2019;Liu和Lapata,2019b)的神经网络为每个句子计算亲和性得分。在句子选择阶段,通过以下方式选择句子:i)基于每个句子的得分预测每个句子的标签(1或0),并选择标签为1的句子(Zhang et al.,2019;Liu和Lapata,2019b;Xiao和Carenini,2019),或ii)基于得分对句子进行排名,并选择前K个句子作为摘要(Narayan et al.,2018),或iii)在没有替换的情况下顺序采样句子,其中剩余句子的标准化分数被用作采样似然(Dong等人,2018;Luo等人,2019)。
在这些方法中,通常不会基于先前选择的句子的当前部分摘要更新句子分数,这表明缺乏提取历史的知识。我们认为,不知道提取历史的提取总结者容易在文档中重复,因为他们会重复地在摘要中添加高分的句子,而不管之前是否选择过类似的句子。而且,冗余会导致ROUGE F1评估的性能下降。在本文中,我们提出将提取式摘要建模为多步骤情景马尔可夫决策过程(MDP)。
每一集的每个时间步,我们定义一个由三个子状态组成的句子状态: 1) 句子的局部内容,2)文档中句子的全局上下文,以及3)关于提取历史的信息,包括先前选择的无序句子集和剩余句子。
在每个时间步骤,策略网络(代理)将当前句子状态作为输入,并产生用于选择停止提取过程或将剩余句子之一选择到候选摘要中的动作的分数。与基于一步式情景MDP的模型(Narayan等人,2018;Dong等人,2018年;Luo等人,2019)不同,在我们的多步骤策略中,代理在选择动作之前,在每个时间步更新提取历史。这种分步状态更新策略使得代理在选择句子时能够考虑部分摘要的内容。 在每个时间步骤,策略网络(代理)将当前句子状态作为输入,并产生用于选择停止提取过程或将剩余句子之一选择到候选摘要中的动作的分数。与基于一步式情景MDP的模型(Narayan等人,2018;Dong等人,2018年;Luo等人,2019)不同,在我们的多步骤策略中,代理在选择动作之前,在每个时间步更新提取历史。这种分步状态更新策略使得代理在选择句子时能够考虑部分摘要的内容。
工作贡献如下:1)我们建议将提取式摘要视为一个了解提取历史的多步骤情景式MDP。2) 我们表明,提取历史感知使我们的模型能够提取比没有历史感知的模型更紧凑的摘要,并且对文档中的冗余行为表现得更稳健。3) 在PubMed、arXiv(Cohan等人,2018)和GovReport(Huang等人,2021)数据集上,我们的模型优于提取和抽象摘要模型。4) 最后,人类评估人员认为MemSum总结的质量高于竞争方法,尤其是冗余度较低。
3模型
本节概述了用于提取摘要的多步骤情景MDP策略。
3.1策略梯度方法
在具有终端状态(即总结结束)的情景任务中,策略梯度方法旨在最大化目标函数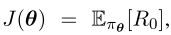 其中
其中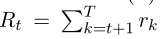 是从时间t+1到总结完成时的集结束的累积奖励。应用强化学习提取摘要时,除了根据等式(1)计算最终奖励r时,在事件结束时,瞬时奖励rt为零,
是从时间t+1到总结完成时的集结束的累积奖励。应用强化学习提取摘要时,除了根据等式(1)计算最终奖励r时,在事件结束时,瞬时奖励rt为零,
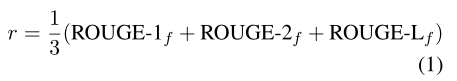
根据强化学习算法,策略梯度被定义为
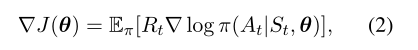
其中,π(At|St,θ)表示在给定状态St的情况下,在时间步长t,策略πθ选择动作At的可能性。以α作为学习率,参数更新规则为(Sutton和Barto,2018):
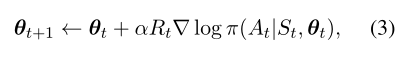
3.2多步骤情景MDP策略
与一步式情景式MDP策略(Narayan等人,2018;Dong等人,2018年;Luo等人,2019)不同,我们定义了一个情景,即由多个时间步骤组成的摘要的生成。在每个时间步骤t,对应于提取句子编号t,动作At要么停止提取,要么从剩余句子中选择一个句子。代理人的政策是:
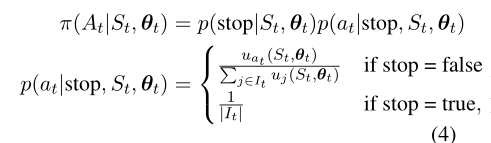
It表示在时间步骤t的剩余句子的索引集合。
如果代理没有停止,它首先计算每个剩余句子的分数uj,并根据归一化分数的概率分布对句子进行采样。当代理停止提取时,不选择任何句子,并且将条件似然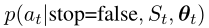 设置为
设置为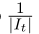 (其中|It|表示在时间t的剩余句子数),这与策略参数无关,以禁止梯度通过条件似然传递给策略参数。在根据等式(1)计算奖励之后,根据等式(3)(对于所有时间步长)更新策略参数。
(其中|It|表示在时间t的剩余句子数),这与策略参数无关,以禁止梯度通过条件似然传递给策略参数。在根据等式(1)计算奖励之后,根据等式(3)(对于所有时间步长)更新策略参数。
3.3策略网络
等式(4)中的状态St被设计为提供以下信息:1)句子的局部内容,2)文档中句子的全局上下文,以及3)当前提取历史。为了在状态中对这三个属性进行编码,我们分别使用了局部语句编码器、全局上下文编码器和提取历史编码器。随后,提取器将状态映射到每个剩余句子的输出分数和提取停止信号。我们模型的总体框架如图2所示。
在局部句子编码器(LSE)中,首先使用单词嵌入矩阵将句子si中的有序单词(w1,w2,…wM)映射到单词嵌入上。随后,Nl层双向LSTM(Hochreiter和Schmidhuber,1997)将单词嵌入进行转换,并通过多头部池层(MHP)将其映射到句子嵌入lsi上(Liu和Lapata,2019a)。
全局上下文编码器(GCE)由Ng层双LSTM组成,其将L个局部句子嵌入(ls1,ls2,…lsL)作为输入,并为每个句子si生成嵌入gsi,该嵌入gsi编码全局上下文信息,例如句子在文档中的位置和相邻句子的信息。提取历史编码器(EHE)对提取历史信息进行编码,并为每个剩余句子sri生成提取历史嵌入hsri。EHE由N个相同层组成。在一个层中,有两个多头注意力子层,如V aswani等人(2017)中的变压器解码器所示。
EHE?
不存在位置编码,EHE通过关注前一位置和后一位置来非自动地生成提取历史嵌入。因此,剩余句子的提取历史嵌入hsri对于先前选择的句子的顺序是不变的。我们认为,先前选择的句子的顺序信息对于减少冗余和决定是否停止提取并不重要。提取器计算每个剩余句子的分数并输出提取停止信号。作为提取器的输入,我们通过串联本地句子嵌入lsri、全局上下文嵌入gsri和提取历史嵌入hsri,为每个剩余句子sri形成聚合嵌入。如图2所示,为了生成分数usri,剩余句子sri的级联嵌入通过ReLU激活传递到完全连接的层,然后由Linear-1层投影到标量。注意,相同的完全连接层同样适用于所有剩余的句子。我们认为提取器可以根据剩余句子的状态学习停止提取。因此,我们将MHP应用于所有剩余句子的最后隐藏向量,以输出单个向量。然后将该向量传递到具有Sigmoid函数的线性层,产生停止概率pstop。
们根据等式(3)中的更新规则来训练参数化策略网络。在每次训练迭代中,对一集进行采样,以计算所有时间步长t的最终返回r和动作概率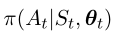 包含T个提取句子的示例集如下:
包含T个提取句子的示例集如下: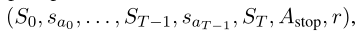

 浙公网安备 33010602011771号
浙公网安备 33010602011771号