
Structural Bias for Aspect Sentiment Triplet Extraction(COLING 2022)
摘要 即使使用了大规模预训练模型,结构偏差仍然是有必要的
在本文中,我们希望从两个角度回答这个问题:1)在参数和延迟效率方面,结构偏差是否可以以灵活的方式纳入PLM;以及2)结构偏差是否可以增强ASTE的额PLM。
相比之下,我们建议使用结构化的注意力图,而不是引入精心设计的插件,从而在自我注意力中对原始注意力图产生额外影响,从而只需要少量的增量参数。在此基础上,我们进一步建议使用相对距离来替代依赖距离。直觉在于观察到意见主要与相应方面密切相关(Xu等人,2020;Ma等人,2021),因此我们假设使用相对距离偏差就足以实现ASTE。即使在PLM的情况下,结构偏差仍然是必要的,以实现更好的ASTE性能。
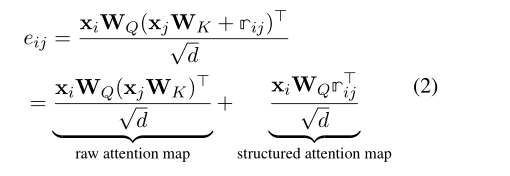
为了将依赖性或相对距离整合到自我注意中,结构适配器被强加以导出结构化的注意图,以对由自我注意诱导的原始注意图进行加性偏置。
总之,结构偏差可以灵活地结合到PLM中,并提高参数和延迟效率。结构适配器只需要少量参数。相对距离可以以低延迟实现。此外,结构适配器大大提高了SOTA性能。因此,即使在PLM的情况下,结构偏差仍然是必要的,以实现更好的ASTE性能。
带有结构适配器的预训练模型
当PLM被用作主干时,令牌首先被转换为嵌入,然后由随后的转换块操作。虽然PLM可以捕获语义交互,但我们还介绍了如何将结构交互包括在结构适配器中。当PLM被用作主干时,令牌首先被转换为嵌入,然后由随后的转换块操作。虽然PLM可以捕获语义交互,但我们还介绍了如何将结构交互包括在结构适配器中。

上图显示自我注意(左)和应用结构适配器的自我注意(右)之间的差异。Q、 K和V分别代表线性变换的查询、键和值。R代表距离。
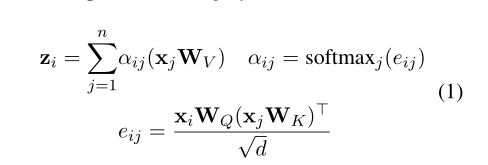
加入结构适配器的注意力机制
rij表示两个标记ti和tj之间的距离嵌入。同样值得注意的是,每个关系嵌入在不同的头之间共享,但从一层到另一层保持独立。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号