

Dependency-Guided LSTM-CRF for Named Entity Recognition
基于依赖关系的LSTM-CRF的命名实体识别
摘要
依赖树结构捕捉句子中单词之间的远距离和句法关系。句法关系(例如,名词主语、宾语)可能推断出某些命名实体的存在。此外,命名实体识别器的性能还可以受益于依赖树中单词之间的长距离依赖关系。在这项工作中,我们提出了一个简单而有效的依赖导向LSTM-CRF模型,对完整的依赖树进行编码,并捕获命名实体识别任务的上述属性。数据统计显示实体类型和依赖关系之间存在很强的相关性。我们在几个标准数据集上进行了广泛的实验,证明了所提出的模型在改善NER和实现最新性能方面的有效性。我们的分析表明,显著的改进主要来自依赖树提供的依赖关系和远程交互。
1介绍
命名实体识别(NER)是自然语言处理(NLP)中最重要和最基本的任务之一。命名实体捕获有用的语义信息,这些信息对后续NLP任务(如共同引用解析,关系提取和语义分析)很有帮助。另一方面,依赖树还捕获了自然语言句子中有用的语义信息。目前,研究工作已经从依赖结构中提取出有用的离散特征或结构约束去帮助实现命名实体识别任务。然而,如何更好的利用完整的依存结构所传达的丰富的关系信息以及单词之间复杂的远距离交互仍然是一个有待回答的研究问题。
图1中的第一个示例说明了依赖关系结构和命名实体之间的关系。具体而言,“premise”一词是LOC(location)类型的命名实体,其特征是带有标签“pobj”(介词宾语)的引入弧。这条弧线揭示了“premise”一词在句子中所起的一定程度的语义作用。同样,第二个示例中形成GPE类型实体的两个单词“香港”也具有类似的依赖弧。
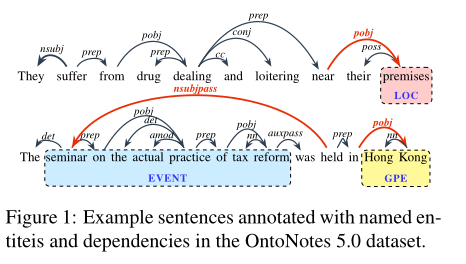
捕获非局部结构信息的远程依赖也可以对NER任务非常有帮助,在图1的第二个示例中,从“held”到“seminar”的长距离依赖关系表示它们之间的直接关系“nsubjpass”(被动主题),这可以用来描述实体的存在。然而,现有的基于线性链结构的NER模型很难捕捉这种长距离关系(即非局部结构)。大多数实体在其相应的依赖树下形成子树。在图1中的事件实体示例中,实体本身形成了一个子树(把这个实体提取出来,他也满足依存句法分析的定义,形成了一个子树),其中的单词之间具有丰富复杂的依赖关系。利用子树中的这种依赖边,模型可以捕获长实体中单词之间的非平凡语义级交互。例如,“practice”是“on”的介词宾语(pobj),它是事件实体中“seminar”的介词(prep)。建模这些孙依赖关系(GD)(Koo和Collins,2010)需要该模型捕获句子中不同单词之间的一些高阶远距离交互。
受上述依赖结构特征的启发,在这项工作中,我们为NER提出了一个简单而有效的依赖引导模型。我们基于神经网络的模型能够捕获上下文信息和NER任务中单词之间丰富的远程交互。通过在不同语言的多个数据集上进行的大量实验,我们证明了我们的模型的有效性,达到了最先进的性能。据我们所知,这是第一个利用完整依赖关系图的工作。
2 相关工作
NER一直是NLP领域的一项长期任务。虽然最近的许多工作(Peters et al.,2018a;Akbik et al.,2018;Devlin et al.,2019)侧重于寻找良好的语境化单词表示来改善NER,但我们的工作主要与使用依赖树来改善NER有关。
3 模型
我们的依赖导向模型基于Lample等人(2016)提出的最先进的BiLSTM CRF模型。我们首先简要介绍他们的模型作为背景,然后介绍我们的依赖引导模型。
3.1 Background: BiLSTM-CRF
在命名实体识别任务中,我们的目标是预测标签序列y = {y1, y2, · · · , yn}基于给定的输入序列x = {x1, x2, · · · , xn}。y中的标签由带有标准IOBES标签方案的标签集定义。CRF(Lafferty等人,2001)层定义了给定x的标签序列y的概率:
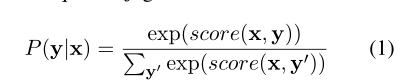 Following Lample et al. (2016) 分数定义为BiLSTM转移和发射矩阵的参数的总和:
Following Lample et al. (2016) 分数定义为BiLSTM转移和发射矩阵的参数的总和:

其中A是一个转移矩阵,其中Ayi,yi+1是从标签yi到标签yi+1的转移参数,Fx是一个发射矩阵,其中Fx,yi表示标签yi在第i个位置的得分。这些分数由参数化LSTM(Hochreiter和Schmidhuber,1997)网络提供。在训练过程中,我们最小化负对数似然来获得模型参数,包括LSTM和过渡参数。
3.2 Dependency-Guided LSTM-CRF
输入表示BiLSTM CRF(Lample等人,2016;Ma和Hovy,2016;Reimers和Gurevych,2017)模型中的单词表示w包括单词嵌入的串联以及相应的基于字符的表示。受句子中每个单词(除了词根)在依赖结构中只有一个头部(即父)单词这一事实的启发,我们可以使用这种依赖信息来增强单词表示。与Miwa和Bansal(2016)的工作类似,我们将单词表示与相应的头单词表示和依赖关系嵌入连接起来作为输入表示。
具体而言,给定依赖边(xh,xi,r),其中xh为父,xi为子,r为依赖关系,位置i处的表示可以表示为:
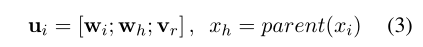
其中wi和wh分别是单词xi和其父单词xh的单词表示。我们将字符级BiLSTM的最终隐藏状态作为基于字符的表示。vr是依赖关系r的嵌入。这些关系嵌入在训练期间被随机初始化和微调。上述表示允许我们捕获输入层的直接远程交互。对于作为依赖树根的单词,我们将其父级视为其自身3,并创建根关系嵌入。此外,上下文化的单词表示(如ELMo)也可以连接到u。
神经架构给定依赖编码的输入表示u,我们应用LSTM来捕获上下文信息并且在依赖树中对单词及其对应父级之间的交互进行建模。图2显示了针对示例句子“阿布拉莫夫在莫斯科发生事故”的dependency-guidedLSTM-CRF(DGLSTM-CRF)及其依赖性结构,其中包含2个LSTM层。相应的标签序列为{S-PER, O,O, O, O, S-GPE},在第一个BiLSTM之后,每个位置的隐藏状态将沿着依赖树传播到下一个BiLSTM层及其子层。例如,单词“had”的隐藏状态,将传播到它第一个位置的孩子单词Abramov,对于根单词,该特定位置的隐藏状态将传播到自身。我们使用交互函数g(hi,hpi)来捕获依赖关系中的子级与其父级之间的交互。这种交互功能可以是串联、加法或多层感知器(MLP)。我们进一步在交互函数的顶部应用另一个BiLSTM层,以生成最终CRF层的上下文表示。
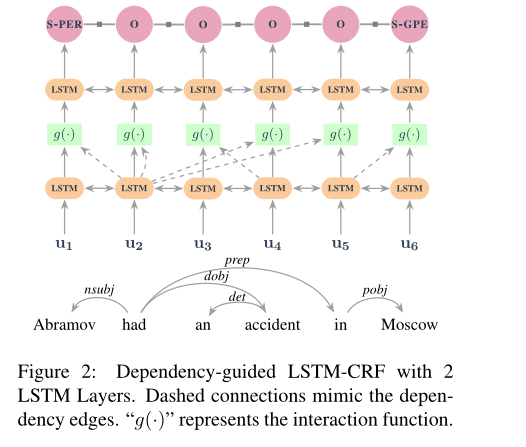
图2所示的带有2层BiLSTM的体系结构可以有效地对孙依赖项进行编码,因为输入表示对父信息进行编码,而交互函数进一步传播祖辈信息。这种传播允许模型捕捉到第1节中提到的句子中单词之间的孙依赖关系中的间接远距离交互。通常,我们可以堆叠更多的交互函数和BILSTM,以便对依赖树进行更深入的推理。第(l+1)层H(l+1)的隐藏状态可根据前一层H(l)的隐藏状态计算:(这里使用的是多层Bi-LSTM,前一层的输出ht作为下一层的输入xt
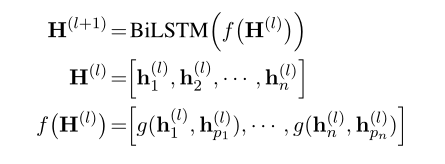
其中pi表示单词xi的父索引。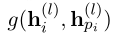 表示依赖边(xpi,xi)下i-th和pith位置的隐藏状态之间的相互作用函数。层的数量L可以根据开发集上的性能来选择。
表示依赖边(xpi,xi)下i-th和pith位置的隐藏状态之间的相互作用函数。层的数量L可以根据开发集上的性能来选择。
交互作用函数父表示和子表示之间的交互功能可以通过多种方式定义。表1显示了我们实验中考虑的相互作用函数列表。第一个返回隐藏状态本身,这相当于堆叠LSTM层。串联和加法不涉及参数,这是建模交互的简单方法。最后一个应用MLP来建模父表示和子表示之间的交互。使用校正线性单元(ReLU)作为激活函数,g(hi,hpi)函数类似于图卷积网络(GCN)(Kipf和Welling,2017)公式。在这样的图中,每个节点都具有自连接(即hi)和与父节点的依赖关系连接(即hpi)。与Marcheggiani和Titov(2017)的工作类似,我们采用不同的参数W1和W2进行自我和依赖连接。
4实验
数据集主要实验是在大规模的OntoNotes 5.0(Weischedel等人,2013)中英文数据集上进行的。我们之所以选择这些数据集,是因为它们同时包含选区树和命名实体注释。OntoNotes数据集中定义了18种类型的实体。我们将constituency树转换成Stanford dependency (De Marn-effe and Manning, 2008) trees通过使用斯坦福大学CoreNLP(Manning et al.,2014)的基于规则的工具(De Marneffe et al.,2006)。对于英语,Pradhan等人(2013)提供了训练,验证和测试集的拆分,该拆分已被之前的几项工作使用。对于中文,我们使用Pradhan等人提供的官方拆分。此外,我们还对SemEval2010任务1中的加泰罗尼亚和西班牙数据集进行了实验。SemEval-2010任务最初设计用于多语言的共指消解任务。同样,我们选择这些语料库主要是因为它们同时包含依赖项和命名实体注释。我们选择最主要的三种实体类型,并将其余的合并为一种通用的a实体类型“misc”。表2显示了主要实验中使用的数据集的统计数据。为了进一步评估依赖结构的有效性,我们还对NER在低资源环境下进行了额外的实验(Cotterell和Duh,2017)。表2中ST表示构成子树的实体的比例,GD表示子树中具有孙依赖关系的实体的比例。
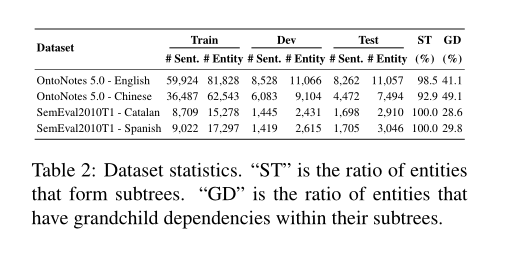
表2的最后两列显示了完整数据集的依赖树和长度大于2的命名实体之间的关系。具体而言,倒数第二列显示了可以在其依赖树结构下形成完整子树(ST)的实体的百分比。显然,大多数实体形成子树,特别是对于加泰罗尼亚和西班牙的数据集,其中100%的实体形成子树。这一观察结果与Jie等人(2017)的研究结果一致。这种孙依赖关系对于检测某些命名实体非常有用,特别是对于长实体。正如我们将在第5节后面看到的,使用依赖关系指南模型可以显著提高长实体的性能。
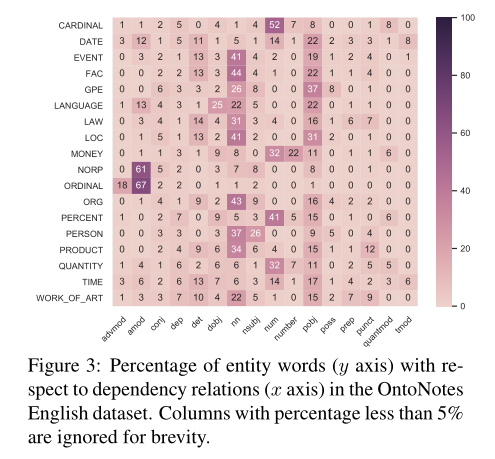
图3中的热图表显示了OntoNotes英语数据集中实体类型和依赖关系之间的相关性。具体而言,每个条目表示具有特定依赖关系的父依赖关系的实体的百分比。例如,在具有GPE实体的行中,37%的实体字具有标签为“pobj”的依赖边。当查看“pobj”和“nn”列时,我们可以看到大多数实体都与介词宾语(pobj)和名词复合修饰语(nn)相关。特别是对于NORP(即民族或宗教或政治团体)和ORDINAL(如“第一”、“第二”)实体,超过60%的实体词具有形容词修饰语(amod)依赖关系。此外,每个实体类型(即行)都有一个最相关的依赖关系(出现率超过17%)。这些观察结果提供了有用的信息,可用于对不同类型的命名实体进行分类。
Baselines我们采用最先进的NER模型BiLSTM-CRF(Lample et al.,2016)作为第一个基线,具有不同数量的LSTM层(L={0,1,2,3})。L=0表示模型仅依赖于输入表示。继Zhang等人(2018)之后,完整的依赖树被认为是双向的,并使用上下文化的GCN(BiLSTMGCN)进行编码。我们进一步为NER任务添加了关系特定参数(Marcheggiani和Titov,2017)和CRF层。结果基线为BiLSTM-GCN-CRF。在比较不同模型的结果时,我们使用自举配对t检验(Berg-Kirkpatrick et al.,2012)进行显著性检验。
实验配置根据开发集上的性能,我们在DGLSTM-CRF中选择MLP作为交互函数。所有模型(即LSTM、GCN)的隐藏大小设置为200。我们使用手套(Pennington et al.,2014)100-d单词嵌入,这在英语NER任务中被证明是有效的(Ma和Hovy,2016;Peters et al.,2018a)。我们使用公开的FastText(Grave et al.,2018)嵌入中文、加泰罗尼亚语和西班牙语的单词。ELMo(Peters et al.,2018a)是一种深层语境化的单词表示法,在我们的实验中用于所有语言,因为Che et al.(2018)为许多其他语言11提供了ELMo,包括汉语、加泰罗尼亚语和西班牙语。我们使用ELMo表示的所有层上的平均权重,并将其与输入表示u连接。我们的模型通过小批量随机梯度下降(SGD)进行优化,学习率为0.01,批量大小为10。L2正则化参数为1e-8。超参数是根据OntoNotes英语开发集的性能选择的。
4.1主要结果
表3显示了我们的工作与之前在OntoNotes英语数据集上的工作之间的性能比较。如果没有LSTM层(即L=0),与基线BiLSTMCRF(L=0)相比,具有依赖信息的拟议模型在F1中显著提高了NER性能,得分超过2分,这证明了依存关系对命名实体识别任务有效果。我们表现最好的BiLSTM CRF基线(带手套)F1得分为87.78,优于或与之前的工作持平。BiLSTM-GCN-CRF模型的性能优于BiLSTM-CRF模型,但与建议的DGLSTM-CRF模型相比,其性能较差。我们认为,通过堆叠GCN层来保存周围的上下文信息是一个挑战,而上下文信息对于NER很重要。总体而言,2层DGLSTM-CRF模型显著(p<0.01)优于最佳BiLSTM-CRF基线和BiLSTM-GCN-CRF模型。从表中可以看出,增加层数(例如,L=3)并不能进一步改善BiLSTM CRF和DGLSTM-CRF,因为此类三阶信息(例如,单词parent、其祖父母和曾祖父母之间的关系)在指示命名实体的存在方面不起重要作用。
我们进一步将所有模型的性能与ELMo(Peters et al.,2018a)表示进行比较,以研究上下文化的单词表示是否会减少依赖性的影响。当L=0时,与仅嵌入单词的BiLSTM-CRF模型相比,ELMo表示大大提高了BiLSTM-CRF的性能,但仍比我们的DGLSTM-CRF模型低1个百分点。2层DGLSTM-CRF模型优于最佳BilSTM-CRF基线,F1得分为0.9分(p<0.001)。根据经验,我们发现,在DGLSTM-CRF正确预测但BiLSTM-CRF错误预测的实体中,47%的实体长度超过2。我们的发现表明,2层DGLSTM-CRF模型能够准确识别长实体,从而提高精度。此外,DGLSTMCRF正确检索到的实体中,有51.9%具有依赖关系“pobj”、“nn”和“nsubj”,它们与某些命名实体类型具有很强的相关性(图3)。这一结果证明了依赖关系在提高NER召回率方面的有效性。
OntoNotes Chinese表4显示了中文数据集的性能比较。我们将我们的模型与最先进的模型进行比较,我们实现的强BiLSTM-CRF基线与Lattice LSTM的性能相当。与英语数据集类似,与BiLSTM-CRF(L=0)模型相比,L=0的模型显著提高了性能。我们的DGLSTM-CRF模型在L=2时达到最佳性能,并且始终优于BiLSTM-CRF强基线(p<0.02)。从表中可以看出,与BiLSTM模型相比,DGLSTM-CRF模型的改进主要来自回忆(p<0.001),尤其是在仅嵌入单词的情况下。经验上,我们还发现,那些正确检索到的DGLSTM-CRF实体(与基线相比)主要与以下依赖关系相关:“nn”、“nsubj”、“nummod”。然而,与BiLSTM CRF相比,DGLSTM-CRF的精度较低,这表明DGLSTM-CRF模型的预测更为假阳性。原因可能是如表2所示,ST(%)的比率相对较低,这意味着一些实体没有在完整的依赖树下形成子树。在这种情况下,模型可能无法正确识别实体的边界,从而导致精度较低。
通过使用ELMO表示,2层的DGLSTM-CRF比一层的表现更好,此外,大多数这些实体都包含孙依赖项“(sn,sn)”和“(spec,sn)”,其中sn表示两个数据集中的名词短语,spec表示说明符(例如,限定词、量词)。这样的发现表明,2层模型能够捕获孙子依赖项所提供的交互。
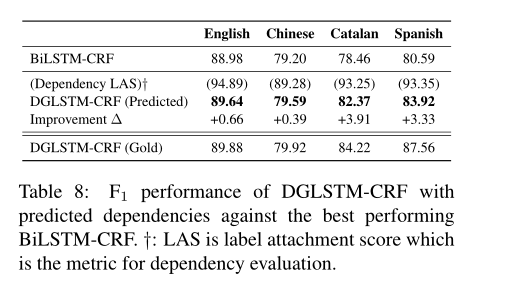
Effect of Dependency Quality依赖质量的影响为了评估依赖树的质量如何影响性能,我们使用我们的训练集训练了一个最先进的依赖解析器(Dozat和Manning,2017),并对开发/测试集进行预测。我们使用AllenNLP包实现了依赖关系解析器(Gardner et al.,2017)。表8显示了四种语言(即OntoNotes英语、OntoNotes汉语、加泰罗尼亚语和西班牙语)上依赖关系解析器的性能(LAS),以及DGLSTM-CRF相对于ELMo的最佳BiLSTM CRF的性能。DGLSTMCRF即使具有预测的依赖项,也能够在四种语言上始终优于BiLSTM CRF。然而,性能仍然比依赖黄金的DGLSTM-CRF差,尤其是在加泰罗尼亚语和西班牙语上。这些结果表明,为所提出的模型提供高质量的依赖性注释是至关重要的。
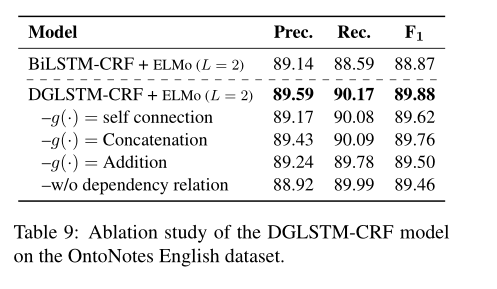
消融实验表9显示了OntoNotes英语数据集上2层DGLSTM-CRF模型的消融研究。以self-connection作为交互函数,F1下降0.3分。该模型的性能与作为交互函数的串联相当,但使用加法交互函数时,F1下降了约0.4个点。我们认为,添加可能会导致某些信息丢失。没有了依存关系编码,F1值下降了百分之 0.4
5分析
5.1依存关系的有效性
为了证明该模型是否从依赖关系中受益,我们首先选择由2层DGLSTM-CRF模型正确预测的实体,而不是由OntoNotes English数据集上性能最好的基线2层BiLSTM CRF预测的实体。我们根据这些实体绘制了图4中的热图。比较图3和图4,我们可以看到它们在密度方面是相似的。它们都显示了实体类型和依赖关系之间的一致关系。比较表明,改进的部分原因是依赖关系的影响。我们还从模型的预测中发现,一些实体类型与孙辈依赖关系对有很强的相关性。
5.2具有不同长度的实体
表10显示了所有数据集上不同实体长度的性能比较。如前所述,依赖关系和孙子关系允许我们的模型捕获单词之间的远程交互。如表所示,对于除中文以外的所有语言,使用DGLSTM-CRF,长度大于1的实体的性能都会不断提高。正如我们在数据集统计数据(表2)中指出的那样,与其他数据集相比,在OntoNotes中文中形成子树的实体数量相对较少。我们发现,在英语中长度大于2的实体的改进中,85%的实体具有长距离依赖,30%的实体边界内具有孙依赖。分析表明,利用依赖树结构的模型有助于识别长实体。
6结论和未来工作
基于依赖树与命名实体之间的关系,我们提出了一种依赖导向的LSTM-CRF模型,对完整的依赖树进行编码,并为NER任务捕获这种关系。通过在多个数据集上的大量实验,我们证明了所提出的模型在改善NER性能方面的有效性。我们的分析表明,NER得益于依赖关系和长距离依赖,它们能够捕获单词之间的非局部交互。统计数据显示,大多数实体在依赖树下形成子树,未来的工作包括构建一个用于联合NER和依赖解析的模型,该模型将每个实体视为依赖树中的单个单元。
