
基于方面情感分析的关系图注意网络
最近的研究采用了基于注意的神经网络模型来隐式地将方面与意见词联系起来。然而,由于语言的复杂性和一个句子中多个方面的存在,这些模型经常混淆连接。在本文中,我们通过有效的语法信息编码来解决这个问题。
我们定义了一个统一的面向方面的依赖树结构,该结构通过对普通的依赖解析树进行整形和剪枝来植根于目标方面。然后,我们提出了一种关系图注意网络(R-GAT)来编码新的情感预测树结构。在SemEval 2014和Twitter数据集上进行了大量实验,实验结果证实,我们的方法可以更好地建立方面和观点词之间的联系,因此,图形注意网络(GAT)的性能显著提高。
将各个方面与它们各自的观点词汇联系起来方面级情感分析任务的核心。
主要的贡献:
1.我们提出了一种面向方面的树结构,通过对普通依赖树进行整形和剪枝来关注目标方面
2.我们提出了一个新的GA T模型来编码依赖关系,并建立方面和观点词之间的联系。
图注意力网络(GAT)
图数据结构有两种特征,图的结构关系和顶点自己的特征,graph上的deep learning方法就是学习这两种特征。
GCN(https://zhuanlan.zhihu.com/p/81350196?utm_source=wechat_session)
GCN模型的输入X是一个N*D维的矩阵,N是输入图节点的个数,D是输入的特征维度,他们都与图的结构本身有关,因此不能处理inductive任务。
GCN的局限性:
无法完成inductive任务,即处理动态图问题。GCN在计算的过程中用到了图的邻接矩阵和度量局矩阵,这与图的结构有关,如果图的结构变化了,图的矩阵也要发生变化,这就需要重新训练模型。inductive任务是指:训练阶段与测试阶段需要处理的graph不同。通常是训练阶段只是在子图(subgraph)上进行,测试阶段需要处理未知的顶点。
处理有向图的瓶颈,不容易实现分配不同的学习权重给不同的neighbor。
由此出现了GAT神经网络,GAT的运算有两种方式:
Global graph attention:每一个顶点i都对于图上任意顶点进行attention运算,不依赖于图结构,但是丢掉了图结构的特征,效果可能不好
Mask graph attention:注意力机制只在邻居顶点上进行
GAT运算过程:
比如计算i节点和其他节点的注意力系数,先用权重矩阵W与每个节点的特征向量相乘,获得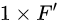 的张量,
的张量,
再将i节点与其他的所有节点进行拼接,形成一个 的张量,用一个
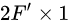 的注意力核与拼接的张量相乘,获得一个数,就是节点i与其他节点j的注意力系数,经过leakyRelu激活函数,过滤点没有边连接的节点,之后进行softmax归一化操作,根据得到的注意力系数与周围节点进行加权求和,公式如下:
的注意力核与拼接的张量相乘,获得一个数,就是节点i与其他节点j的注意力系数,经过leakyRelu激活函数,过滤点没有边连接的节点,之后进行softmax归一化操作,根据得到的注意力系数与周围节点进行加权求和,公式如下:
1.计算顶点i和它的所有邻居顶点之间的注意力系数。表示顶点i和它邻居顶点j之间的注意力系数,用一个参数w和顶点的特征表示进行乘积运算,之后将i和j计算的结果进行拼接,再放进a()这个函数中,最终得到的eij就是i和j的注意力系数。
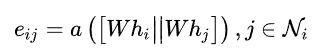
2.得到注意力系数之后,对其进行归一化。
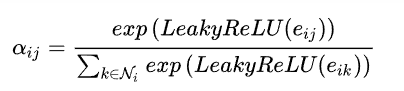
3.注意力系数进行归一化之后,再将特征进行加权求和,之后的输出就融合了邻居顶点的信息。第二个式子是多头注意力机制的算法。
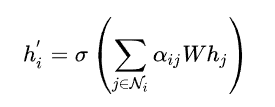

GAT的复杂度:(https://zhuanlan.zhihu.com/p/81350196?utm_source=wechat_session)

GAT适合inductive任务的原因,inductive就是训练和预测图的结构不一样,因为模型是逐点进行运算的,模型的参数只与特征维度有关,与图的结构无关。

