
论文--大规模情感词典的构建及其在情感分类中的应用
论文主要基于海量的微博数据,使用简单的文本统计算法,构建了一个十万词语的大规模情感词典。(论文地址:http://jcip.cipsc.org.cn/CN/abstract/abstract2374.shtml#)
情感词典的构建流程如下:
- 表情符种子获取,利用提前构建好的情感词语种子,在一个较小规模的微博语料上,为所有的表情符进行情感归类及重要的排序,从而为每类情感选择一些相关性较高的,具有代表性的表情符。
通过以下公式获取表情符种子:
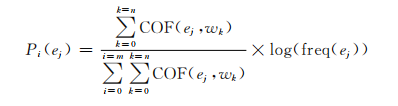
情感倾向一共是2种,因此有一个积极的情感词典和一个消极的情感词典,假设计算表情符积极倾向的情感分值,分子的中n代表的是积极的情感词典中种子词语的个数,COF计算的是表情符ej与积极情感倾向种子词wk共现的频次,分母表示的是表情符ej与积极和消极情感词典中种子词共现次数的总和,起到归一化的作用。右边的freq函数代表ej在语料中出现的频次。表情符种子得到的分值越高,代表积极情感倾向越强烈。消极表情符种子用同样的方式获取。
2.情感词语、词组情感分值计算,利用获得的表情符种子,在一个较大规模的微博语料上为所有候选情感词语计算情感分值。假设一个句子中表情符的情感倾向和微博文本本身是一样的,如果微博包含一个褒义的表情符,则认为微博是褒义的,反之是贬义的。如果同时具有褒义表情符和贬义表情符就进行舍弃,然后从微博语料中抽取候选情感词,通过PMI算法,使用具有情感倾向的表情符种子为候选情感词计算情感分值并抽取出具有情感倾向的词语。
通过此方法构建的情感词典的性能要优于清华、北大、大连理工及知网提供的情感词典。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号