
transformer模型
参考博客:https://blog.csdn.net/u012526436/article/details/86295971 讲解非常好!
模型使用 Layer normalization而不使用Batch normalization的原因见之前博客。
网络层数较深的时候会出现网络退化问题,就是层数深的神经网络比层数浅的神经网络误差还要大,这个时候可以使用残差模块来解决。(https://zhuanlan.zhihu.com/p/80226180)
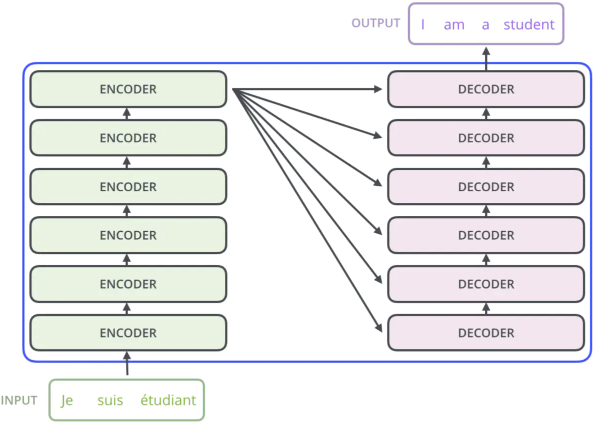
- transformer模型总述
transformer是一个简单的模型,仅仅依赖于注意力机制,并没有用到RNN和CNN,他有编码器和解码器,编码器有两个子层,一个是multi-head self-attention(它的讲解看最上面的博客),另一个是前馈神经网络。解码器有三个子层,有两个层和编码器是一样的,还有一个层加入了MASK的multi-head self-attention(多头注意力机制),这个层是在t时刻预测输出时不能看到t时刻以后的输入,保证训练和预测是一致的。
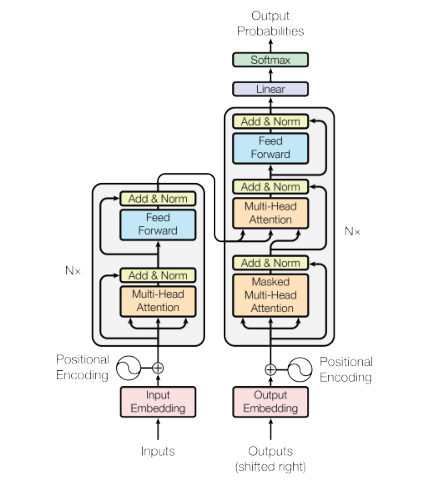
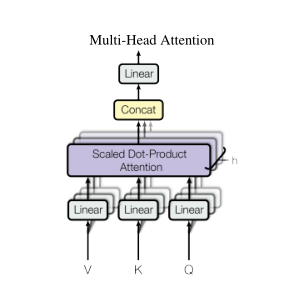
- transformer模型三个注意力机制的区别
在transformer中一共有三个地方用到了注意力机制,左边的attention的输入就是输入句子转化的向量,k q v三个向量实际上是一样的,都是表示一个词,q和k计算一个词与句子中每个词的相似度,之后对每个v进行加权求和,这就是自注意力机制。右边的MASKed multi-head self-attention就是在t时刻预测输出时不能看到t时刻以后的输入,其他是一样的。但是右边的multi-head self-attention并不是自注意力机制,它的k和v向量来自编码器的输出,q向量来自上一个多头注意力机制的输出,计算k和q向量的相似度,然后再对v向量进行加权求和。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号