
Multi-Channel PCIe QDMA Subsystem
 基于PCI Express Integrated Block,Multi-Channel PCIe QDMA Subsystem实现了基于DMA地址队列的高性能Continous或Scather Gather DMA,提供FIFO/AXI4-Stream用户接口。
基于PCI Express Integrated Block,Multi-Channel PCIe QDMA Subsystem实现了基于DMA地址队列的高性能Continous或Scather Gather DMA,提供FIFO/AXI4-Stream用户接口。
可交付资料:
- 详细的用户手册
- Design File:Post-synthesis EDIF netlist or RTL Source
- Timing and layout constraints,Test or Design Example Project
- 技术支持:邮件,电话,现场,培训服务
联系方式:
Email:neteasy163z@163.com
1 介绍
基于PCI Express Integrated Block,Multi-Channel PCIe QDMA Subsystem实现了基于DMA地址队列的高性能Continous或Scather Gather DMA,提供FIFO/AXI4-Stream用户接口。
1.1 特性
- 支持Ultrascale+,Ultrascale,7 Series的PCI Express Integrated Block
- 支持64,128,256,512-bit数据路径
- 64-bit源地址,目的地址,和描述符地址
- 多达16个host-to-card(H2C/Read)数据通道或H2C DMA
- 多达16个card-to-host(C2H/Write)数据通道或C2H DMA
- FIFO/ AXI4-Stream用户接口(每个通道都有自己的FIFO/AXI4-Stream接口)
- 每个DMA引擎支持DMA地址队列,队列深度可达32
- AXI4-Lite Master接口允许PCIe通信绕过DMA引擎
- Scather Gather描述符列表支持无限列表大小
- 每个描述符的最大传输长度为4GB
- MSI中断
- 连续描述符的块获取
- 中断或查询模式
1.2 应用
本内核体系结构支持广泛的计算和通信目标程序应用,强调性能、成本、可扩展性、功能可扩展性和关键任务可靠性。典型应用包括:
● 数据通信网络
● 电信网络
● 宽带有线和无线应用
● 网络接口卡
● 用于各种应用程序的服务器add-in card
典型应用如下图所示:

图 1 Multi-Channel PCIe QDMA Subsystem典型应用:8通道视频采集和视频显示
2 概述
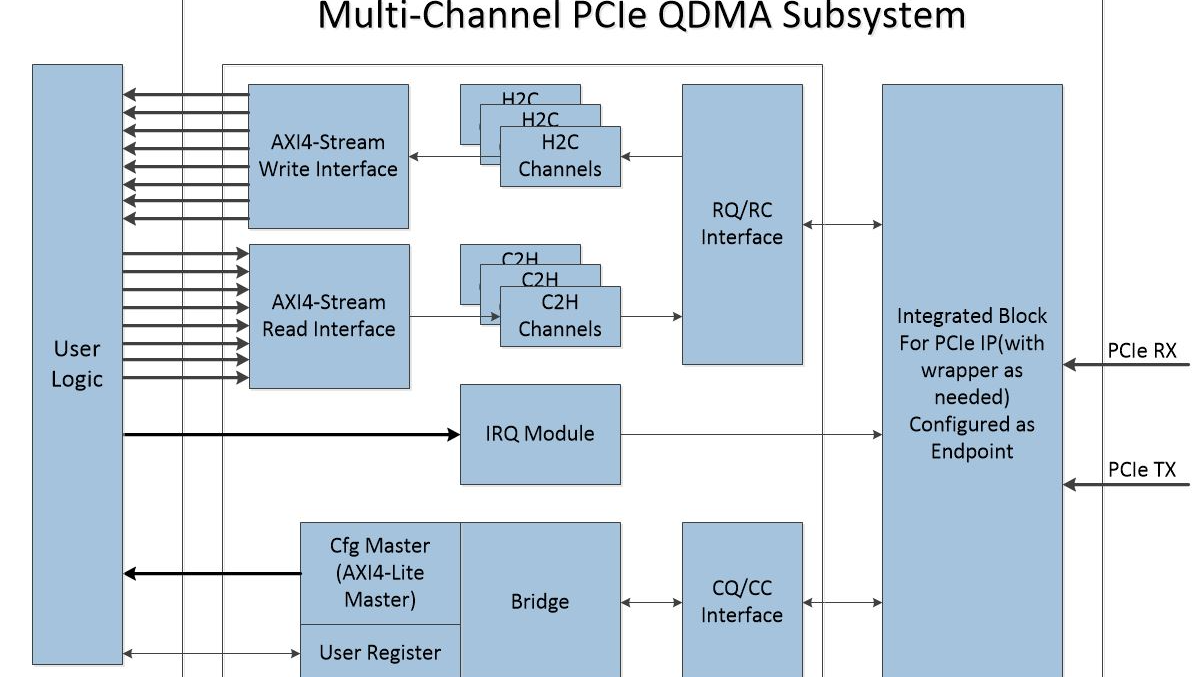
Multi-Channel PCIe QDMA Subsystem作为一个高性能DMA数据搬移器,内核通过AXI4-Stream接口直接连接RTL逻辑。使用提供的字符驱动程序,AXI4-Stream接口可用于PCIe地址空间和AXI地址空间之间的高性能数据搬移。除了基本的DMA功能,DMA支持多达16个upstream和downstream通道,每个通道支持深度为32的DMA地址队列,另外还允许PCIe通信绕过DMA引擎。

图 2 Multi-Channel PCIe QDMA Subsystem概述
2.1 特性概要
基于描述符提供的信息:源地址,目的地址和传输数据长度,Multi-Channel PCIe QDMA Subsystem实现Host存储器和PCIe DMA子系统之间的数据搬移。这些DMA可以同时是Host to Card(H2C)和Card to Host(C2H)传输。每个DMA通道对应各自的AX4-Stream接口,DMA从Host存储器获取并解析描述符链表,基于描述符链表信息完成自己通道的数据传输,然后使用MSI中断发出描述符完成或错误的信令。内核也提供多达16个输出到Host的用户中断信号。
主机可以通过以下2个接口访问用户逻辑:
- AXI-Lite Master配置接口:这个接口是一个固定的32-bit端口,用于对性能要求不高的用户配置和状态寄存器的访问
- User Register:这个接口是多个32-bit向量信号和1-bit信号,这些信号来自对应DMA通道数据搬移过程中产生的控制或状态信号
3 产品规格
结合Integrated Block for PCI Express IP,Multi-Channel PCIe QDMA Subsystem为PCIe提供了一个高性能的DMA解决方案。
3.1 性能
Endpoint配置参数:Max Payload Size=256-byte,Max Read Request Size=512-byte
8-Channel PCIe-SGQDMA Subsystem,DMA Transfer Length = 4MB
表1 PCIe 3.0 x16 C2H DMA速率
|
|
DMA0 |
DMA1 |
DMA2 |
DMA3 |
DMA4 |
DMA5 |
DMA6 |
DMA7 |
|
速率 |
1660MB/s |
1660MB/s |
1660MB/s |
1660MB/s |
1660MB/s |
1660MB/s |
1660MB/s |
1660MB/s |
表2 PCIe 3.0 x16 H2C DMA速率
|
|
DMA0 |
DMA1 |
DMA2 |
DMA3 |
DMA4 |
DMA5 |
DMA6 |
DMA7 |
|
速率 |
1670MB/s |
1670MB/s |
1670MB/s |
1670MB/s |
1670MB/s |
1670MB/s |
1670MB/s |
1670MB/s |
表3 PCIe 3.0 x8 C2H DMA速率
|
|
DMA0 |
DMA1 |
DMA2 |
DMA3 |
DMA4 |
DMA5 |
DMA6 |
DMA7 |
|
速率 |
880MB/s |
880MB/s |
880MB/s |
880MB/s |
880MB/s |
880MB/s |
880MB/s |
880MB/s |
表4 PCIe 3.0 x8 H2C DMA速率
|
|
DMA0 |
DMA1 |
DMA2 |
DMA3 |
DMA4 |
DMA5 |
DMA6 |
DMA7 |
|
速率 |
890MB/s |
890MB/s |
890MB/s |
890MB/s |
890MB/s |
890MB/s |
890MB/s |
890MB/s |
表5 PCIe 2.0 x8 C2H DMA速率
|
|
DMA0 |
DMA1 |
DMA2 |
DMA3 |
DMA4 |
DMA5 |
DMA6 |
DMA7 |
|
速率 |
450MB/s |
450MB/s |
450MB/s |
450MB/s |
450MB/s |
450MB/s |
450MB/s |
450MB/s |
表6 PCIe 2.0 x8 H2C DMA速率
|
|
DMA0 |
DMA1 |
DMA2 |
DMA3 |
DMA4 |
DMA5 |
DMA6 |
DMA7 |
|
速率 |
455MB/s |
455MB/s |
455MB/s |
455MB/s |
455MB/s |
455MB/s |
455MB/s |
455MB/s |
3.2 资源
8-Channel PCIe-SGQDMA Subsystem
表7 PCIe 3.0 x16 DMA Subsystem资源
|
|
LUTs |
FFs |
BRAMs |
PCIe |
|
资源 |
46985 |
101938 |
150 |
1 |
表8 PCIe 3.0 x8 DMA Subsystem资源
|
|
LUTs |
FFs |
BRAMs |
PCIe |
|
资源 |
26388 |
51935 |
78 |
1 |
表9 PCIe 2.0 x8 DMA Subsystem资源
|
|
LUTs |
FFs |
BRAMs |
PCIe |
|
资源 |
26945 |
38687 |
55 |
1 |
8-Channel PCIe-CQDMA Subsystem
表10 PCIe 3.0 x16 DMA Subsystem资源
|
|
LUTs |
FFs |
BRAMs |
PCIe |
|
资源 |
34976 |
75994 |
150 |
1 |
表11 PCIe 3.0 x8 DMA Subsystem资源
|
|
LUTs |
FFs |
BRAMs |
PCIe |
|
资源 |
19364 |
37487 |
78 |
1 |
表12 PCIe 2.0 x8 DMA Subsystem资源
|
|
LUTs |
FFs |
BRAMs |
PCIe |
|
资源 |
20973 |
29963 |
55 |
1 |
3.3 内核Component
内核内部实现多达32个独立的物理DMA引擎(多达16个C2H和16个H2C)。这些DMA引擎被映射到各自的AXI4-Stream用户应用接口。AXI4-Stream接口只传递数据。
通道的类型配置决定了在哪个总线上进行事务传输。
- Host-to-Card(H2C)通道向PCIe产生读请求,然后给用户应用提供数据
- 同样,Card-to-Host(C2H)通道等待用户侧的数据,然后向PCIe产生写请求(包含接收到的数据)
Host通过AXI4-Lite Master接口访问用户逻辑的配置和状态寄存器。这些请求是32-bit的读或写。
3.3.1 Target Bridge
Target bridge从Host接收请求。基于BARs,这些请求通过AXI4-Lite Master接口传递到内部的目标用户。下行用户逻辑返回non-post请求的数据后,target bridge产生一个读返回TLP,然后通过CC总线发送给PCIe IP。
PCIe BARs配置如下表所示。
表13 32-bit BARs
|
BAR0(32-bit) |
BAR1(32-bit) |
|
DMA |
PCIe to AXI4-Lite Master |
3.3.2 H2C通道
H2C通道处理host-to-card的DMA传输。根据最大读请求大小和可用的内部资源,H2C通道负责拆分这些读请求。读取请求的每个拆分(如果有)都会消耗一条额外的读取请求条目。DMA通道向PCIe RQ模块发出读请求后,直到按顺序接收到用户接口的写完成确认,这个读请求才算完成。在数据传输完成后,DMA通道向Host发出一个中断。
H2C通道会根据配置的最大读请求大小和数据FIFO可用空间来拆分Host读接口上的数据传输。从PCIe RC模块输出的读请求返回完成数据包会存储到已分配的数据FIFO中。为了减少数据传输延时,一旦接收到任何一个完成数据包,H2C通道就开始把读取的数据输出到AXI4-Stream Write接口。
3.3.3 C2H通道
C2H通道处理card-to-host的DMA传输。在AXI4-Stream Read接口接收数据之前,C2H通道首先接收DMA描述符,建立DMA传输的环境,然后在准备好请求ID和启用C2H通道后,通道的AXI4-Stream接口可以接收数据并对主机执行DMA。在数据传输完成后,DMA通道向Host发出一个中断。
3.3.4 AXI4-Lite Master
Host使用这个接口向用户逻辑发出32-bit读和32-bit写请求。通过PCIe总线接收读或者写请求,路由到AXI-Lite Master BAR中,target bridge通过PCIe IP CC总线返回读取的完成数据。
3.3.5 IRQ Module
IRQ module接收来自用户逻辑中断请求和每个DMA通道的独立中断线。这个模块通过PCIe向Host产生MSI中断。
3.3.6 DMA操作
从DMA的原理出发,PCIe DMA引擎通常在Host内存和驻留在FPGA中的内存之间搬移数据,FPGA的内存通常(但不总是)位于add-in板卡。当数据从Host内存搬移到FPGA内存时,称为Host to Card(H2C)传输。相反,当数据从FPGA内存搬移到Host内存,称为Card to Host(C2H)传输。
在通常的操作中,Host中的应用程序必须在FPGA和Host内存之间搬移数据。为了完成此次传输,Host在系统内存中设置缓冲区空间,并创建DMA引擎用于搬移数据的描述符。
Multi-Channel PCIe QDMA Subsystem使用连续的描述符链表,单个描述符指定了地址和DMA传输长度。Host驱动创建描述符链表,并存储在Host内存。Host驱动只需要少量控制寄存器就可以初始化DMA通道,接着该DMA通道就开始去获取描述符链表并执行DMA操作。
描述符描述了Multi-Channel PCIe QDMA Subsystem执行的内存传输。每个DMA通道有自己的描述符链表。Host驱动通过硬件寄存器初始化每个DMA通道描述符链表的起始地址。在启动DMA通道后,该DMA通道开始从起始地址获取描述符。
EOP控制比特显示描述符链表的终止。当DMA通道检测到某个描述符的EOP控制比特后,会停止获取该描述符链表。EOP控制比特只能在描述符链表的最后一个描述符中被设置。
描述符格式如下表所示。
表14 描述符格式
|
Offset |
Fields |
|
0x0 |
Bit 31:EOP Bit 30~16:保留 Bit 15~0:Magic,常数16’hAD4B |
|
0x4 |
DMA Transfer Length |
|
0x8 |
Address[31:0] |
|
0xC |
Address[63:32] |
Address:64-bit,Destination address for C2H或Source address for H2C
EOP:1-bit,End of packet for stream data
DMA Transfer Length:32-bit,Length of data in bytes
3.4 端口描述
Multi-Channel PCIe QDMA Subsystem直接和integrated block for PCIe连接。和PCIe integrated block IP数据路径接口的宽度是64,128,256或512-bit,时钟频率最高可达250MHz。除了AXI4-Lite Master接口,数据路径宽度适用于所有数据接口。AXI4-Lite Master接口的宽度固定为32-bit。
以下列表描述了这个IP的端口(默认数据路径接口宽度是512-bit,PCIe接口是x16)。
表15 参数定义
|
参数名称 |
描述 |
默认值 |
|
CNUM |
H2C和C2H的通道数量 |
8 |
|
C2H_BUF_BRAM_CASCADE_DEPTH |
C2H数据缓冲区的BRAM级联深度 0:BRAM深度=29=512 1:BRAM深度=29+1=1024 …… N:BRAM深度=29+N |
0 |
|
C2H_BUF_USE_URAM |
C2H数据缓冲区是否使用URAM 0:不使用URAM 1:使用URAM |
0 |
|
C2H_BUF_URAM_CASCADE_DEPTH |
H2C数据缓冲区的URAM级联深度 0:URAM深度=212=4096 1:URAM深度=212+1=8192 …… N:URAM深度=212+N |
0 |
|
H2C_BUF_BRAM_CASCADE_DEPTH |
H2C数据缓冲区的BRAM级联深度 0:BRAM深度=29=512 1:BRAM深度=29+1=1024 …… N:BRAM深度=29+N |
0 |
|
H2C_BUF_USE_URAM |
H2C数据缓冲区是否使用URAM 0:不使用URAM 1:使用URAM |
0 |
|
H2C_BUF_URAM_CASCADE_DEPTH |
C2H数据缓冲区的URAM级联深度 0:URAM深度=212=4096 1:URAM深度=212+1=8192 …… N:URAM深度=212+N |
0 |
表16 顶层接口信号
|
信号名称 |
输入输出 |
描述 |
|
pcie_trn_clk |
输出 |
PCI Express Transaction接口时钟 |
|
pcie_trn_reset_n |
输出 |
PCI Express Transaction复位,低有效 |
|
trn_lnk_up |
输出 |
PCI Express Transaction Link Up信号,高有效 |
表17 PCIe接口信号
|
信号名称 |
输入输出 |
描述 |
|
pcie_refclk_p |
输入 |
PCI Express 接口参考时钟+ |
|
pcie_refclk_n |
输入 |
PCI Express 接口参考时钟- |
|
pcie_perst_n |
输入 |
PCI Express接口基本复位,低有效 |
|
pci_exp_txp[15:0] |
输出 |
PCI Express串行差分输出+,16通道 |
|
pci_exp_txn[15:0] |
输出 |
PCI Express串行差分输出-,16通道 |
|
pci_exp_rxp[15:0] |
输入 |
PCI Express串行差分输入+,16通道 |
|
pci_exp_rxn[15:0] |
输入 |
PCI Express串行差分输入-,16通道 |
表18 H2C通道0-CNUM-1 FIFO(FWFT)接口信号
|
信号名称 |
输入输出 |
描述 |
|
fifo_rdclk_disp [CNUM-1:0] |
输入 |
FIFO读时钟 Bit i,表示H2C通道i的读时钟 |
|
fifo_rdreq_disp [CNUM-1:0] |
输入 |
FIFO读使能,高有效 Bit i,表示H2C通道i的读使能 |
|
fifo_q_disp [512*CNUM-1:0] |
输出 |
FIFO读数据 Bit 512*(i+1)-1~512*i,表示H2C通道i的读数据 |
|
fifo_empty_disp [CNUM-1:0] |
输出 |
FIFO空,高有效 Bit i,表示H2C通道i的缓存空信号 |
|
fifo_prog_empty_disp [CNUM-1:0] |
输出 |
FIFO可编程空(阈值等于16),高有效 Bit i,表示H2C通道i的缓存可编程空信号 |
表19 C2H通道0-CNUM-1 FIFO接口信号
|
信号名称 |
输入输出 |
描述 |
|
fifo_wrclk_acq [CNUM-1:0] |
输入 |
FIFO写时钟 Bit i,表示C2H通道i的写时钟 |
|
fifo_wrreq_acq [CNUM-1:0] |
输入 |
FIFO写使能,高有效 Bit i,表示C2H通道i的写使能 |
|
fifo_data_acq [512*CNUM-1:0] |
输入 |
FIFO写数据 Bit 512*(i+1)-1~512*i,表示C2H通道i的写数据 |
|
fifo_prog_full_acq [CNUM-1:0] |
输出 |
FIFO可编程满(阈值等于深度-16),高有效 Bit i,表示C2H通道i的缓存可编程满信号 |
表20 Config AXI4-Lite Master接口信号
|
信号名称 |
输入输出 |
描述 |
|
m_axil_awaddr |
输出 |
write address |
|
m_axil_awprot[2:0] |
输出 |
write protection type |
|
m_axil_awvalid |
输出 |
write address valid |
|
m_axil_awready |
输入 |
write address ready |
|
m_axil_wdata[31:0] |
输出 |
write data |
|
m_axil_wstrb[3:0] |
输入 |
write strobes |
|
m_axil_wvalid |
输出 |
write valid |
|
m_axil_wready |
输入 |
write ready |
|
m_axil_bresp[1:0] |
输入 |
write response |
|
m_axil_bvalid |
输入 |
write response valid |
|
m_axil_bready |
输出 |
response ready |
|
m_axil_araddr[31:0] |
输出 |
read address |
|
m_axil_arprot[2:0] |
输出 |
read protection type |
|
m_axil_arvalid |
输出 |
read address valid |
|
m_axil_arready |
输入 |
read address ready |
|
m_axil_rdata[31:0] |
输入 |
read data |
|
m_axil_rresp[1:0] |
输入 |
read response |
|
m_axil_rvalid |
输入 |
read valid |
|
m_axil_rready |
输出 |
read ready |
表21 中断接口信号
|
信号名称 |
输入输出 |
描述 |
|
usr_intr_pos[15:0] |
输入 |
用户中断输入。 Bit i:用户中断#i输入,上升沿有效。 |
表22 软复位接口信号
|
信号名称 |
输入输出 |
描述 |
|
sw_srst_n |
输出 |
软复位输出,低有效。 |
表23 用户寄存器接口信号
|
信号名称 |
输入输出 |
描述 |
|
acquisition_res [32*CNUM-1:0] |
输出 |
CNUM个C2H通道的分辨率设置 Bit 32*(i+1)-1~32*i,表示C2H通道i的分辨率 |
|
display_res [32*CNUM-1:0] |
输出 |
CNUM个H2C通道的分辨率设置 Bit 32*(i+1)-1~32*i,表示H2C通道i的分辨率 |
|
acquisition_fps [32*CNUM-1:0] |
输出 |
CNUM个C2H通道的帧率设置 Bit 32*(i+1)-1~32*i,表示C2H通道i的帧率 |
|
display_fps [32*CNUM-1:0] |
输出 |
CNUM个H2C通道的帧率设置 Bit 32*(i+1)-1~32*i,表示H2C通道i的帧率 |
|
acquisition_enable [CNUM-1:0] |
输出 |
CNUM个C2H通道的采集使能,高有效 Bit i = 1,表示使能C2H通道i采集 |
|
display_enable [CNUM-1:0] |
输出 |
CNUM个H2C通道的显示使能,高有效 Bit i = 1,表示使能H2C通道i显示 |
|
acquisition_stat [32*CNUM-1:0] |
输入 |
CNUM个C2H通道的状态 Bit 32*(i+1)-1~32*i,表示C2H通道i的状态 |
|
display_stat [32*CNUM-1:0] |
输入 |
CNUM个H2C通道的状态 Bit 32*(i+1)-1~32*i,表示H2C通道i的状态 |
|
usr_ctrl[31:0] |
输出 |
控制信号输出 |
|
usr_stat[31:0] |
输入 |
状态信号输入 |


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· .NET Core 中如何实现缓存的预热?
· 从 HTTP 原因短语缺失研究 HTTP/2 和 HTTP/3 的设计差异
· AI与.NET技术实操系列:向量存储与相似性搜索在 .NET 中的实现
· 基于Microsoft.Extensions.AI核心库实现RAG应用
· Linux系列:如何用heaptrack跟踪.NET程序的非托管内存泄露
· TypeScript + Deepseek 打造卜卦网站:技术与玄学的结合
· Manus的开源复刻OpenManus初探
· .NET Core 中如何实现缓存的预热?
· 阿里巴巴 QwQ-32B真的超越了 DeepSeek R-1吗?
· 如何调用 DeepSeek 的自然语言处理 API 接口并集成到在线客服系统