
redis 缓存
一、缓存更新策略、缓存穿透、雪崩、击穿
redis 集群登陆
背景:保存用户信息和验证码,用的session,由于session数据不共享,所以启动redis
1、redis 字符串格式。set 15201672234 2345,以手机号作为key
2、输入登录码,到数据库验证是否有该手机号,没有则新增;不管新增还是不新增,保存hset 用户信息。eg: hset token userinfo name tom tel 1336767676 code 2344
3、设置过期时间30分钟,30分钟没有请求,就过期用户信息。后端有拦截器,只要有请求,就更新过期时间
redis 缓存
1、缓存的作用:降低后端负载、提高读写速度
2、缓存的成本:数据不一致、开发、运维成本提升
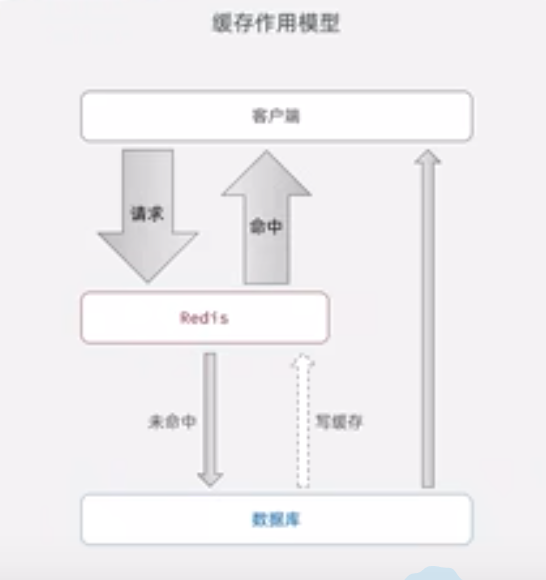
3、缓存更新策略:
自带的内存淘汰机制,内存充足,发生长时间不淘汰。
超时删除,也会发生数据不一致的情况。
主动更新,修改数据的时候,更新缓存。
先更新数据库,再删除缓存。对失效的缓存会出现短暂的数据不一致的情况。单体系统,把缓存和更新数据放在一个事务中,保持其原子性。分布式系统,tcc分布式事务。
4、缓存穿透
访问一个不存在的数据,缓存没有,数据库也没有,加大对数据库的压力,导致数据库奔溃。
解决方案
1、缓存空对象
缺点:大量空对象,可以设置过期时间减少大量空数据的缓存。数据不一致,访问为空,实际有数据,设置过期时间解决。
在逻辑处理的时候,判断缓存对象是否为空,例如,不空返回信息,否则,返回不存在。
2、布隆过滤器,将所有数据库ID,进行哈希算法以二进制的形式存储在数组里。并不是百分百的准确,有误判情况。优点空间占用少。
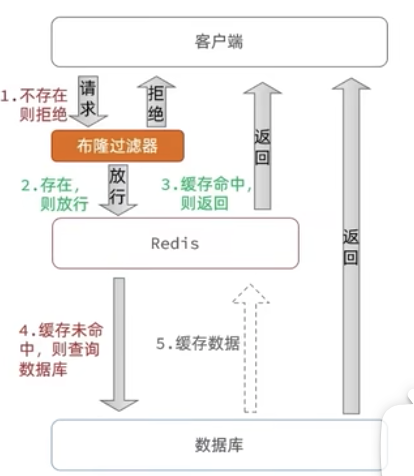
5、缓存雪崩
大量缓存同时失效或者redis服务宕机,导致大量请求到达数据库,给数据库造成压力。
解决方案
1、大量缓存同时失效。对数据设置随机过期时间。
2、redis服务宕机。部署redis集群。
3、给缓存业务,降级限流。
4、给业务增加多级缓存。例如“浏览器缓存、Nginx服务缓存、redis缓存。
6、缓存击穿
高频次高并发的、业务复杂的sql,访问的缓存没了,给数据库造成压力。(高并发的热点key 失效)
重建数据的时间比较长,导致在这段时间内,获取数据的请求全跑到了数据库里。
解决方案
1、互斥锁
当请求获取数据,正在重建数据中,另外一个请求又来了,也去重建数据,导致大量资源全在重建同样的数据。
解决方案,第一次重建数据的过程中,开辟一个新线程,加锁,建完后,释放锁。原来的线程直接返回旧的数据(哪里来的旧数据?),缺点暂时性的数据不一致。另外一个请求来了获取互斥锁,加睡眠时间,过一段时间再来获取互斥锁。
缺点,所有请求都在等待数据重建完成。
互斥锁用的是setnx, key 设置后,是不可被覆盖的。防止死锁要加过期时间释放锁;设置key-value、过期时间,要保持其原子性,写法:set key value nx ex 10
2、逻辑过期
二、卖超了(其实就是消费重复问题)
并发情况下,出现卖超了。乐观锁版本号解决方案。
悲观锁,添加同步锁了,业务串联进行。效率低下。
乐观锁,不加锁,更新之前判断是否有修改。性能好,成功率低。

先判断版本号,更新的时候where 的是版本号,如果一致,证明没有人更新,进行更新操作。
如果有人更新,where 条件查询失败。
可以将版本号简化为库存号。
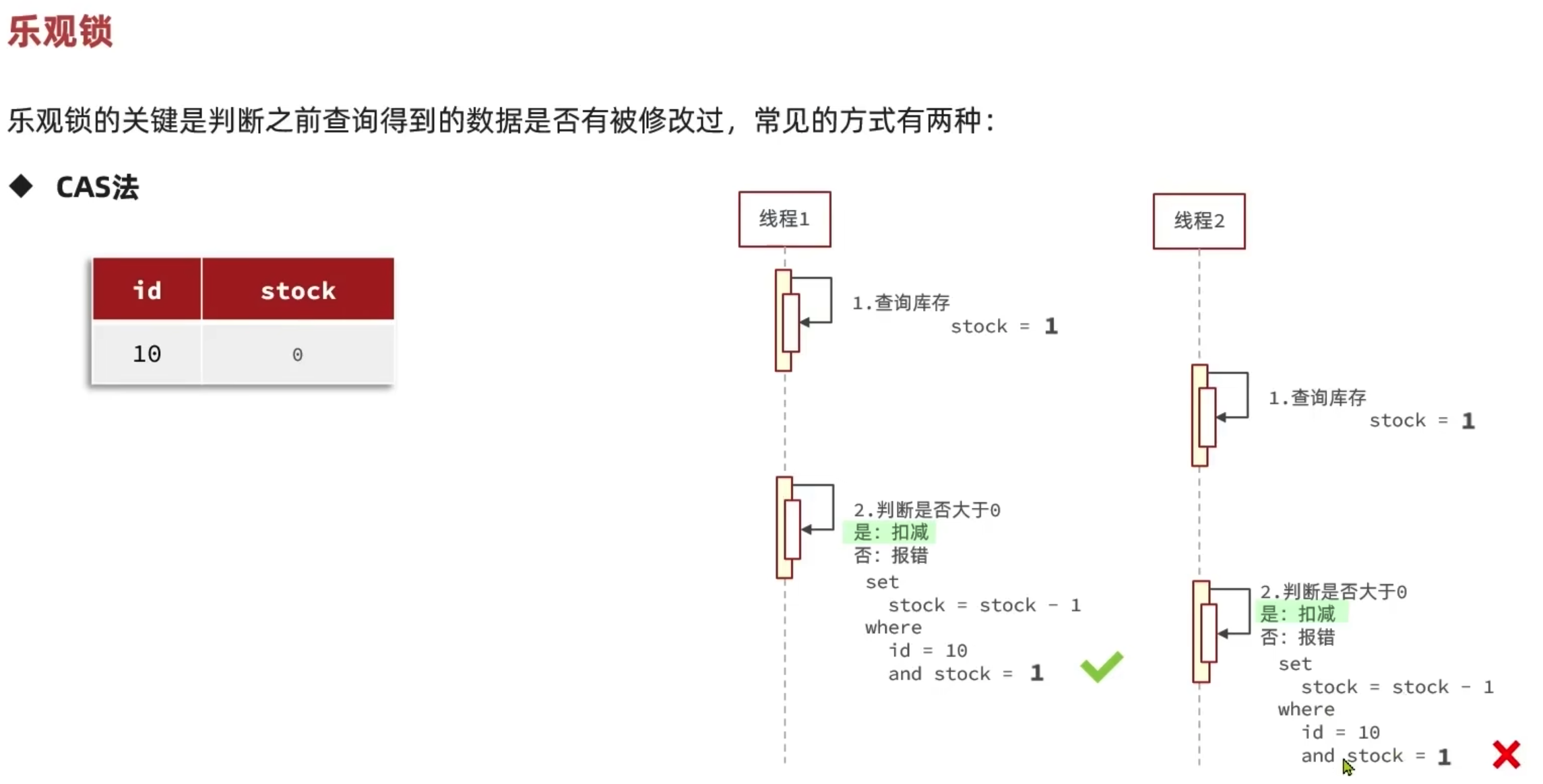
成功率低,会出现,100个库存,只抢了20多个,剩下70多个。因为stock=存库,造成sql 失败很多,修改成 stock >0,提高成功率。
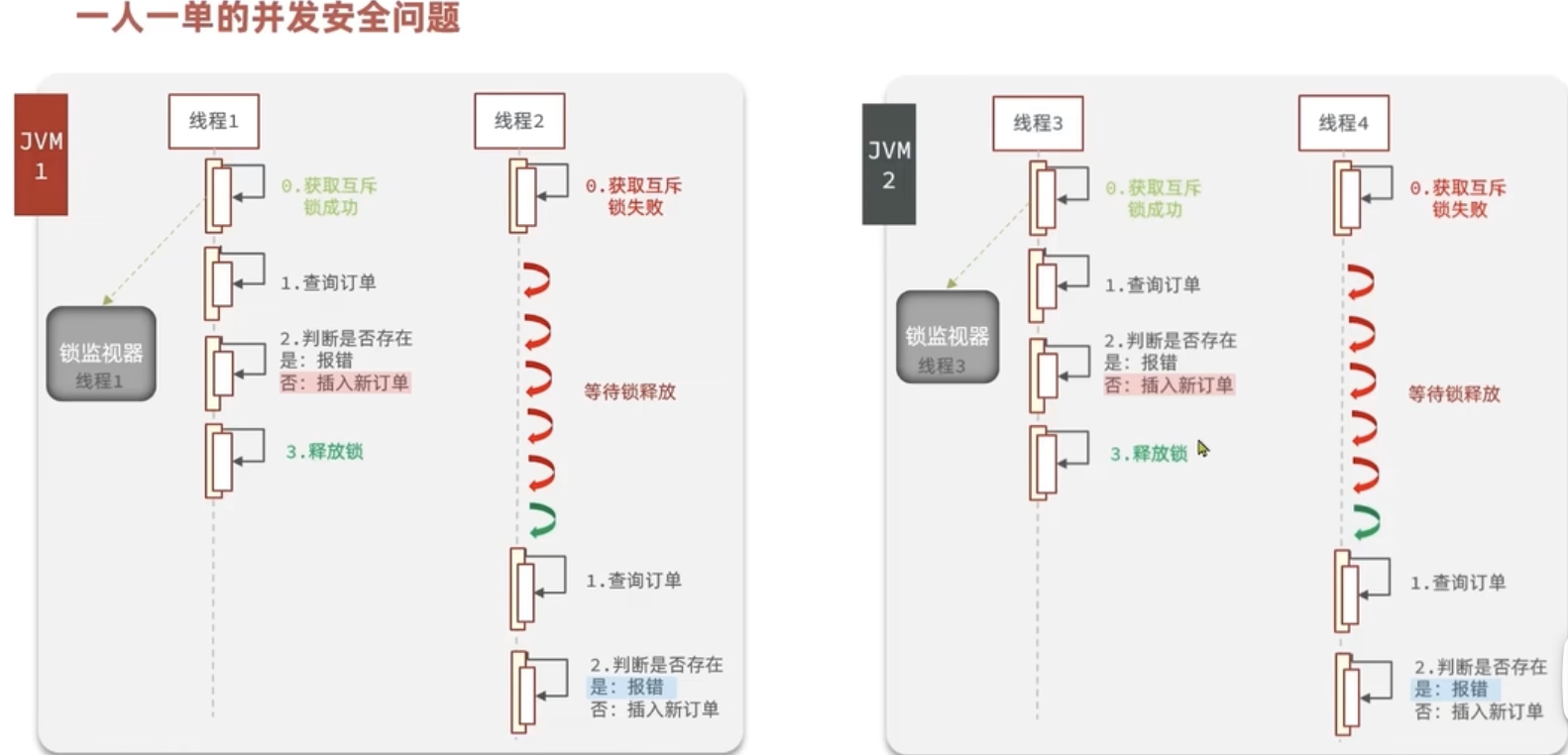
三、一人一单
在修改库存之前,判断订单数据库有没有用户id,如果有,就返回,“用户只能抢一张优惠券”。还需要给用户ID加锁,一个用户只能抢一单。
流程:判断活动开始结束时间、库存——>给用户ID加锁,订单数据库有没有用户id——>版本号库存法更新库存,加事务
此方法用的是悲观锁。
以上适用于单机,如果是集群模式,会发生同一个用户抢2单的情况。因为是多台服务,每天服务是一把锁,每台机器的锁资源不共享。
四、分布式锁
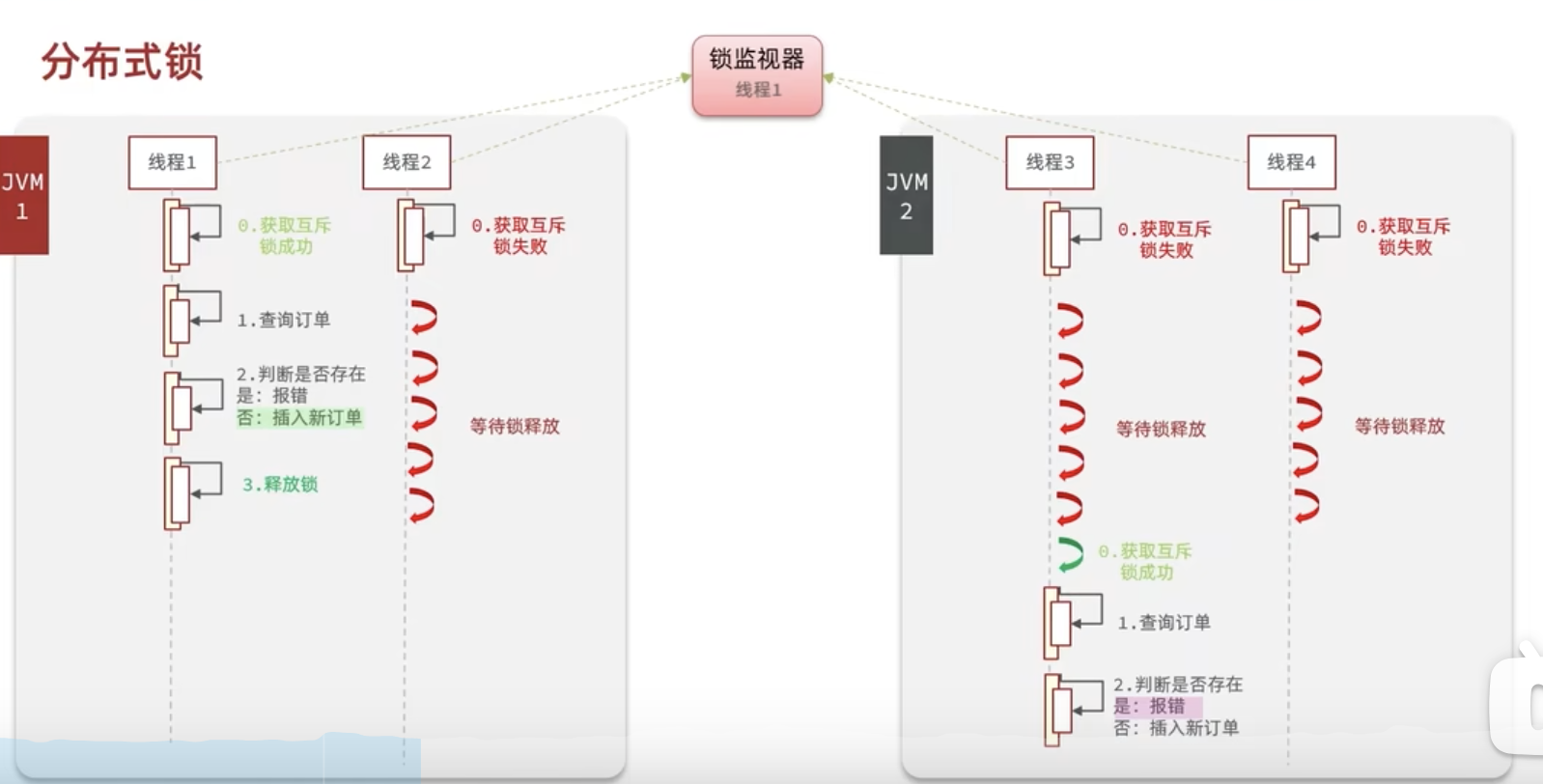
分布式锁:多线程可见、互斥、高可用。用redis

分布式锁还存在一个问题,阻塞时间太长,A业务没有执行完成,锁被释放,准备删除锁的时候,B线程乘虚而入正在执行,A将B线程删除。
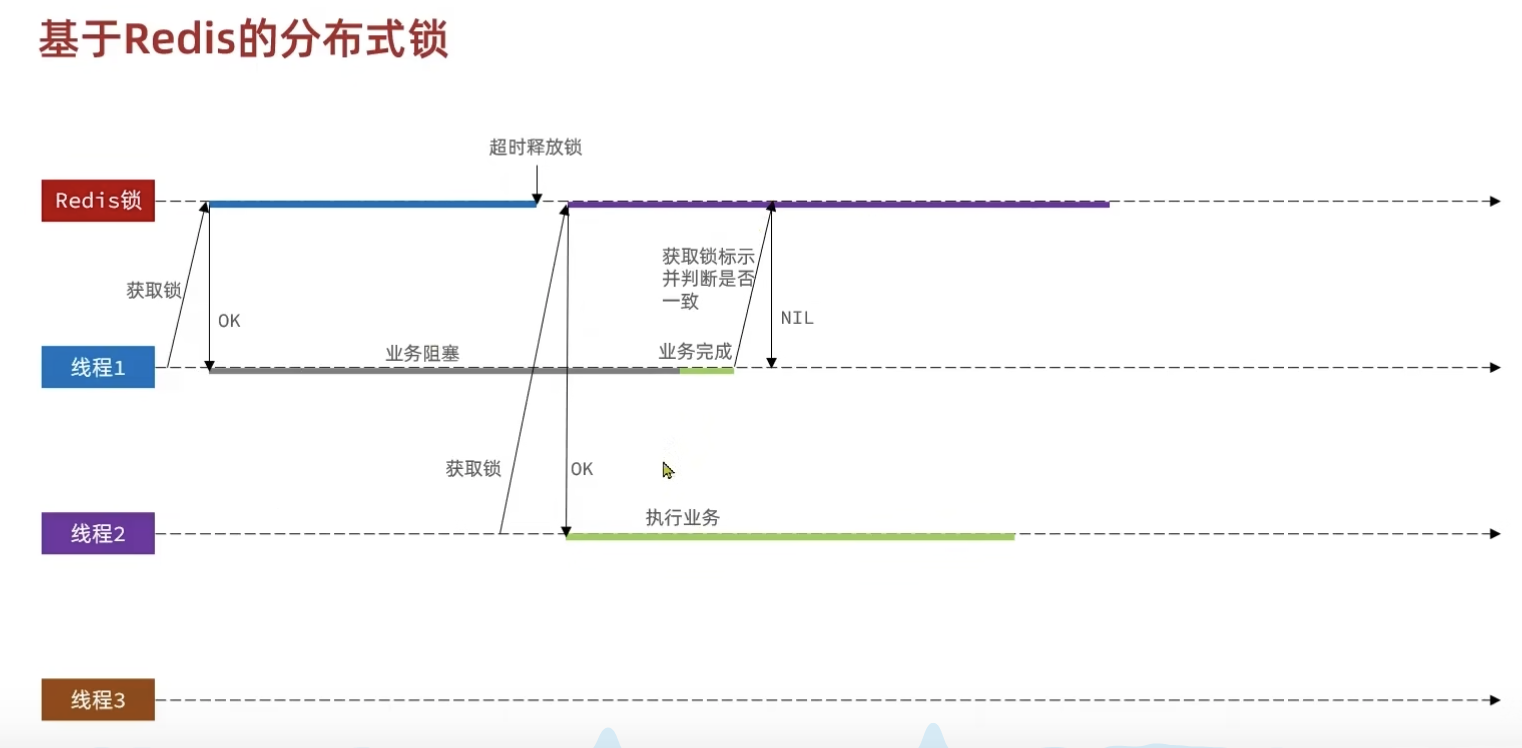
问题:删除了被人的锁
解决方案:业务是用线程ID+UUID(因为集群模式下,线程ID会一致)做的锁key,删除锁的时候,判断是否是自己的锁,如果是自己的锁则删除,如果不是自己的锁,不删除,防止误删别人的。
问题:以上方案还是不完美,判断是否是自己的锁,然后删除锁是两个动作,在删除锁的时候,遇到阻塞(垃圾回收导致阻塞),导致锁超时被删除,线程B获取锁执行,出现并发,数据重复。
解决方案:判断是否是自己的锁与删除锁,放在同一事务中,保持其原子性。
知识点:redis的原子性具有局限性,有执行成功的,有执行失败的,redis 不会回滚。用Lua脚本来保持redis的原子性,将判断与删除放在Lua 脚本里。
五、Lua脚本


五、分布式锁——redisson
以上方案较为成熟,可解决大部分问题。但是还存在以下问题,不过这些问题不解决也可用。

redisson 可解决上面问题。

redis 重入原理
redis可重入,同一进程,可以多次获取锁,获取几次,最后就要释放几次。用hset lock thread 1 , hset lock thread 2,代表获取了2次锁。执行完业务,再删除锁 del lock
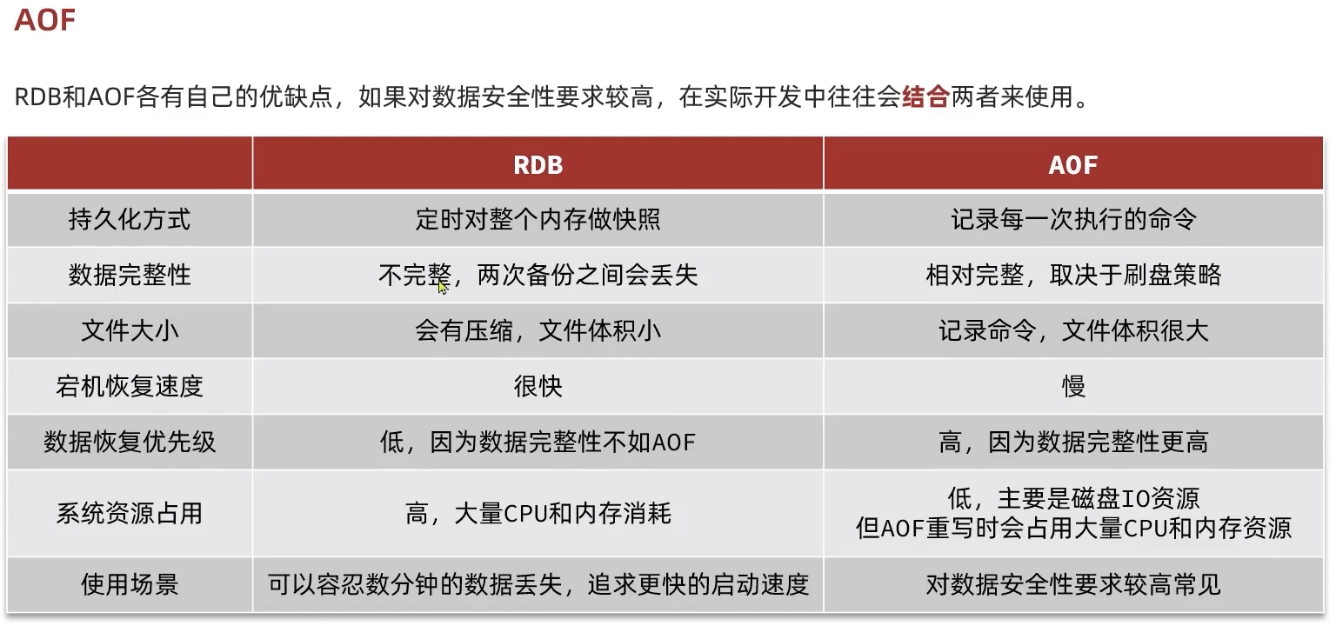
六、分布式缓存——redis 的持久化
1、默认宕机前,会自动保存
2、异步保存。在conf 文件配置,每隔多长时间修改了多少次,进行异步保存bgsave
两种持久化
六、分布式缓存——redis 哨兵机制
搭建了redis的主从集群,master 挂了,需要从slever 中选一个当master。redis 哨兵的作用 就是自动恢复主从故障。
原理是,心跳机制,检测集群ping ,是否挂了。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 25岁的心里话
· 闲置电脑爆改个人服务器(超详细) #公网映射 #Vmware虚拟网络编辑器
· 基于 Docker 搭建 FRP 内网穿透开源项目(很简单哒)
· 零经验选手,Compose 一天开发一款小游戏!
· 一起来玩mcp_server_sqlite,让AI帮你做增删改查!!