词云
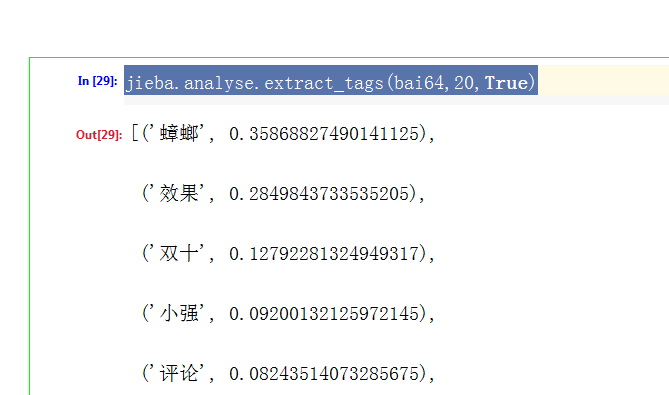
1 import pandas as pd 2 import re #正则表达式 3 import seaborn as sns 4 from matplotlib import pyplot as plt 5 import jieba #分词 6 import jieba.analyse 7 import imageio #配合做词云的 8 from wordcloud import WordCloud #词云 9 10 #windows 中文编码 11 plt.rcParams['font.sans-serif']='simhei' 12 plt.rcParams['axes.unicode_minus']=False 13 14 sns.set_style("darkgrid",{"font.sans-serif":['simhei','Droid Sans Fallback']}) 15 16 plt.rcParams['font.family'] = "KaiTi" 17 data2 = pd.read_excel(r"C:\Users\Administrator\Downloads\模块三资料\模块三资料\模块三代码文件\code\综合项目(电商文本挖掘)\data\竞争数据\评论舆情数据\安速.xlsx") 18 # print(data2.columns) 19 bai6 = list(data2['评论']) 20 # print(bai6) 21 stopwords = list(pd.read_csv(r'C:\Users\Administrator\Downloads\模块三资料\模块三资料\模块三代码文件\code\综合项目(电商文本挖掘)\data\百度停用词表.txt', 22 names=['stopwords'])['stopwords'] )#指定列名转化为列表 23 stopwords.extend([' ']) #把空格也去掉 24 print("禁用词:",stopwords) 25 print("未处理的原始数据",bai6) 26 bai61= [re.sub(r'[^a-z\u4E00-\u9Fa5]+',"",i,flags=re.I) for i in bai6] 27 print("去掉字母和中文字符",bai61) 28 bai62 = [] 29 print(len(bai61)) 30 for i in bai61: 31 sag1 = pd.Series(jieba.lcut(i)) 32 ind1 = pd.Series([len(j)>1 for j in sag1]) 33 seg2 = sag1[ind1] 34 35 ind2 = ~seg2.isin(pd.Series(stopwords)) 36 rsg3 = list(seg2[ind2].unique()) 37 if len(rsg3)>0: 38 bai62.append(rsg3) 39 print(bai62) 40 lls = [u for i in bai62 for u in i] 41 print(lls) 42 # 词频统计 43 print(pd.Series(lls).value_counts()) 44 # 构建词云需要的字符串 45 big_str = ''.join(lls) 46 print(big_str) 47 # 生成词云 48 #读取照片 49 mask = imageio.imread(r'C:\Users\Administrator\Downloads\模块三资料\模块三资料\模块三代码文件\code\综合项目(电商文本挖掘)\data\leaf.jpg') 50 #如果是中文的词云---字体 51 font = r'C:\Users\Administrator\Downloads\模块三资料\模块三资料\模块三代码文件\code\综合项目(电商文本挖掘)\data\SimHei.ttf' 52 wc = WordCloud( 53 background_color="white", 54 mask=mask, 55 font_path=font 56 ).generate(big_str) 57 plt.figure(figsize=(8,8)) 58 plt.imshow(wc) 59 60 plt.axis('off')#不要坐标轴 61 plt.show() 62 63 64 65 print(jieba.analyse.extract_tags(big_str,20,True))