
深度学习--项目提炼2(线性回归模型)
预测2018年,11月和12月的销售额
1 import glob #读文件 2 import os #设置工作路径 3 import pandas as pd 4 import re #正则表达式 5 import numpy as np 6 import datetime as dt #时间包 7 from sklearn.linear_model import LinearRegression 8 import seaborn as sns 9 from matplotlib import pyplot as plt 10 import jieba #分词 11 import jieba.analyse 12 import imageio #配合做词云的 13 from wordcloud import WordCloud #词云 14 15 #windows 中文编码 16 plt.rcParams['font.sans-serif']='simhei' 17 plt.rcParams['axes.unicode_minus']=False 18 19 sns.set_style("darkgrid",{"font.sans-serif":['simhei','Droid Sans Fallback']}) 20 os.chdir(r'C:\Users\Administrator\Downloads\模块三资料\模块三资料\模块三代码文件\code\综合项目(电商文本挖掘)\data') 21 os.chdir('./驱虫剂市场') 22 filenames = glob.glob('*市场近三年交易额.xlsx') #列表 23 24 25 26 def load_xlsx(filename): 27 # 抽取子类目的名字 28 colname = re.search(r'.*(?=市场)', filename).group() 29 # 读取文件 30 df = pd.read_excel(filename) 31 # 修改日期的格式 32 if df['时间'].dtypes == 'int64': 33 df['时间'] = pd.to_datetime(df['时间'], unit='D', origin=pd.Timestamp('1899-12-30')) 34 35 # 重命名列名为子类目名 36 df.rename(columns={df.columns[1]: colname}, inplace=True) 37 38 # 设置时间列作为索引 39 df = df.set_index('时间') 40 return df 41 dfs = [load_xlsx(i) for i in filenames] 42 df = pd.concat(dfs,axis=1).reset_index() #时间从大到小排序 43 month = df['时间'].dt.month 44 # 预测2018年 11、12月的数据 45 def momth_data(df,month): 46 for i in [11, 12]: 47 # 抽取对月份的数据 48 dm = df[month == i] # 2015.11 2016.11 2017.11 49 # 训练x是年份 50 xtrain = np.array(dm['时间'].dt.year).reshape(-1, 1) 51 print(xtrain)#[[2017][2016][2015]] 52 # 测试y是新增的行,对应的日期 53 ytest = [pd.datetime(2018, i, 1)] #[datetime.datetime(2018, 12, 1, 0, 0)] 54 print(ytest) 55 print(dm.columns)#Index(['时间', '灭鼠杀虫剂', '电蚊香套装', '盘香灭蟑香蚊香盘', '蚊香加热器', '蚊香液', '蚊香片', '防霉防蛀片'], dtype='object') 56 57 for j in range(1, len(dm.columns)):#1,2,3,4,5,6,7,每一列 58 print(j) 59 # 训练y是指定的列 60 ytrain = np.array(dm.iloc[:, j]).reshape(-1, 1) 61 # 回归建模 62 lm = LinearRegression().fit(xtrain, ytrain) 63 # 预测当测试x为2018时销售额 yhat 64 yhat = lm.predict(np.array([2018]).reshape(-1, 1)) 65 ytest.append(round(yhat[0][0], 2)) 66 # 给预测结果赋值对应的列名 67 newrow = pd.DataFrame([dict(zip(df.columns, ytest))]) 68 # 预测结果行加在数据前 69 df = newrow.append(df) 70 momth_data(df,month) 71 72 df.reset_index(drop=True,inplace=True) 73 df = df[df['时间'].dt.year != 2015] 74 df['colsums'] = df.sum(1) #取值第一列。交易金额总和列 :灭鼠杀虫剂 2.469394e+09 75 76 df.insert(1,'year',df['时间'].dt.year) #年份列
图表分析
近三年的市场趋势
1 byyear = df.groupby('year').sum().reset_index() 2 sns.relplot('year','colsums',kind='line',marker='o',data=byyear,height=4) 3 plt.title('近三年的市场趋势') 4 plt.xticks(byyear.year,rotation=45) 5 plt.xlabel('年份') 6 plt.ylabel('总交易额') 7 plt.show()

近三年各类市场销售趋势
1 f,ax = plt.subplots(figsize=(10,6)) 2 #dashes=False 不区分线型 3 sns.lineplot(data=byyear.set_index('year').iloc[:,:-1],dashes=False,marker='^') 4 plt.title('近三年各类市场销售趋势') 5 plt.xticks(byyear.year,rotation=45) 6 #在指定位置加文本 7 for a,b in zip(byyear.year,byyear['灭鼠杀虫剂']): 8 plt.text(a,b,'%.3e'% b, ha='center',va='bottom',size=12) 9 10 plt.xlabel('年份') 11 plt.ylabel('总交易额') 12 plt.show()

灭鼠杀虫剂近三年的增长趋势
1 g = sns.FacetGrid(byyear,height=5) 2 g.map(sns.barplot,'year','灭鼠杀虫剂',color='wheat') 3 g.map(sns.pointplot,'year','灭鼠杀虫剂') 4 5 for a,b in zip(range(len(byyear)),byyear['灭鼠杀虫剂']): 6 plt.text(a,b,'%.3e'% b, ha='center',va='bottom',size=12) 7 8 plt.xlabel('年份') 9 plt.ylabel('灭鼠杀虫剂近三年的增长趋势') 10 plt.xticks(rotation=45) 11 plt.show()

计算每年每个子市场的比例
1 byyear_per = byyear.iloc[:,1:-1].div(byyear.colsums,axis=0) 2 byyear_per.index = byyear.year 3 byyear_per 4 #stacked=True 5 byyear_per.plot(kind='bar',stacked=True,figsize=(10,8),colormap='tab10') 6 7 for a,b in zip(range(len(byyear_per)),byyear_per['灭鼠杀虫剂']): 8 plt.text(a,b/2,f'{b*100:.2f}%', ha='center',va='bottom',size=12,color='white') 9 10 11 plt.xlabel('年份') 12 plt.ylabel('总交易额占比') 13 plt.title('近三年各子类市场销量占比') 14 plt.show()

近三年各子类市场销量年增幅
1 #拿到中间7列 2 byyear0 = byyear.iloc[:,1:-1] 3 byyear0.diff()#一阶差分 17-16 18-17 4 5 #计算年增幅 6 byyear0 = byyear.iloc[:,1:-1] 7 byyear_diff = byyear0.diff().iloc[1:,:].reset_index(drop=True)/byyear0.iloc[:2,:] 8 byyear_diff.index = ['16-17','17-18'] 9 byyear_diff 10 11 #作图查看 12 f,ax = plt.subplots(figsize=(10,8)) 13 sns.lineplot(data=byyear_diff,dashes=False) 14 plt.title('近三年各子类市场销量年增幅') 15 16 plt.xlabel('年份') 17 plt.ylabel('总交易额年增幅') 18 plt.show()

交易指数占比
df1 = pd.read_excel('top100品牌数据.xlsx') df1.isna().mean() df1['交易指数占比'] = df1['交易指数']/df1['交易指数'].sum() df1.plot(x='品牌',y='交易指数占比',kind='bar',figsize=(15,5)) plt.show()

# HHI 市场集中度,俗称垄断程度,市场占有率 HHI = sum(df1['交易指数占比']**2) print(HHI) #0.013546334007208914
合并所有文件
1 ilename1 = glob.glob('*.xlsx') 2 dfs1 = [pd.read_excel(i) for i in filename1] 3 df2 = pd.concat(dfs1,sort=False)
删除缺失值大于56%的列
1 df2 = pd.read_excel(r"C:\Users\Administrator\Documents\WeChat Files\wxid_bexgq4nmz5cs22\FileStorage\File\2021-12\安全图书(1)(1)(1).xlsx",sheet_name="Sheet1") 2 ind1 = df2.isna().mean()> 0.56 # 列的缺失值的平均数大于56% 3 df20 = df2.loc[:,~ind1] # 重新赋值
ind2 = np.array([len(df20[i].unique()) == 1 for i in df20.columns]) df21 = df20.loc[:,~ind2]
列索引
ind3 = df21.columns.get_loc('出版社') #列索引 df22 = df21.iloc[:,:ind3]
删除
1 df21 = pd.read_excel(r"C:\Users\Administrator\Documents\WeChat Files\wxid_bexgq4nmz5cs22\FileStorage\File\2021-12\安全图书(1)(1)(1).xlsx",sheet_name="Sheet1") 2 df21.drop(columns="书名") 3 df21.drop(index=0)
转类型
1 df23 = df23.astype({'宝贝ID':'object'}) #将宝贝ID转成object 2 df23.reset_index(drop=True,inplace=True)
画图技巧
byclass.plot.barh()
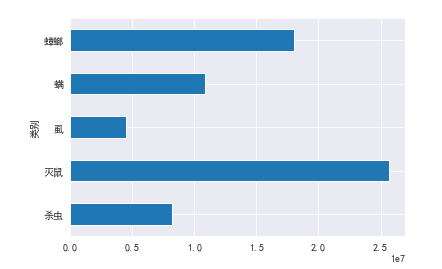
byclass.plot.pie(autopct='%.2f')

df24['售价'].plot.hist()

1 df25 = df24[df24['价格区间']=='0_50'] 2 df25['售价'].plot.hist()

交互饼形图
import plotly.graph_objects as go #交互图形 类似于PowerBI fig = go.Figure(data=[go.Pie(labels=byclass.index,values=byclass.values)]) fig.show()
同时画三个饼图
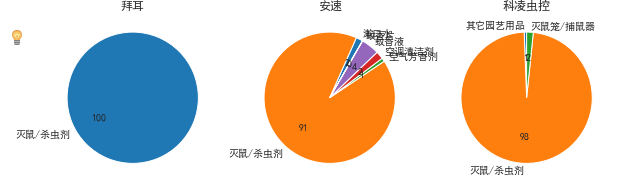
1 #饼图 [0,1,2],bai31、an31、kl31都是Dateframe 数据 2 fig,axes = plt.subplots(1,3,figsize=(10,6)) 3 ax = axes[0] #第一个拜耳 4 bai31['销售额'].plot.pie(autopct='%.f',title='拜耳',startangle=30,ax=ax) 5 ax.set_ylabel('') 6 ax = axes[1] #第二个安速 7 an31['30天销售额'].plot.pie(autopct='%.f',title='安速',startangle=60,ax=ax) 8 ax.set_ylabel('') 9 ax = axes[2] #第三个科凌虫控 10 kl31['30天销售额'].plot.pie(autopct='%.f',title='科凌虫控',startangle=90,ax=ax) 11 ax.set_ylabel('')
分箱操作
data = pd.read_excel(r"C:\Users\Administrator\Desktop\安全图书.xlsx") print(data["价格"]) #自定义分箱 bins = [0,40,80,120] #分界线 labels = ['0_40','40_80','80_120']#箱子的标题 # #pd.cut include_lowest (0,50] ---> [0,50] 左右都是闭区间 data['价格区间'] = pd.cut(data['价格'],bins,labels=labels,include_lowest=True) print(data['价格区间'].value_counts())
结果:
0_40 11
40_80 3
80_120 2
Name: 价格区间, dtype: int64
相对竞争度
1 byc['相对竞争度'] = 1- (byc['单宝贝平均销售额']-byc['单宝贝平均销售额'].min())/( 2 byc['单宝贝平均销售额'].max()-byc['单宝贝平均销售额'].min())
前5%的价格
1 bytype1 = df21[df21['价格']>=df21['价格'].quantile(0.95)]
取排名前十
top10 = df0.sort_values('交易指数',ascending=False).reset_index(drop=True).iloc[:10,:]
value_counts().count() 总数
df['书名'].value_counts().count()
loc[:, '价格']与 loc[:, ['价格']的区别
loc[:, '价格'] 结果:

loc[:,['价格']]结果:

mask 替换,deacrib方法
1 df = pd.read_excel(r"C:\Users\Administrator\Documents\WeChat Files\wxid_bexgq4nmz5cs22\FileStorage\File\2021-12\安全图书(1)(1)(1).xlsx",sheet_name="Sheet1") 2 c = df.describe(percentiles=[0.1,0.9,0.99]) 3 def block(x): 4 qu = x.quantile(.9) 5 out = x.mask(x>qu,qu) #当大于90%分位数的进行替换 6 return(out) 7 8 def block2(df): 9 df1 = df.copy() 10 df1['价格'] = block(df1['价格']) #使用盖帽法进行替换交易增长幅度 11 return df1 12 df3 = block2(df) 13 print(df3.describe(percentiles=[0.1,0.9,0.99]))
结果:

