
深度学习--项目提炼1
一、步骤
1、处理数据:避免原数据被感染,将原数据copy,标记缺失值,用热力图,去掉多余的字段
2、清洗数据:copy处理的数据,然后进行删除字段和删除重复的字段
3、划分测试、训练集:copy 测试集和训练集,再给缺失的值里面填充中位数、众数
处理数据
1 #求补集(对应索引不一致的数据) 2 ls = ["tom","name",3] 3 ls2 = [7,"name2",3] 4 print(np.setxor1d(ls,ls2)) #['7' 'name' 'name2' 'tom'] 5 6 7 # 把a转化成b 8 a = ['NY8Y9', 'N2N29', 'N3N39', 'N4N49', 'N5N59', 'N6N64'] 9 b = ['N1819', 'N2029','N3039','N4049', 'N5059','N6064'] 10 dic = dict(zip(a,b)) 11 def tran(x): 12 if x in dic: 13 return dic[x] 14 else: 15 return x 16 data_01.columns = data_01.columns.map(tran)
1 # 把英文列转成中文列 2 dic = {k:v for k,v in feature_dict[['变量名','变量说明']].values} #{"英文":"中文"} 3 def chinese(x): 4 y = x.copy() 5 #将输入进来的字段名通过字典映射的方式去对应 6 y.columns = pd.Series(y.columns).map(dic) 7 return y 8 #得到列表 9 feature_dict.变量名[:5].tolist() 10 11 #将0_4列取出来并进行翻译 12 data0_4 = chinese(data_01[feature_dict.变量名[:5].tolist()]) 13 data0_4.head()
1 # 检测字段是否有空值 2 def fre(x): 3 for i in x.columns: 4 print("字段名:",i) 5 print("----------") 6 print("字段数据类型:",x[i].dtype) 7 print("----------------------------") 8 print(x[i].value_counts()) #出现的频数 9 print("----------------------------") 10 print("缺失值的个数:",x[i].isnull().sum()) 11 print("------------------------------------------------\n\n")
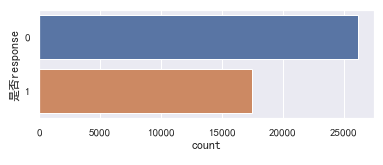
1 # 条形图 2 import seaborn as sns 3 4 #中文编码 5 sns.set_style("darkgrid",{"font.sans-serif":['simhei','Droid Sans Fallback']}) 6 #sns.set() 7 plt.figure(1,figsize=(6,2)) 8 sns.countplot(y='是否response',data=data0_4) 9 plt.show()
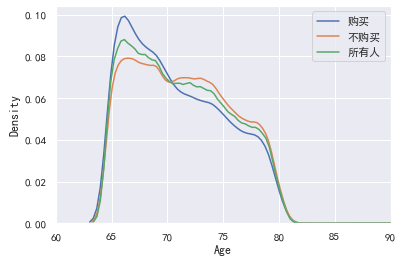
1 #根据年龄 概率密度图 2 sns.kdeplot(data0_4.年龄[data0_4.是否response==1],label='购买') 3 sns.kdeplot(data0_4.年龄[data0_4.是否response==0],label='不购买') 4 sns.kdeplot(data0_4.年龄.dropna(),label='所有人') 5 6 plt.xlim([60,90]) 7 plt.xlabel('Age') 8 plt.ylabel('Density')
1 #0 1 转码 2 def zero_one(x): 3 for i in x.columns: 4 if x[i].dtype == 'object': 5 dic = dict(zip(list(x[i].value_counts().index),range(x[i].nunique()))) 6 x[i] = x[i].map(dic) 7 return x 8 x[i].value_counts()# Y:20,N:10 9 x[i].value_counts().index# 0,1 10 x[i].nunique()# 不重复的值 N,Y 11 12 zero_one(data23_35).corr() #相关系数
# 转码 方法二
from sklearn.preprocessing import OrdinalEncoder
#fit_transform 直接转
new_arr = OrdinalEncoder().fit_transform(Xtrain_02)
import matplotlib.pyplot as plt
import seaborn as sns
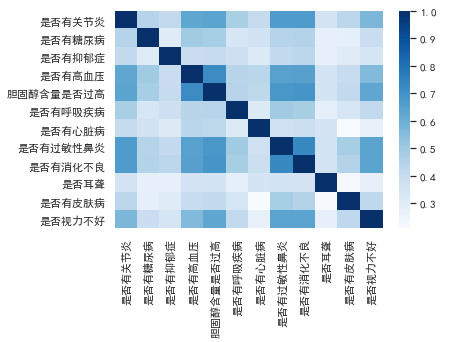
#画一个热力图
sns.heatmap(zero_one(data23_35).corr(),cmap='Blues')
#形式2
a = chinese(data_01[["c210apvt","c210blu","c210bpvt","c210mob","c210wht","zhip19"]])
sns.heatmap(a.corr(),cmap='Blues')
1 # 相关系数高的列 2 def higt_cor(x,y=0.65): 3 data_cor = (x.corr()>y) 4 a=[] 5 6 for i in data_cor.columns: 7 if data_cor[i].sum()>=2: 8 a.append(i) 9 10 return a #这些是我们要考虑删除的
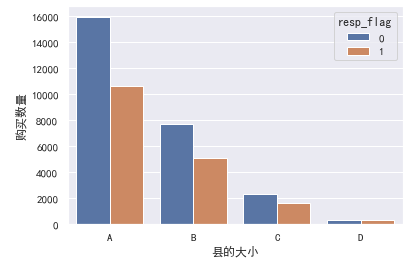
1 # 图 2 sns.countplot(x='N2NCY',hue='resp_flag',data=data_01) 3 plt.xlabel('县的大小') 4 plt.ylabel('购买数量')
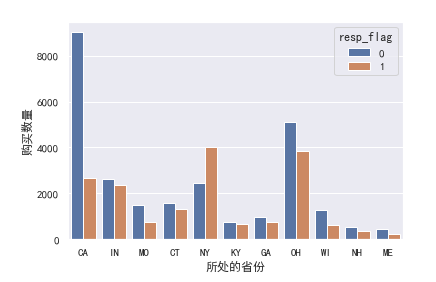
1 # 图 2 sns.countplot(x='STATE_NAME',hue='resp_flag',data=data_01) 3 plt.xlabel('所处的省份') 4 plt.ylabel('购买数量')
# 删除 del_col = ["KBM_INDV_ID","U18","POEP","AART","AHCH","AASN","COLLEGE", "INVE","c210cip","c210hmi","c210hva","c210kses","c210blu","c210bpvt","c210poo","KBM_INDV_ID","meda"] data_02 = data_02.drop(columns=del_col)
1 # 删除重复值 2 data_02.drop_duplicates().shape
划分训练集与测试集
一定要先划分数据集再填充、转码
1 from sklearn.model_selection import train_test_split 2 3 y = data_02.pop('resp_flag') #标签 4 X = data_02 #特征 5 Xtrain,Xtest,Ytrain,Ytest = train_test_split(X,y,test_size=0.3,random_state=100) 6 Xtrain_01=Xtrain.copy() 7 Xtest_01=Xtest.copy() 8 Ytrain_01=Ytrain.copy() 9 Ytest_01=Ytest.copy() 10 fil = ["age","c210mah","c210b200","c210psu","c210wht","ilor"] 11 Xtrain_01[fil].median() 12 dic = dict(zip(Xtrain_01[fil].median().index,Xtrain_01[fil].median())) 13 #向训练集填充中位数 14 Xtrain_01 = Xtrain_01.fillna(dic) 15 #向训练集填充众数 16 mod = ["N1819","ASKN","MOBPLUS","N2NCY","LIVEWELL","HOMSTAT","HINSUB"] 17 dic_mod = dict(zip(Xtrain_01[mod].mode().columns,Xtrain_01[mod].iloc[0,:])) 18 Xtrain_01 = Xtrain_01.fillna(dic_mod) 19 # 替换填充 20 Xtrain_01['N6064'] = Xtrain_01['N6064'].replace('0','N') #0 替换成 N 21 # 检验每个字段(列)是否有空值 22 Xtrain_01.isnull().sum()[Xtrain_01.isnull().sum()!=0]
转码
1 # 筛出object列 2 # 方法一 3 for i in data_01.columns: 4 if data_01[i].dtype == 'object': 5 print(i) 6 7 # 方法二 8 object_tr =data_01.describe(include='O').columns #include= “O“ 是object类型
1 encod_col = pd.read_excel('保险案例数据字典_清洗.xlsx',sheet_name=2) 2 encod_col.head()
1 # 查看Xtrain_01中object类型 2 object_tr =Xtrain_01.describe(include='O').columns
1 #检查一下转码的目标是否出现 2 np.setdiff1d(object_tr,encod_col['变量名']) # 将所有obj类型的列筛选出来,看看在不在需要转码的列(encod_col)里
0-1 转码总结
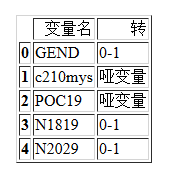
1 #获取需要转码的字段 2 encod_col = pd.read_excel('保险案例数据字典_清洗.xlsx',sheet_name=2) 3 4 # 查看Xtest_01中object类型 5 object_tr =Xtest_01.describe(include='O').columns 6 7 #检查一下转码的目标是否出现 8 np.setdiff1d(object_tr,encod_col['变量名']) 9 10 #0-1 转码 11 # 获取0-1 转码的变量名 12 z_0_list = encod_col[encod_col['转']=='0-1'].变量名 # 要转码的列 13 14 Xtest_02 = Xtest_01[z_0_list] 15 16 #sklearn的预处理模块 17 from sklearn.preprocessing import OrdinalEncoder 18 19 #fit_transform 直接转 20 new_arr = OrdinalEncoder().fit_transform(Xtest_02) 21 # columns 设置表头为原来的 index 索引也是原来 22 Xtest_02 = pd.DataFrame(data=new_arr,columns=Xtest_02.columns,index=Xtest_02.index) 23 24 Xtest_01[z_0_list] = Xtest_02 25 26 Xtest_01.head()
哑变量 总结
1 #获取哑变量转码的变量 2 o_h_list = encod_col[encod_col['转']=='哑变量'].变量名 3 4 o_h_01 = ['c210mys','LIVEWELL'] #非字符型的变量 5 o_h_02 = [i for i in o_h_list if i not in o_h_01] #字符类型的变量 6 7 #先转o_h_02 字符类型 8 Xtest_02 = Xtest_01.copy() 9 Xtest_02 = pd.get_dummies(chinese(Xtest_02[o_h_02])) 10 11 #w我们再转 o_h_01 非字符 12 Xtest_03 = Xtest_01.copy() 13 #转成字符类型 14 Xtest_03 = Xtest_03[o_h_01].astype(str) 15 #转化覆盖 16 Xtest_03 = pd.get_dummies(chinese(Xtest_03[o_h_01])) 17 18 19 # Xtrain_04 删除原转码的字段 20 Xtest_04 = Xtest_01.copy() 21 Xtest_04 = chinese(Xtest_04.drop(columns=o_h_01+o_h_02)) 22 23 24 #将 Xtest_04 Xtest_02 Xtest_03 合并 25 Xtest_05 = pd.concat([Xtest_04,Xtest_02,Xtest_03],axis=1) 26 Xtest_05.shape
初步建模
1 from sklearn.tree import DecisionTreeClassifier 2 from sklearn.model_selection import cross_val_score 3 4 clf = DecisionTreeClassifier(random_state=420,class_weight='balanced') 5 cvs = cross_val_score(clf,Xtrain_05,Ytrain) 6 cvs.mean() # 平均分 0.5993914576104883
网格搜索找最优参数
1 from sklearn.model_selection import GridSearchCV 2 3 #测试参数 4 param_test = { 5 'splitter':('best','random'), 6 'criterion':('gini','entropy'), #基尼 信息熵 7 'max_depth':range(3,15) #最大深度 8 #,min_samples_leaf:(1,50,5) 9 } 10 11 gsearch= GridSearchCV(estimator=clf, #对应模型 12 param_grid=param_test,#要找最优的参数 13 scoring='roc_auc',#准确度评估标准 14 n_jobs=-1,# 并行数 个数 -1:跟CPU核数一致 15 cv = 5,#交叉验证 5折 16 iid=False,# 默认是True 与各个样本的分布一致 17 verbose=2#输出训练过程 18 ) 19 20 gsearch.fit(Xtrain_05,Ytrain_01) 21 #优化期间观察到的最高评分 22 gsearch.best_score_ 23 #0.691856415170639
# 最优参数
gsearch.best_params_
#{'criterion': 'entropy', 'max_depth': 6, 'splitter': 'best'}
模型评估
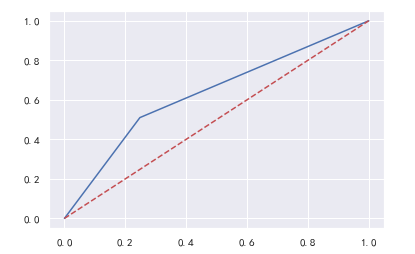
1 from sklearn.metrics import accuracy_score #准确率 2 from sklearn.metrics import precision_score #精准率 3 from sklearn.metrics import recall_score #召回率 4 from sklearn.metrics import roc_curve 5 6 y_pre = gsearch.predict(Xtest_05) 7 accuracy_score(y_pre,Ytest) 8 #0.6090076335877863 9 10 precision_score(y_pre,Ytest) 11 #0.748152359295054 12 13 recall_score(y_pre,Ytest 14 #0.5100116264048572 15 16 fpr,tpr,thresholds = roc_curve(y_pre,Ytest) #roc参数 17 import matplotlib.pyplot as plt 18 plt.plot(fpr,tpr,c='b',label='roc曲线') 19 plt.plot(fpr,fpr,c='r',ls='--')
输出规则
1 #最优参数 2 #{'criterion': 'entropy', 'max_depth': 6, 'splitter': 'best'} 3 from sklearn.tree import DecisionTreeClassifier 4 from sklearn import tree 5 6 import graphviz 7 8 #将最优参数放到分类器 9 clf = DecisionTreeClassifier(criterion='entropy',max_depth=6,splitter='best') 10 clf = clf.fit(Xtrain_05,Ytrain) 11 12 13 features = Xtrain_05.columns 14 dot_data = tree.export_graphviz(clf, 15 feature_names=features, 16 class_names=['Not Buy','Buy'], 17 filled=True, 18 rounded=True, 19 leaves_parallel=False) 20 21 graph= graphviz.Source(dot_data)

