
机器学习--数据挖掘算法(无监督)
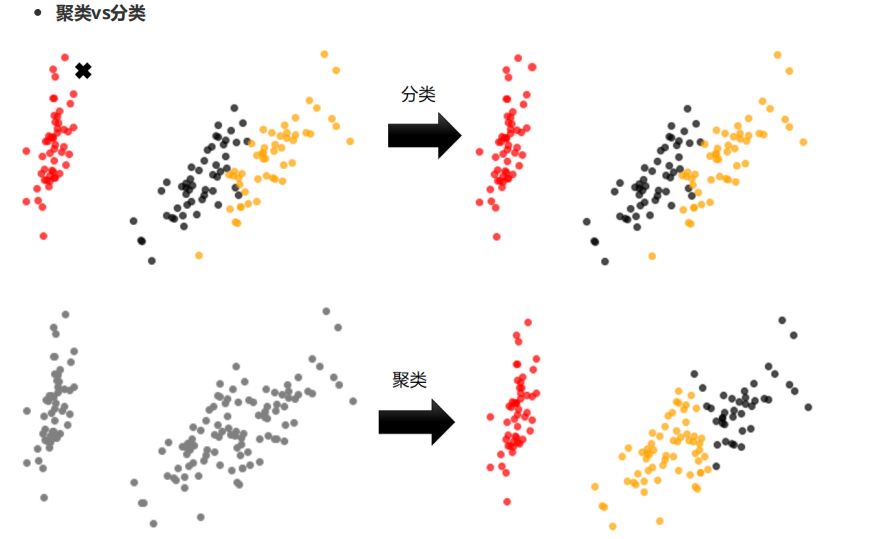
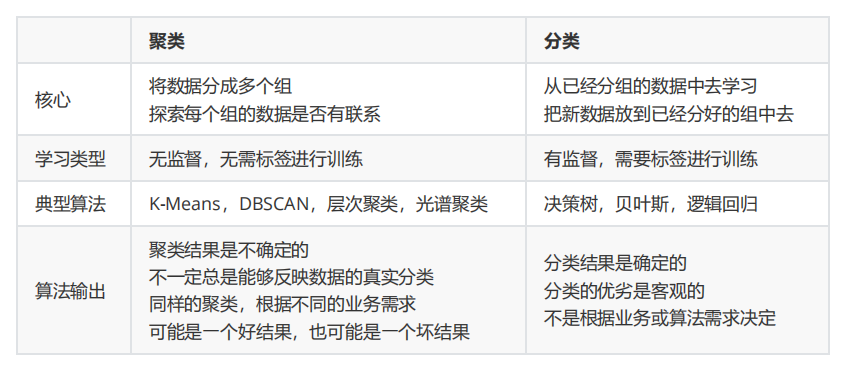
一、有监督学习和无监督学习区别
分类:有监督
聚类:无监督
二、kmeans 算法
#自己创建数据集
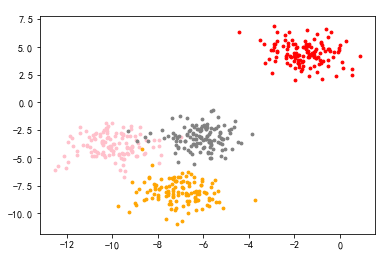
1 X, y = make_blobs(n_samples=500,n_features=2,centers=4,random_state=1) 2 plt.scatter(X[:, 0], X[:, 1], marker='o' ,s=8 ) 3 color = ["red","pink","orange","gray"] 4 for i in range(4): 5 plt.scatter(X[y==i, 0], X[y==i, 1] 6 ,marker='o' #点的形状 7 ,s=8 #点的大小 8 ,c=color[i] 9 ) 10 plt.show()
1 n_clusters = 3 #簇 2 cluster = KMeans(n_clusters=n_clusters, random_state=0).fit(X) 3 # 方法一 4 y_pred = cluster.labels_# 预测归纳成3类,分别是0,1,2 5 # 方法二 6 cluster.predict(X)# 预测归纳成3类,分别是0,1,2 7 # 查看质心 8 centroid = cluster.cluster_centers_ 9 # 重要属性inertia_,查看总距离平方和 10 inertia = cluster.inertia_
模型评估--轮廓系数
# 簇越大,总距离平方和越小,总距离平方和越小越好,但是簇越大意味着分类越多,
# 有的类具有高度相似,分出来无意义,要遵循簇内差异小,簇外差异大,需要用轮廓系数,找到最优簇
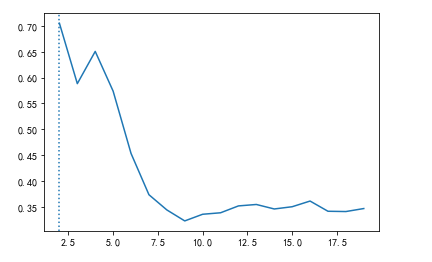
找最优簇
1 from sklearn.metrics import silhouette_score 2 from sklearn.metrics import silhouette_samples 3 silhouette_score(X,cluster.labels_) # X是源数据,cluster.labels_是分的类,计算所有样本的轮廓系数均值0.5882004012129721 4 silhouette_samples(X,cluster.labels_) #计算每个样本的轮廓系数。 5 # 通过画图,找到最优簇 6 import pandas as pd 7 score = [] 8 # 将k(簇)值从2变化到20 9 for i in range(2, 20): 10 cluster = KMeans(n_clusters=i, random_state=0).fit(X) 11 score.append(silhouette_score(X, cluster.labels_)) 12 13 plt.plot(range(2, 20), score) 14 # 给k最大的位置加虚线 #idxmax()[] 取最高的分数索引 因为这边从k=2开始 所以+2 15 plt.axvline(pd.DataFrame(score).idxmax()[0] + 2, ls=':') 16 # 最优簇 17 cu = pd.DataFrame(score).idxmax()[0] + 2 #2 18 print(pd.DataFrame(score))
三、无监督的归一化
from sklearn.preprocessing import Normalizer X = data.iloc[:,2:] norm_train_data = Normalizer().fit_transform(X)
四、关于标准化、归一化、Normalizer的总结
一、数据标准化
StandardScaler (基于特征矩阵的列,将属性值转换至服从正态分布)
标准化是依照特征矩阵的列处理数据,其通过求z-score的方法,将样本的特征值转换到同一量纲下
常用与基于正态分布的算法,比如回归
二、数据归一化
MinMaxScaler (区间缩放,基于最大最小值,将数据转换到0,1区间上的)
提升模型收敛速度,提升模型精度
常见用于神经网络
三、Normalizer (基于矩阵的行,将样本向量转换为单位向量)
其目的在于样本向量在点乘运算或其他核函数计算相似性时,拥有统一的标准
常见用于文本分类和聚类、logistic回归中也会使用,有效防止过拟合

