
机器学习--数据挖掘算法(有监督)
一、knn 算法
1 import numpy as np 2 import pandas as pd 3 import matplotlib.pyplot as plt 4 from math import sqrt 5 6 plt.rcParams['font.sans-serif'] = ['Simhei'] 7 8 rowdata = {'颜色深度':[14.13,13.2,13.16,14.27,13.24,12.07,12.43,11.79,12.37,12.04], 9 '酒精浓度': [5.64,4.28,5.68,4.80,4.22,2.76,3.94,3.1,2.12,2.6], 10 '品种': [0,0,0,0,0,1,1,1,1,1] 11 } 12 13 data = pd.DataFrame(rowdata) 14 15 x = data.iloc[:,1:3].values # 取出颜色深度、酒精浓度 16 new_data = np.array([12.3,4.1]) # 判断这个数值属于什么品种 17 18 # 应用knn 数学公式 19 a = ((new_data-x)**2)[:,0]# 取出颜色深度 20 b = ((new_data-x)**2)[:,1]# 取出酒精浓度 21 22 res = np.sqrt(a+b) 23 sy = np.argsort(res)[:3] # 最大的三个值的索引 24 y = data.iloc[:,:1].values# 品种 25 # print(sy) 26 # print(y) 27 28 cc = pd.Series([y[i] for i in sy]).value_counts().index[0] # 出现次数最多的品种 29 # print(cc) 30 31 # 可视化 32 x = data.iloc[:,1:3] # 特征 33 y = data.iloc[:,0] # 标签 34 plt.scatter(x[y==1,0],x[y==1,1],color='red',label='赤珠霞') #x[y==1,0] 意思是y==1代表行,0代表列 35 plt.scatter(x[y==0,0],x[y==0,1],color='purple',label='黑皮诺') 36 plt.scatter(new_data[0],new_data[1],color='yellow',label='判断的数据') 37 plt.legend() 38 plt.show()
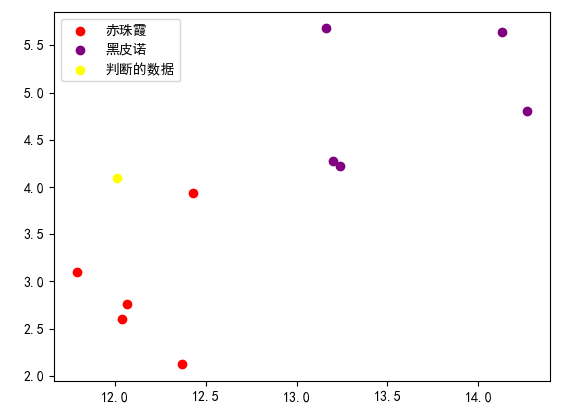
二、sklearn
1 from sklearn.neighbors import KNeighborsClassifier 2 import pandas as pd 3 import numpy as np 4 5 6 rowdata = {'颜色深度':[14.13,13.2,13.16,14.27,13.24,12.07,12.43,11.79,12.37,12.04], 7 '酒精浓度': [5.64,4.28,5.68,4.80,4.22,2.76,3.94,3.1,2.12,2.6], 8 '品种': [0,0,0,0,0,1,1,1,1,1] 9 } 10 11 data = pd.DataFrame(rowdata) 12 obj = KNeighborsClassifier(n_neighbors=3) 13 obj = obj.fit(data.iloc[:,1:3],data.iloc[:,0])# 训练模型 14 res = obj.predict([[12.01,4.1]]) #预测结果 15 # print(res) 16 17 # 预测多个 18 a = np.random.normal(11,2,(10,1)) 19 b = np.random.normal(5,2,(10,1)) 20 neaw_data = np.concatenate([a,b],axis=1) 21 # print(neaw_data) 22 res1 = obj.predict(neaw_data) 23 print(res1) ##[1 0 0 0 1 1 0 1 1 1] 24 25 # 对模型进行一个评估,接口score返回预测的准确率 26 score = obj.score([[12.01,4.1]],[0]) 27 print(score) 28 29 # 检验模型的准确率 30 s_new =[0, 1, 1, 0, 1, 0, 1, 0, 0, 0] #实际的结果 31 y_new =neaw_data#预测的结果 32 33 score2 = obj.score(y_new,np.array(s_new)) 34 print(score2) # 准确率 35 36 # 左侧一列标签为0的概率,右边一列是标签为0的概率 37 yu = obj.predict_proba(neaw_data) 38 print(yu)
三、划分训练集、测试集
1 from sklearn.neighbors import KNeighborsClassifier 2 import pandas as pd 3 import numpy as np 4 from sklearn.neighbors import KNeighborsClassifier 5 from sklearn.datasets import load_breast_cancer 6 from sklearn.model_selection import train_test_split 7 import matplotlib.pyplot as plt 8 from sklearn.model_selection import cross_val_score as CVS 9 10 rowdata = {'颜色深度':[14.13,13.2,13.16,14.27,13.24,12.07,12.43,11.79,12.37,12.04], 11 '酒精浓度': [5.64,4.28,5.68,4.80,4.22,2.76,3.94,3.1,2.12,2.6], 12 '品种': [0,0,0,0,0,1,1,1,1,1] 13 } 14 data = pd.DataFrame(rowdata) 15 tezheng = data.loc[:,['颜色深度','酒精浓度']] 16 jieguo = data.loc[:,'品种'] 17 # 测试集 18 # 划分训练集(xtrain、ytrain)测试集(xtest、ytest) 19 xtrain,xtest,ytrain,ytest = train_test_split(tezheng,jieguo,test_size=0.2,random_state=234) # 随机种子 20 # 建模 21 clf = KNeighborsClassifier(n_neighbors=5) # 默认为5 22 xunlainji = clf.fit(xtrain,ytrain) 23 score_result = xunlainji.score(xtest,ytest) 24 print(score_result) 25 26 # 寻找最优K 27 scores = [] 28 k = range(1,9) 29 for i in k: 30 clf = KNeighborsClassifier(n_neighbors=i) 31 clf = clf.fit(xtrain,ytrain) 32 scores.append(clf.score(xtest,ytest)) 33 plt.plot(k,scores) 34 plt.show()
四、交叉验证,目的寻找稳定的K

原理

1 # 划分数据集和测试集 2 xtrain,xtest,ytrain,ytest=train_test_split(tezheng,jieguo,test_size=0.2,random_state=100) 3 # 建模 4 mean = [] 5 var = [] 6 for i in range(1,7): 7 KNN = KNeighborsClassifier(n_neighbors=i) 8 # 交叉验证 9 result = CVS(KNN,xtrain,ytrain,cv=5) # 5或者6次变化 10 mean.append(result.mean()) # 平均値 11 var.append(result.var()) # 方差 12 # 画图 13 mean = np.array(mean) 14 var = np.array(var) 15 plt.plot(range(1,7),mean,color='k') 16 plt.plot(range(1,7),var,color='r',linestyle='--') 17 plt.show() 18 # 由图可见,黑色线与红色线间隔越小,K值越优 19 clf = KNeighborsClassifier(n_neighbors=5) 20 xunlainji2 = clf.fit(xtrain,ytrain) 21 score_result2 = xunlainji2.score(xtest,ytest) 22 print(score_result2)

五、归一化,针对特征值过大,过小
归一化公式:

Python:
1 data = [[-1,2],[-0.5,6],[0,10],[1,18]] 2 data=pd.DataFrame(data) 3 gui_one = (data-np.min(data,axis=0))/(np.max(data,axis=0)-np.min(data,axis=0)) 4 print(gui_one)
sklearn
2 xtrain = mms().fit(xtrain).transform(xtrain) 3 ytrain = mms().fit(ytrain).transform(ytrain)
六、距离惩罚
根据每个最近邻x=距离的不同对其做加权,加权方法设置权重,该权重的计算公式为:

遵循一点一票规则
KNeighborsClassifier(n_neighbors=i,weights='distance')
决策树
1 import pandas as pd 2 import numpy as np 3 from sklearn.neighbors import KNeighborsClassifier 4 5 row_data = {'是否陪伴' :[0,0,0,1,1], 6 '是否玩游戏':[1,1,0,1,1], 7 '渣男' :['是','是','不是','不是','不是']} 8 data = pd.DataFrame(row_data) 9 # 计算熵,熵越大,信息越不纯 10 def calEnt(dataSet): 11 n = dataSet.shape[0] # 数据集总行数 12 iset = dataSet.iloc[:,-1].value_counts() # 标签的所有类别 13 p = iset/n # 每一类标签所占比 14 ent = (-p*np.log2(p)).sum() # 计算信息熵 15 return ent 16 17 print(calEnt(data)) # 0.9709505944546686
# 熵越高,信息的不纯度就越高,则混合的数据就越多。
# 也就是说,单从判断的结果来看,如果你从这 5 人中瞎猜,要准确判断其中一个人是不是“bad boy”,是不容易的。
计算每一列的熵
# 计算每一列的熵 # 定义信息熵 def calEnt(dataSet): n = dataSet.shape[0] # 数据集总行数 iset = dataSet.iloc[:,-1].value_counts() # 统计标签的所有类别 p = iset/n # 统计每一类标签所占比 ent = (-p*np.log2(p)).sum() # 计算信息熵 return ent # 选择最优的列进行切分 def bestSplit(dataSet): baseEnt = calEnt(dataSet) # 计算原始熵 bestGain = 0 # 初始化信息增益 axis = -1 # 初始化最佳切分列,标 签列 for i in range(dataSet.shape[1]-1): # 对特征的每一列进行循 环 levels= dataSet.iloc[:,i].value_counts().index # 提取出当前列的所有取 值 ents = 0 # 初始化子节点的信息熵 for j in levels: # 对当前列的每一个取值 进行循环 childSet = dataSet[dataSet.iloc[:,i]==j] # 某一个子节点的 dataframe ent = calEnt(childSet) # 计算某一个子节点的信息熵 ents += (childSet.shape[0]/dataSet.shape[0])*ent # 计算当前列的信息熵 print('第{}列的信息熵为{}'.format(i,ents)) infoGain = baseEnt-ents # 计算当前列的信息增益 print('第{}列的信息增益为{}\n'.format(i,infoGain)) if (infoGain > bestGain): bestGain = infoGain # 选择最大信息增益 axis = i # 最大信息增益所在列的 索引 print("第{}列为最优切分列".format(axis)) return axis print(bestSplit(data)) """ 结果: 第0列的信息熵为0.8 第0列的信息增益为0.17095059445466854 第1列的信息熵为0.5509775004326937 第1列的信息增益为0.4199730940219749 """ """ 函数功能:按照给定的列划分数据集 参数说明: dataSet:原始数据集 axis:指定的列索引 value:指定的属性值 return:redataSet:按照指定列索引和属性值切分后的数据集 """ # 为下一步的分割做决定 def mySplit(dataSet,axis,value): col = dataSet.columns[axis] redataSet = dataSet.loc[dataSet[col]==value,:].drop(col,axis=1) return redataSet #验证函数:以axis=0,value=1为例,value是指列中为1的 mySplit(data,1,1)
使用SK-LEARN实现决策树
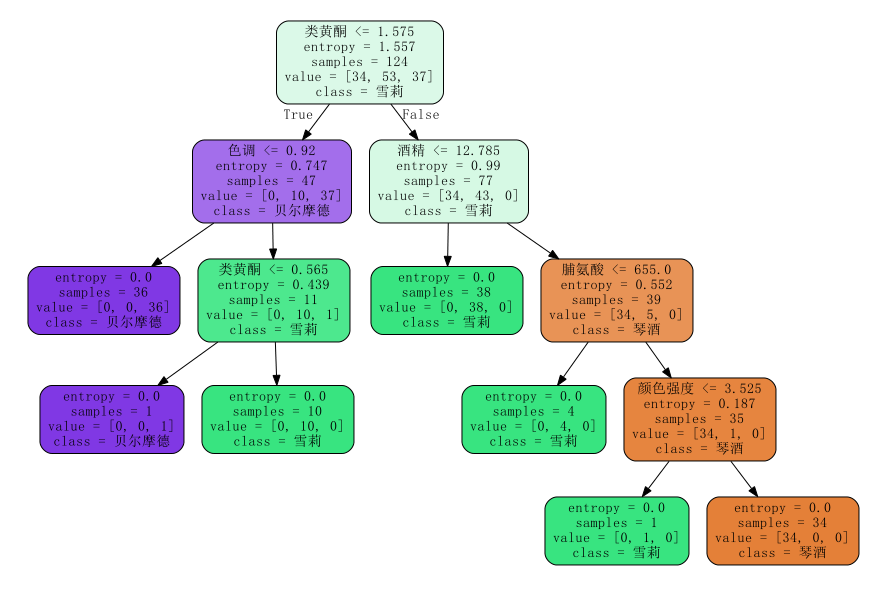
import pandas as pd import numpy as np from sklearn import tree from sklearn.model_selection import train_test_split from sklearn.datasets import load_wine from sklearn.tree import DecisionTreeClassifier import graphviz # 画决策树的包,同时要安装exe文件,配置环境变量 wine = load_wine() hangs = wine.data.shape #(178, 13) # print(wine.target ) #标签y # print(wine.feature_names) # print(wine.target_names) #合成数据 data =np.concatenate((wine.data,wine.target.reshape(-1,1)),axis=1) names = ['酒精','苹果酸','灰','灰的碱性','镁','总酚','类黄酮','非黄烷类酚类','花青素','颜色强度','色调','od280/od315 稀释葡萄酒','脯氨酸','标签'] #合成dataframe wine_df = pd.DataFrame(data=data,columns=names) # print(wine_df) # 建模 # 划分训练集和测试集 Xtrain,Xtest,Ytrain,Ytest = train_test_split(wine_df.iloc[:,:-1], wine_df.iloc[:,-1], test_size=0.3, random_state=420) # Xtrain.shape (124, 13) 测试集取了30%,测试训练集取70%,178*0.7=124 # 生成决策树 clf = DecisionTreeClassifier(criterion='entropy') #生成决策树分类器 entropy、gini clf = clf.fit(Xtrain,Ytrain) score_result = clf.score(Xtest,Ytest) #得到准确率 0.9629629 print(score_result) # 生成决策树的pdf feature_names = ['酒精','苹果酸','灰','灰的碱性','镁','总酚','类黄酮','非黄烷类酚类','花青素','颜色强度','色调','od280/od315 稀释葡萄酒','脯氨酸'] dot_data = tree.export_graphviz(clf ,feature_names = feature_names #Xtrain 特征列 ,class_names = ["琴酒","雪莉","贝尔摩德"] #y标签 ,filled=True #渲染颜色 ) graph = graphviz.Source(dot_data,filename='决策树.pdf') graph.render('wine') # 每个指标的重要性 for i in [*zip(feature_names,clf.feature_importances_)]: print(i)
生成pdf的时候出现中文乱码的解决方法:
https://zhuanlan.zhihu.com/p/58784759
防止过拟合和剪枝
1 clf = tree.DecisionTreeClassifier(criterion='entropy' 2 #,max_depth=3 #最大深度 3 #,min_samples_leaf=5 #子节点包含样本最小个数(父节点) 4 ,min_samples_split=20 5 ) #生成决策树分类器 entropy 6 7 clf = clf.fit(Xtrain,Ytrain) 8 9 10 dot_data = tree.export_graphviz(clf 11 ,feature_names = feature_names #Xtrain 特征列 12 ,class_names = ["琴酒","雪莉","贝尔摩德"] #y标签 13 ,filled=True #渲染颜色
,rounded=True #解决中文乱码
14 )
15 graph = graphviz.Source(dot_data)
确定最优的剪枝参数(学习曲线)
test= [] for i in range(10): clf = tree.DecisionTreeClassifier(criterion='entropy' ,max_depth=i+1 #最大深度 #,min_samples_leaf=5 #子节点包含样本最小个数(父节点) #,min_samples_split=20 ,random_state=30 ,splitter='random' ) #生成决策树分类器 entropy clf = clf.fit(Xtrain,Ytrain) score = clf.score(Xtest,Ytest) test.append(score) plt.plot(range(1,11),test,color='red') plt.ylabel('score') plt.xlabel('max_depth') plt.xticks(range(1,11)) plt.show()

max_depth=3 为最优
clf = tree.DecisionTreeClassifier(criterion='entropy'
#,max_depth=3 #最大深度
#,min_samples_leaf=5 #子节点包含样本最小个数(父节点)
,min_samples_split=20
) #生成决策树分类器 entropy
clf = clf.fit(Xtrain,Ytrain)
dot_data = tree.export_graphviz(clf
,feature_names = feature_names #Xtrain 特征列
,class_names = ["琴酒","雪莉","贝尔摩德"] #y标签
,filled=True #渲染颜色
)
graph = graphviz.Source(dot_data)
解决样本不平衡问题
- class_weight
- 混淆举证(精准度)
- recall(细节)
- F值(精准度&细节)
import matplotlib.pyplot as plt from sklearn.tree import DecisionTreeClassifier from sklearn.datasets import make_blobs #聚类产生数据集的方法 from sklearn.model_selection import train_test_split from sklearn import metrics # 混淆矩阵 # 造数据 class_1 = 1000 #类别1 样本1000个 class_2 = 100 #类别2 样本100个 centers = [[0,0],[2.0,2.0]] #两个类别的中心点 clusters_std = [2.5,0.5] #两个类别的方差 X,y = make_blobs(n_samples=[class_1,class_2], centers=centers, cluster_std=clusters_std, random_state=420,shuffle=False) plt.scatter(X[:,0],X[:,1],c=y,cmap='rainbow',s=10) # plt.show() #划分数据集 Xtrain,Xtest,Ytrain,Ytest = train_test_split(X,y,test_size=0.2,random_state=420) #不设定class_weight clf_01 = DecisionTreeClassifier() clf_01.fit(Xtrain,Ytrain) #设定class_weight clf_02 = DecisionTreeClassifier(class_weight='balanced') clf_02.fit(Xtrain,Ytrain) score1 = clf_01.score(Xtest,Ytest) score2 = clf_02.score(Xtest,Ytest) print(score1) # 0.8954545454545455 print(score2) # 0.9045454545454545 # 混淆矩阵,在class_weight的基础上做。在捕捉更少类的情况下准确率的判定 # 平衡前 mix_befor = metrics.confusion_matrix(Ytest,clf_01.predict(Xtest)) # 平衡后 mix_after = metrics.confusion_matrix(Ytest,clf_02.predict(Xtest)) print(mix_befor)# [[184 7][ 15 14]] print(mix_after)# [[183 8][ 12 17]] # 精准度 score3 = metrics.precision_score(Ytest,clf_01.predict(Xtest)) score4 = metrics.precision_score(Ytest,clf_02.predict(Xtest)) print(score3) #0.6666666666666666 print(score4) #0.68 # 召回率,在class_weight的基础上做。召回率越高越敏感,捕捉的细节就越多 call_score01 = metrics.recall_score(Ytest,clf_01.predict(Xtest)) call_score02 = metrics.recall_score(Ytest,clf_02.predict(Xtest)) print(call_score01) # 0.4827586206896552 print(call_score02) # 0.5862068965517241 # F值,在class_weight的基础上做。同时兼顾精准率(混淆矩阵)和召回率(recall) f_score01 = metrics.f1_score(Ytest,clf_01.predict(Xtest)) f_score02 = metrics.f1_score(Ytest,clf_02.predict(Xtest)) print(f_score01) # 0.56 print(f_score02) # 0.6296296296296295
线性回归
1、模型得分
模型的得分是:0.6067440341875014
1 from sklearn.linear_model import LinearRegression 2 from sklearn.model_selection import train_test_split 3 from sklearn.model_selection import cross_val_score 4 from sklearn.datasets import fetch_california_housing #加利福尼亚房屋价值数据集 5 import pandas as pd 6 import matplotlib.pyplot as plt 7 import numpy as np 8 9 #将数据转成DataFrame 10 housevalue = fetch_california_housing() 11 X = pd.DataFrame(housevalue.data,columns=housevalue.feature_names) 12 y = housevalue.target 13 Xtrain,Xtest,Ytrain,Ytest = train_test_split(X,y,test_size=0.3,random_state=420) 14 15 #线性回归模型 16 lr = LinearRegression() 17 #训练数据 18 lr.fit(Xtrain,Ytrain) 19 lr.score(Xtrain,Ytrain) #0.6067440341875014
2、模型的评估:MSE均方误差、交叉验证使用-MSE指标、R方
1 # 1、MSE均方误差,MSE趋于0效果越好 2 from sklearn.metrics import mean_squared_error 3 #对训练集做预测 4 y_pred =lr.predict(Xtrain) #得到预测结果 5 y_test_pred = lr.predict(Xtest) 6 # 评估训练集集合情况 参数1:真实标签 参数2:预测标签 7 mean_squared_error(Ytrain,y_pred) #0.5309012639324568 8 mean_squared_error(Ytest,y_test_pred)
1 # 2、 交叉验证使用-MSE指标 2 lr2 = LinearRegression() 3 cross_val_score(lr2,Xtrain,Ytrain,cv=10,scoring='neg_mean_squared_error')# cv交叉折叠数,值越大计算越慢 4 """ 5 折叠十次的结果: 6 Array([-0.52730876, -0.50816696, -0.48736401, -0.49269076, -0.56611205, 7 8 -0.53795641, -0.48253409, -0.5130032 , -0.53188562, -0.60443733]) 9 """ 10 cross_val_score(lr2,Xtrain,Ytrain,cv=10,scoring='neg_mean_squared_error').mean() #平均数,-0.5313931576388832
R方
- 方差是来衡量数据集包含了多少信息量
- R方越趋于1拟合效果就越好,趋于0拟合效果越差
1 from sklearn.metrics import r2_score 2 r2_score(Ytrain,y_pred) #训练集R2 0.6067440341875014 3 r2_score(Ytest,y_test_pred) #测试集R2 0.6043668160178819 4 lr.score(Xtrain,Ytrain) #0.6067440341875014 5 lr.score(Xtest,Ytest) #0.6043668160178819 6 cross_val_score(lr,Xtrain,Ytrain,cv=10,scoring='r2') 7 """ 8 array([0.61759405, 0.63271089, 0.61770019, 0.61599307, 0.57902382, 9 10 0.59578732, 0.63348265, 0.60091314, 0.59964669, 0.54638642] 11 """ 12 cross_val_score(lr,Xtrain,Ytrain,cv=10,scoring='r2').mean() #0.603923823554634
3、查看模型系数
1 lr.coef_ #训练结果
结果w值:array([ 4.37358931e-01, 1.02112683e-02, -1.07807216e-01, 6.26433828e-01,
5.21612535e-07, -3.34850965e-03, -4.13095938e-01, -4.26210954e-01])
1 lr.intercept_ #截距 -36.25689322920392
综合看结果
1 list(zip(X.columns,lr.coef_))
结果:
[('MedInc', 0.4373589305968402), # MedInc:该街区住户的收入中位数,每上升一个点,影响是0.437
('HouseAge', 0.010211268294494062),
('AveRooms', -0.10780721617317704),
('AveBedrms', 0.6264338275363783),
('Population', 5.21612535300663e-07),
('AveOccup', -0.0033485096463335864),
('Latitude', -0.4130959378947715),
('Longitude', -0.4262109536208475)]
4、将数据集标准化之后再训练(归一法)
1 from sklearn.preprocessing import StandardScaler 2 std = StandardScaler() 3 #对训练集进行标准化 4 X_train_std = std.fit_transform(Xtrain) 5 lr3 = LinearRegression() 6 lr3.fit(X_train_std,Ytrain) 7 lr.score(Xtrain,Ytrain) #0.6067440341875014 8 lr3.score(X_train_std,Ytrain) #0.6067440341875014 归一前和后分数一样,所以不用化一
5、绘制拟合图像
# - 绘制预测值的散点和真实值的直线进行对比
# - 如果两者趋势越接近(预测值的散点越靠近真实值)拟合效果优秀
1 # 因为数据是无序的,所以画出的点是乱的 2 plt.scatter(range(len(Ytest)),Ytest,s=2) 3 plt.show()

1 plt.scatter(range(len(Ytest)),sorted(Ytest),s=2)#排序 2 plt.show()
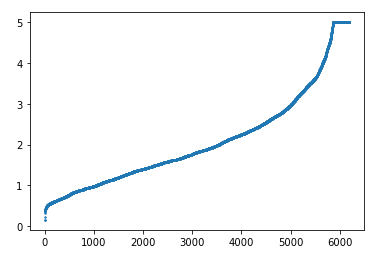
1 #将排序好的数据再进行绘图 2 plt.scatter(range(len(Ytest)),sorted(Ytest),s=2,label='True') 3 plt.scatter(range(len(Ytest)),y_test_pred[np.argsort(Ytest)],s=2,c='r',label='Predict',alpha=0.3) 4 5 plt.legend() 6 plt.show()

6、多重共线性(解决特征与特征之间高度相似)
处理数据
1 from sklearn.preprocessing import PolynomialFeatures 2 X.columns = ['住户的收入中位数','房屋使用年代的中位数','该街区平均的房间数目', 3 '该街区平均的卧室数目','街区人口','平均入住率','街区的纬度','街区的经度'] 4 poly = PolynomialFeatures(degree=2).fit(X,y) 5 poly.get_feature_names(X.columns)#通过多项式构造列 6 X_ = poly.transform(X) #多项式变化后 7 reg = LinearRegression().fit(X_,y)#使用转化后的数据进行建模训练 8 [*zip(poly.get_feature_names(X.columns),reg.coef_)] #查看结果,每个特征值的重要性
与变换前的模型拟合效果进行比对
poly = PolynomialFeatures(degree=4).fit(X,y) X_ = poly.transform(X) lr = LinearRegression().fit(X,y) lr.score(X,y) #0.6062326851998051 lr1 = LinearRegression().fit(X_,y) lr1.score(X_,y) #0.745313897131279
去掉不重要的指标后,模型由之前的0.6变为0.7
逻辑回归
整体思路:
寻找最优参数
1、先比较 L1、L2 与 solver='liblinear'、c 的选取
2、通过网格搜索,比较L2 与solver的四个参数、c 的选取
1 import numpy as np 2 import pandas as pd 3 from sklearn.datasets import load_breast_cancer #乳腺癌数据集 4 import matplotlib.pyplot as plt 5 6 X =load_breast_cancer().data 7 Y =load_breast_cancer().target 8 pd.DataFrame(X) #可以考虑去量纲(标准化) 9 # 建模,目的寻找最优参数penalty,C,solver 10 from sklearn.linear_model import LogisticRegression as LR #逻辑回归 11 from sklearn.model_selection import train_test_split
# LR参数解释(
# penalty='l2', # l2正则化---岭回归 l1正则化---lasso 默认l2
# *,
# dual=False,
# tol=0.0001,
# C=1.0, # C越小表示惩罚力度越大,C越大惩罚力度越小
# fit_intercept=True,
# intercept_scaling=1,
# class_weight=None,
# random_state=None,
# solver='lbfgs', # 梯度下降的方式
# max_iter=100, # 梯度下降会有迭代次数
# multi_class='auto',
# verbose=0,
# warm_start=False,
# n_jobs=None,
# l1_ratio=None,
# )
1 lr1 = LR(penalty='l1',solver='liblinear', #l1 正则化 #liblinear 坐标下降法 2 C= 0.5, 3 max_iter=1000).fit(X,Y) 4 5 lr2 = LR(penalty='l2',solver='liblinear', #l2 正则化 6 C= 0.5, 7 max_iter=1000).fit(X,Y) 8 9 lr1.score(X,Y),lr2.score(X,Y)#(0.9578207381370826, 0.9560632688927944) 10 11 # - L1、L2正则化可以对特征进行筛选 12 lr1.coef_ # w 参数值 ,查看有多少个特征值,特征值少 13 lr2.coef_ # w 参数值 ,查看有多少个特征值,特征值多
由此可见,lr1的分数大于lr2
# - 对当前的数据集来讲,使用L1,特征减少至1/3,精度还是控制96%,说明剩下的特征是比较重要的特征,可以很好体现X与Y之间的关系
# - L2特征越多,模型复杂度越高,更容易将噪声学习到模型中,导致过拟合(模型泛化能力下降),模型特征越少(不能太过),泛化能力越强
1 #对每一行进行预测 2 lr2.predict_proba(X) # 0 1 选择0的概率和1的概率,两者相加为1 3 #lr2.predict_proba(X).sum(axis=1) 4 # 结果:array([[1.00000000e+00, 7.64542333e-15], 5 # [9.99999966e-01, 3.44228638e-08], 6 # [9.99999886e-01, 1.14323500e-07], 7 # ..., 8 # [9.97386529e-01, 2.61347136e-03], 9 # [1.00000000e+00, 1.77462887e-10], 10 # [5.11926033e-02, 9.48807397e-01]])
1 # 绘制学习曲线,寻找最优C 2 # 切分数据集 3 Xtrain,Xtest,Ytrain,Ytest = train_test_split(X,Y,test_size=0.3,random_state=420) 4 # 查看C在L1、L2下训练集和测试集的表现 5 l1 = [] 6 l2 = [] 7 8 l1test = [] 9 l2test = [] 10 11 for i in np.linspace(0.05, 1, 19): 12 # 实例化模型并训练 13 lrl1 = LR(penalty='l1', solver='liblinear', C=i, max_iter=1000).fit(Xtrain, Ytrain) 14 lrl2 = LR(penalty='l2', solver='liblinear', C=i, max_iter=1000).fit(Xtrain, Ytrain) 15 16 # 记录训练集的分数 17 l1.append(lrl1.score(Xtrain, Ytrain)) 18 l2.append(lrl2.score(Xtrain, Ytrain)) 19 20 # 记录测试集的分数 21 l1test.append(lrl1.score(Xtest, Ytest)) 22 l2test.append(lrl2.score(Xtest, Ytest)) 23 24 # 画图 25 graph = [l1, l2, l1test, l2test] 26 color = ["green", "black", "lightgreen", "gray"] 27 label = ["L1", "L2", "L1test", "L2test"] 28 29 plt.figure(figsize=(6, 6)) 30 for i in range(len(graph)): 31 plt.plot(np.linspace(0.05, 1, 19), graph[i], color[i], label=label[i]) 32 plt.legend(loc=4) # 图例的位置在哪⾥?4表示,右下⻆ 33 plt.show()
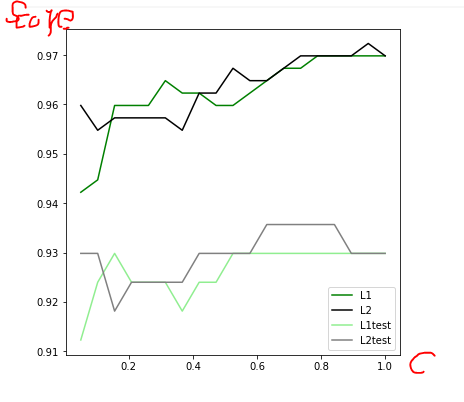
由图可见,L2比L1的分数高,L1和L2相重叠的部分,分数最高的是0.97,对应的C是0.9
1 # 确定C=0.9 关于最大迭代次数绘制学习曲线 2 l2 = [] 3 l2test = [] 4 5 for i in range(1,201,10): 6 lrl2 = LR(penalty='l2',solver='liblinear',C=0.9,max_iter=i).fit(Xtrain,Ytrain) 7 8 l2.append(lrl2.score(Xtrain,Ytrain)) 9 l2test.append(lrl2.score(Xtest,Ytest)) 10 11 plt.plot(range(1,201,10),l2,label='l2') 12 plt.plot(range(1,201,10),l2test,label='l2test') 13 plt.legend(loc=4)
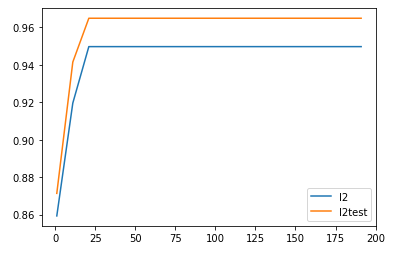
由图可见,L2的训练集的分数是0.95,L2 的测试集的分数是0.97。
目前来说,参数L2, c=0.9, liblinear的分数最高。
网格搜索-确定最优参数
1 # 网格搜索-确定最优参数('liblinear','sag','newton-cg','lbfgs') 2 #导包 3 from sklearn.model_selection import GridSearchCV #网格搜索 4 from sklearn.preprocessing import StandardScaler #标准化 5 data = pd.DataFrame(X,columns= load_breast_cancer().feature_names) 6 data['label'] = Y 7 8 #划分数据集 9 Xtrain,Xtest,Ytrain,Ytest = train_test_split(X,Y,test_size=0.3,random_state=420) 10 11 #对训练集和测试集做标准化---去量纲 12 std = StandardScaler().fit(Xtrain) 13 Xtrain_ = std.transform(Xtrain) 14 Xtest_ = std.transform(Xtest) 15 16 #在l2范式下,判断C和solver的最优值 17 p = { 18 'C':list(np.linspace(0.05,1,19)), 19 'solver':['liblinear','sag','newton-cg','lbfgs'] 20 } 21 22 model = LR(penalty='l2',max_iter=10000) 23 24 GS = GridSearchCV(model,p,cv=5) 25 GS.fit(Xtrain_,Ytrain) 26 GS.best_score_ #最高的得分:0.9874683544303797 27 GS.best_params_#最高参数{'C': 0.3138888888888889, 'solver': 'sag'} 28 29 # 将最优参数重新用于实例化模型,查看训练集和测试集下的分数 30 model = LR(penalty='l2', 31 max_iter=10000, 32 C=GS.best_params_['C'], 33 solver=GS.best_params_['solver']) #sag、newton-cg、lbfgs 三种通过导数计算的方式是不能l1正则化的 34 35 model.fit(Xtrain_,Ytrain) 36 model.score(Xtrain_,Ytrain),model.score(Xtest_,Ytest) 37 #(0.9874371859296482, 0.9649122807017544)
由分数可见,参数L2,Solver=sag,C=0.3138888888888889 时,分数最高,训练集0.98,测试集0.96
精准度
from sklearn.metrics import r2_score
r2_score(Ytrain,y_pred) #训练集R2 0.6067440341875014
r2_score(Ytest,y_test_pred) #测试集R2 0.6043668160178819
lr.score(Xtrain,Ytrain) #0.6067440341875014
lr.score(Xtest,Ytest) #0.6043668160178819
cross_val_score(lr,Xtrain,Ytrain,cv=10,scoring='r2')
"""
array([0.61759405, 0.63271089, 0.61770019, 0.61599307, 0.57902382,
0.59578732, 0.63348265, 0.60091314, 0.59964669, 0.54638642]
"""
cross_val_score(lr,Xtrain,Ytrain,cv=10,scoring='r2').mean() #0.603923823554634
召回率
计算召回率(精准率),实际为正的样本中有多少预测正确
1 from sklearn.metrics import roc_auc_score, recall_score 2 Ytest_pred = model.predict(Xtest_) 3 recall_score(Ytest_pred, Ytest,average='micro') #注意多分类需要增加参数 average='micro' #0.9555555555555556
逻辑回归案例
1 import numpy as np 2 import pandas as pd 3 from sklearn.datasets import load_iris 4 from sklearn.model_selection import train_test_split, GridSearchCV, cross_val_score 5 from sklearn.linear_model import LogisticRegression as LR 6 from sklearn.preprocessing import StandardScaler 7 8 #1.导入数据 9 flowervalue = load_iris() 10 X = pd.DataFrame(flowervalue.data,columns=flowervalue.feature_names) 11 y = flowervalue.target 12 #2.切分数据集 13 Xtrain,Xtest,Ytrain,Ytest = train_test_split(X,y,test_size=0.3,random_state=420) 14 print(X) 15 print(y) 16 #3.使用标准化包,对训练集来学习,从而对训练集和测试集来做标准化 17 std = StandardScaler().fit(Xtrain) 18 Xtrain_ = std.transform(Xtrain) 19 Xtest_ = std.transform(Xtest) 20 print("oooo:",Xtrain_) 21 #4.在确定l2范式的情况下,使用网格搜索判断solver, C的最优组合 22 p = { 23 'C':list(np.linspace(0.05,1,20)), 24 'solver':['liblinear','sag','newton-cg','lbfgs'] 25 } 26 27 model = LR(penalty='l2',max_iter=10000) 28 29 GS = GridSearchCV(model,p,cv=5) 30 GS.fit(Xtrain_,Ytrain) 31 best_score = GS.best_score_ #最高的得分:0.9714285714285715 32 best_params = GS.best_params_#最高参数{'C': 0.41944444444444445, 'solver': 'sag'} 33 print(best_score,best_params) 34 35 #5.将最优的结果重新用来实例化模型,查看训练集和测试集下的分数(20分)(注意多分类需要增加参数 average='micro' 36 model = LR(penalty='l2', 37 max_iter=10000, 38 C=GS.best_params_['C'], 39 solver=GS.best_params_['solver']) 40 model.fit(Xtrain_,Ytrain) 41 scores = model.score(Xtrain_,Ytrain),model.score(Xtest_,Ytest) 42 print(scores) #(0.9714285714285714, 0.9555555555555556) 43 44 #6.计算精准率 45 from sklearn.metrics import roc_auc_score, recall_score 46 Ytest_pred = model.predict(Xtest_) 47 recall_score(Ytest_pred, Ytest,average='micro') #注意多分类需要增加参数 average='micro' #0.9555555555555556

