
mysql 实战宝典
导入中文乱码解决方案
将csv 保存成utf-8的文件
ALTER TABLE user_info SET SERDEPROPERTIES ('serialization.encoding'='GBK');
创建table 的巧妙方式
1 create table user_info as 2 select user_id, 3 age_between, 4 case when sex =1 then '女' when sex=0 then '男' else '保密' end as sex, 5 user_level, 6 reg_time 7 from ods_shop.user_info;
转化成小数
cast(对象 as decimal(10,2))
select cast(sum(sum_pay) over(ORDER BY a.month2) as DECIMAL(10,2)) from table
字符串切割
substring_index 、substr、instr
1 substring_index(providesalary_text,'万/月',1) 2 3 substr(str,1,7) -- 截取1到7位 4 5 -- 对于instr函数,我们经常这样使用:从一个字符串中查找指定子串的位置。例如: 6 select instr('yuechaotianyuechao','ao') 7 substr(title,1,instr(title,"(")-1)
排序窗口函数的区别
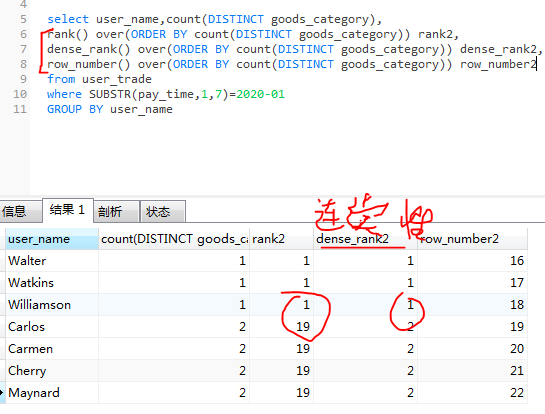
ntile() over()


创建相似的表结构
创建一个与 o_retailers_trade_user 结构相似的表结构,并插入数据
create table temp_trade like o_retailers_trade_user; insert into temp_trade select distinct * from o_retailers_trade_user limit 50000
导入数据sql
count if 和sum case when 的搭配
count( if(behavior_type=1,user_id,null))
sum(case when then end)
两种方法的计数:

留存
思路:
a、两表相连,b表日期大于a表日期
b、count 计数,b-a的日期大于1、2、3.....天
知识点:
c、cast(a as decimal(10,2))保留几位小数
d、concat 字符串的连接
c、substr(str, 1,7) 字符串切割
1 select *, 2 concat(cast(one_after_user/current_day_user as DECIMAL(10,2))*100,'%') 3 4 from 5 6 ( 7 select 8 a.dates, 9 count(DISTINCT a.user_id) current_day_user, 10 count(DISTINCT if(DATEDIFF(b.dates,a.dates)=1,b.user_id,null)) one_after_user 11 from 12 (select user_id,dates from temp_trade group by user_id,dates)a 13 left join 14 (select user_id,dates from temp_trade group by user_id,dates)b 15 on a.user_id=b.user_id 16 where b.dates>a.dates 17 group by a.dates 18 )c
RFM 模型 案例

with p as sql , create view xx as sql
create view clean_d as 2 with p as (select *, 3 4 row_number() over(PARTITION by company_name,job_name ORDER BY issuedate) rank2 5 FROM clean_data) 6 7 8 select * from p where rank2=1
案例:大表 like 小表
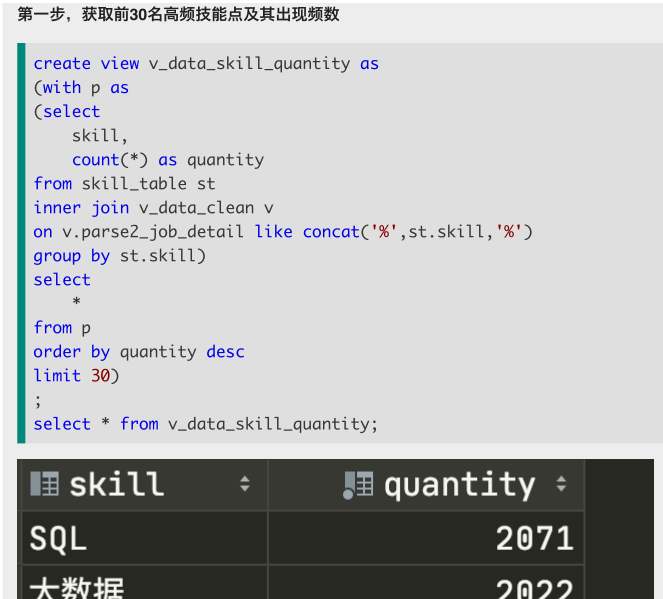
方法一: from 2只表

方法二:
select *, concat(cast(a.sum1/a.sum2*100 as DECIMAL(10,2)),"%") from ( select companytype_text,sum(degreefrom) sum1, (select sum(degreefrom) from clean_d) sum2 from clean_d GROUP BY companytype_text order by sum(degreefrom) desc )a
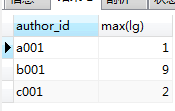
作者最大连更天数,变量用法
1 with p2 as( 2 with p as (select author_id,dates, 3 lag(dates) over(PARTITION by author_id ORDER BY dates) lag_time 4 5 from temp_author_act) 6 7 select * , 8 ( 9 if(DATEDIFF(dates,lag_time)=1,@r:=@r+1,@r:=0) 10 ) as lg 11 from p) 12 13 select author_id,max(lg) from p2 group by author_id
案例1:from_unixtime,now
知识点: from_unixtime(work_start,%Y-%m-%d) 时间戳转日期; now() 当前日期

知识点2:from_unixtime 字符串转时间 unix_timestamp() str/date 转字符串
2021/02/11 转成 2021-02-11
方法一:
select *, to_date( FROM_UNIXTIME( UNIX_TIMESTAMP(rag_time) ) ) from user_info limit 10,2
方法二:
-- replace(rag_time,"/","-")
-- ①取每个城市本月日均营业时长(需刨除当天不营业商家,营业时长单位:小时)
1 select month(date),city, 2 cast(avg(dur_time)/3600 as DECIMAL(10,2)) as 营业时长 3 from self 4 where dur_time is not null 5 and month(date)=month(now()) 6 group BY city
-- ②取截止今日每个商家已合作天数
1 select shoper_id, from_unixtime(work_start,"%Y-%m-%d") as 合作开始日期, 2 DATEDIFF(now(),from_unixtime(work_start,"%Y-%m-%d")) as 合作天数 3 from self GROUP BY shoper_id
1 with p as ( 2 select a.city,a.shoper_id,a.current_month,b.last_month,c.all_month, 3 (a.current_month-b.last_month)/b.last_month as 环比上月, 4 c.all_month-a.current_month as 对比全年差, 5 rank() over(ORDER BY a.current_month desc) as rank2 6 7 from 8 -- 这个月 9 (select city,shoper_id,count(distinct order_id) as current_month from sorder 10 where month(order_time)=month(now()) 11 GROUP BY city,shoper_id)a, 12 -- 上个月 13 (select city,shoper_id,count(distinct order_id) as last_month from sorder 14 where month(order_time)=month(now())-1 15 GROUP BY city,shoper_id)b, 16 -- 所有 17 (select city,shoper_id,count(distinct order_id) as all_month from sorder 18 GROUP BY city,shoper_id)c 19 20 group by city,shoper_id 21 ) 22 select * from p where rank2 <=10
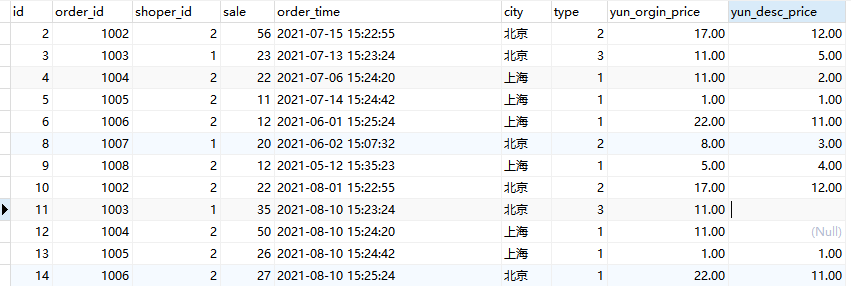
-- ② 取每个城市当月订单量排名前10%商家的总数,早餐商家总数,晚餐商家总数,运费全免商家 占比(运费全免商家:只要有一单全免就是运费全免商家)
1 with p as ( 2 select city,shoper_id,count(order_id) as total_number, 3 count(if (type=1, order_id,null)) as 早餐商家总数, 4 count(if (type=3, order_id,null)) as 晚餐商家总数, 5 count(yun_orgin_price) as 运费总数量, 6 count(ifnull(yun_desc_price,null)) as 免运单量 7 from sorder 8 where month(order_time)=month(now()) 9 GROUP BY city,shoper_id) 10 11 12 select * , 13 concat(cast((免运单量/运费总数量)*100 as DECIMAL(10,2)),"%") as 免单率, 14 ntile(10) over(PARTITION by city,shoper_id ORDER BY total_number) as ntile2 15 from p 16 17 select * from p2 where ntile2=1
案例2:聚到散
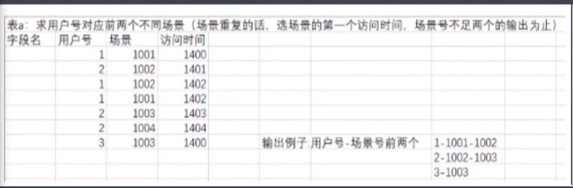
1 with p as ( 2 select *, 3 lead(a.changjing) over(PARTITION by a.userid) as changjing2, 4 row_number() over(PARTITION by a.userid) rank2 5 6 from 7 ( 8 select *, 9 row_number() over(PARTITION by userid,changjing order by inttime) r 10 from mian1 11 )a 12 where a.r=1 13 ) 14 15 select *, 16 concat(userid,"-",changjing,if(changjing2 is null,"",concat("-",changjing2))) 17 18 from p where rank2=1
实战3:
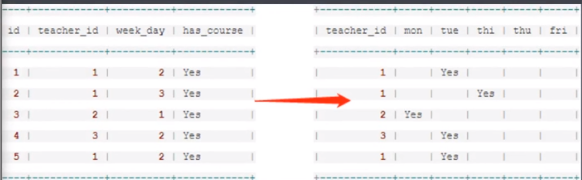
select teacher_id, if(week_day="1","yes","") as mon, if(week_day="2","yes","") as tue, if(week_day="3","yes","") as thi, if(week_day="4","yes","") as thu, if(week_day="5","yes","") as fir from mian3
实战4:
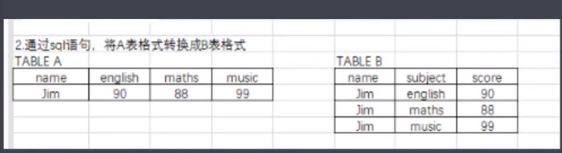
1 select name, "english" as subject,english as score from mian2 2 union 3 select name, "maths" as subject,maths as score from mian2 4 union 5 select name, "music" as subject,music as score from mian2

