

那就来把双色球吧,搏一搏,单车变摩托
import requests, time, os, pandas as pd, numpy as np
from bs4 import BeautifulSoup
def download(url, page):
html = requests.get(url).text
soup = BeautifulSoup(html, 'html.parser')
list = soup.select('div.ball_box01 ul li')
ball = []
for li in list:
ball.append(li.string)
write_to_excel(page, ball)
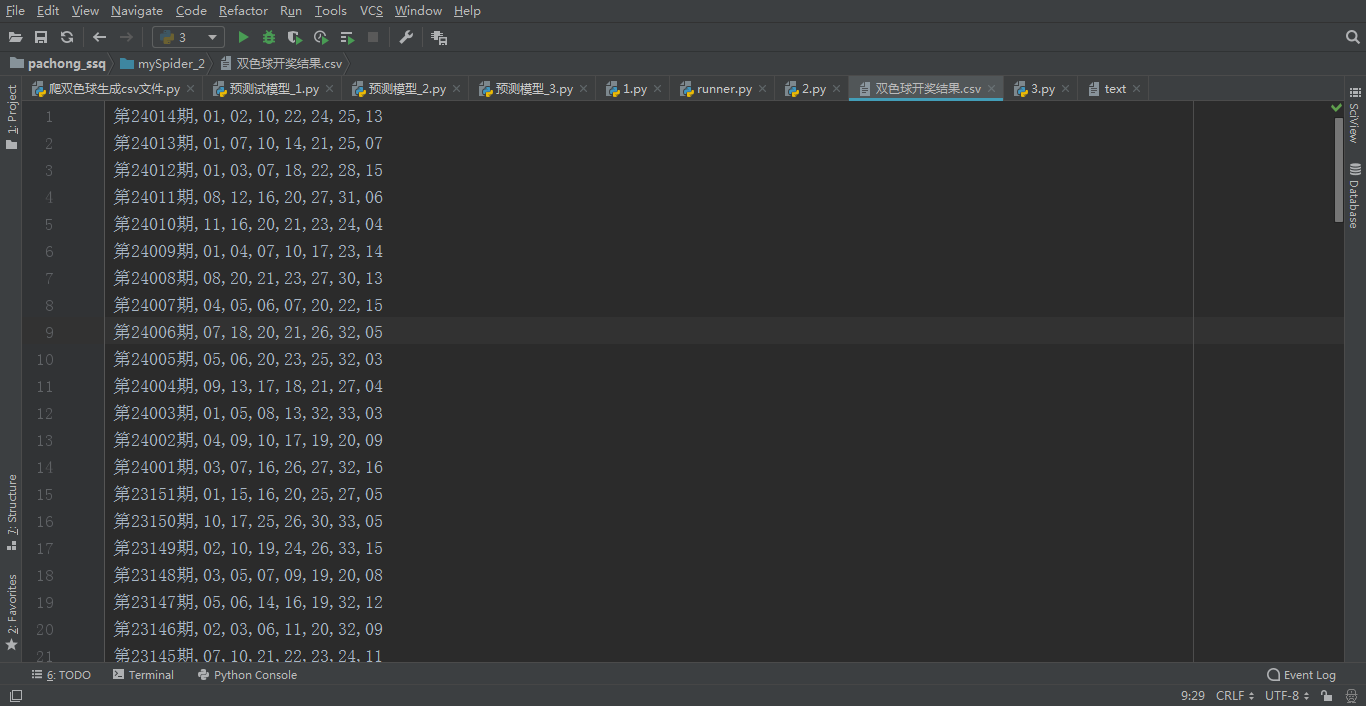
print(f"第{page}期开奖结果录入完成")
def write_to_excel(page, ball):
f = open('双色球开奖结果.csv', 'a', encoding='utf_8_sig')
f.write(f'第{page}期,{ball[0]},{ball[1]},{ball[2]},{ball[3]},{ball[4]},{ball[5]},{ball[6]}\n')
f.close()
def turn_page():
url = "http://kaijiang.500.com/ssq.shtml"
html = requests.get(url).text
soup = BeautifulSoup(html, 'html.parser')
pageList = soup.select("div.iSelectList a")
# 获取最近100期的页码
recent_pages = pageList[:100]
for p in recent_pages:
url = p['href']
page = p.string
download(url, page)
def main():
if os.path.exists('双色球开奖结果.csv'):
os.remove('双色球开奖结果.csv')
turn_page()
if __name__ == '__main__':
print("正在爬取双色球数据,请耐心等待2分钟左右")
time.sleep(5)
main()
print("数据爬取成功,接下来是分析号码,请等到1分钟左右")
time.sleep(5)
# 读取用户提供的双色球中奖号码文件
file_path = '双色球开奖结果.csv'
lottery_data = pd.read_csv(file_path)
# 显示文件的前几行以了解其结构
# print(lottery_data.head())
# 数据处理和分析
# 添加列名以便分析
column_names = ['期号', '红球1', '红球2', '红球3', '红球4', '红球5', '红球6', '蓝球']
lottery_data.columns = column_names
# 将第24014期数据加入到数据集中
first_row = pd.DataFrame([['第24014期', 1, 2, 10, 22, 24, 25, 13]], columns=column_names)
lottery_data = pd.concat([first_row, lottery_data], ignore_index=True)
# 分析红球和蓝球的分布情况
red_ball_distribution = lottery_data.loc[:, '红球1':'红球6'].apply(pd.Series.value_counts).sum(axis=1)
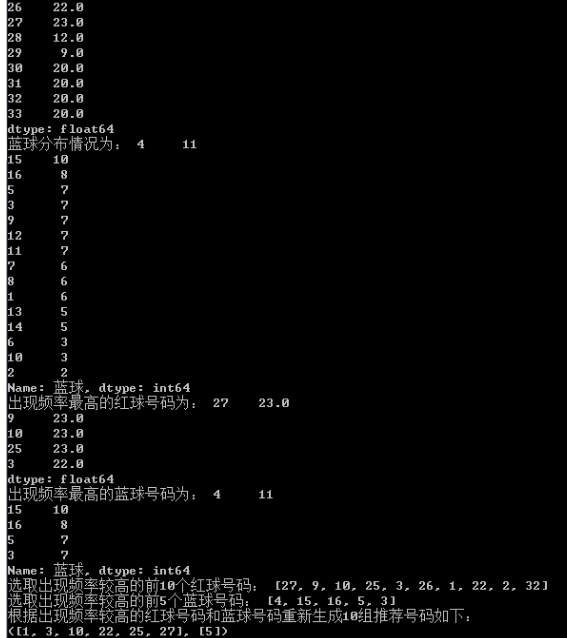
print("红球分布情况如下:", red_ball_distribution)
blue_ball_distribution = lottery_data['蓝球'].value_counts()
print("蓝球分布情况为:", blue_ball_distribution)
# 找出出现频率最高的红球和蓝球号码
most_frequent_red_balls = red_ball_distribution.sort_values(ascending=False).head()
print("出现频率最高的红球号码为:", most_frequent_red_balls)
most_frequent_blue_balls = blue_ball_distribution.sort_values(ascending=False).head()
print("出现频率最高的蓝球号码为:", most_frequent_blue_balls)
# ---------------------
# 设置随机种子以获得可重复的结果
# np.random.seed(0)
# --------------------------
# 由于最常出现的红球不足6个,我们需要扩大选择范围
# 选取出现频率较高的前10个红球号码
frequent_red_balls = red_ball_distribution.sort_values(ascending=False).head(10).index.to_list()
print("选取出现频率较高的前10个红球号码:", )
# 重新生成10组号码
generated_numbers = []
for _ in range(10):
# 从频率较高的红球中随机选择6个
selected_red_balls = np.random.choice(frequent_red_balls, 6, replace=False)
selected_red_balls.sort()
# 根据蓝球频率选择号码
blue_balls = most_frequent_blue_balls.index.to_list()
# 从频率较高的蓝球中随机选择1个
selected_blue_ball = np.random.choice(blue_balls, 1)
# 组合号码
generated_numbers.append((selected_red_balls, selected_blue_ball))
# ----------------
# 修正蓝球号码的列表定义
frequent_blue_balls = blue_ball_distribution.sort_values(ascending=False).head().index.to_list()
print("选取出现频率较高的前5个蓝球号码:", frequent_blue_balls)
generated_numbers = []
for _ in range(10):
# 从频率较高的红球中随机选择6个
selected_red_balls = np.random.choice(frequent_red_balls, 6, replace=False)
selected_red_balls.sort()
# 从频率较高的蓝球中随机选择1个
selected_blue_ball = np.random.choice(frequent_blue_balls, 1)
# 组合号码
generated_numbers.append((selected_red_balls.tolist(), selected_blue_ball.tolist()))
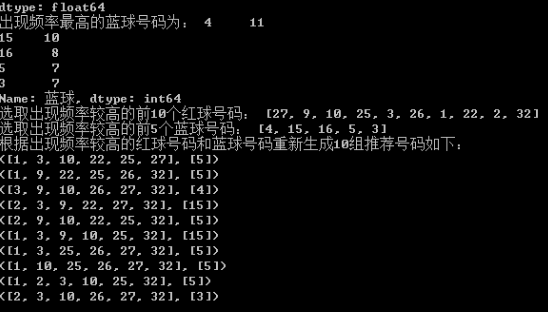
print("根据出现频率较高的红球号码和蓝球号码重新生成10组推荐号码如下:")
for i in generated_numbers:
print(i)
time.sleep(600)
封包/打包成exe文件:pyinstaller -F xx.py文件

爬取到的数据如下:
用一把scrapy的,这个网站的数据:
https://view.lottery.sina.com.cn/lotto/pc_zst/index?lottoType=ssq&actionType=chzs&type=120&dpc=1

pipelines.py管道的编写
import time
class CaiPipeline:
# 希望。 在程序跑起来的时候。打开一个w模式的文件
# 在获取数据的时候正常写入
# 在程序结束的时候。 关闭f
# 仅限于pipeline固定的写法.
# open_spider, 爬虫在开始的时候。 执行
def open_spider(self, spider_name):
print("开始爬取数据====================")
self.f = open("ssq.csv", mode="w", encoding="utf-8")
# close_spider, 爬虫结束的时候。 执行
def close_spider(self, spider_name):
print("已爬取完毕====================")
self.f.close()
# process_item 的作用就是接受spider返回的数据
# spider每次返回一条数据. 这里都会自动的执行一次process_item
# 数据以参数的形式传递过来. item
def process_item(self, item, spider):
# print(spider.name)
# print("这里是管道", item['qi'], item['blue_ball'], item['red_ball'])
# 存储数据,文件, mysql, mongodb, redis
self.f.write(item['qi'])
self.f.write(",")
self.f.write("_".join(item['red_ball']))
self.f.write(",")
self.f.write(item['blue_ball'])
self.f.write("\n")
time.sleep(1)
print("已爬取期数:", item['qi'], "已爬取红球:", item['red_ball'], "已爬取蓝球:", item['blue_ball'])
return item # return在process_item中的逻辑, 是将数据传递给一下管道
配置文件settings.py的编写
# Scrapy settings for mySpider_2 project
#
# For simplicity, this file contains only settings considered important or
# commonly used. You can find more settings consulting the documentation:
#
# https://docs.scrapy.org/en/latest/topics/settings.html
# https://docs.scrapy.org/en/latest/topics/downloader-middleware.html
# https://docs.scrapy.org/en/latest/topics/spider-middleware.html
BOT_NAME = 'mySpider_2'
SPIDER_MODULES = ['mySpider_2.spiders']
NEWSPIDER_MODULE = 'mySpider_2.spiders'
# 配置日志级别
LOG_LEVEL = "WARNING" # 最大限度的保留错误信息. 而又不会被一些乱七八糟的日志影响
# CRITICAL50=> 非常非常严重的错误. 解析器级别的
# ERROR 40=> 报错, 程序挂了
# WARNING 30=> 警告, 过时警告, 不会影响程序的执行.
# INFO 20=> 一些提示信息, print("下载成功")
# DEBUG 10=> 碎嘴子. 啥玩意都记录
USER_AGENT = 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/101.0.4951.54 Safari/537.36'
# Obey robots.txt rules
ROBOTSTXT_OBEY = False
# Configure maximum concurrent requests performed by Scrapy (default: 16)
# CONCURRENT_REQUESTS = 32
# Configure a delay for requests for the same website (default: 0)
# See https://docs.scrapy.org/en/latest/topics/settings.html#download-delay
# See also autothrottle settings and docs
# DOWNLOAD_DELAY = 3
# The download delay setting will honor only one of:
# CONCURRENT_REQUESTS_PER_DOMAIN = 16
# CONCURRENT_REQUESTS_PER_IP = 16
COOKIES_ENABLED = False # 这个要打开。 否则下面的cookie无效的
# TELNETCONSOLE_ENABLED = False
DEFAULT_REQUEST_HEADERS = {
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
'Accept-Language': 'en',
"Cookie": "fvlid=1642167433528aCtTRzzJxa5w; sessionid=25e76ed4-ac76-4c18-86ef-9f05f56e5f71; area=110114; che_sessionid=01720F78-6018-468C-A3E8-35235321AF81%7C%7C2022-01-14+21%3A37%3A13.520%7C%7C0; listuserarea=110100; sessionip=221.218.212.121; Hm_lvt_d381ec2f88158113b9b76f14c497ed48=1652356283; sessionvisit=3d18f224-a438-45a4-849d-531c3f4587d8; sessionvisitInfo=25e76ed4-ac76-4c18-86ef-9f05f56e5f71|www.autohome.com.cn|100533; che_sessionvid=4B36F1DE-CAF9-47AF-B6E6-A4BA52B82875; userarea=110100; ahpvno=5; UsedCarBrowseHistory=0%3A43581488; Hm_lpvt_d381ec2f88158113b9b76f14c497ed48=1652357364; ahuuid=1A75FF15-842E-4369-8720-FD12B13EEB5E; showNum=8; sessionuid=25e76ed4-ac76-4c18-86ef-9f05f56e5f71; v_no=7; visit_info_ad=01720F78-6018-468C-A3E8-35235321AF81||4B36F1DE-CAF9-47AF-B6E6-A4BA52B82875||-1||-1||7; che_ref=www.autohome.com.cn%7C0%7C100533%7C0%7C2022-05-12+20%3A09%3A19.594%7C2022-05-12+20%3A05%3A10.988; carDownPrice=1"
}
# Enable or disable spider middlewares
# See https://docs.scrapy.org/en/latest/topics/spider-middleware.html
# SPIDER_MIDDLEWARES = {
# 'mySpider_2.middlewares.Myspider2SpiderMiddleware': 543,
# }
# Enable or disable downloader middlewares
# See https://docs.scrapy.org/en/latest/topics/downloader-middleware.html
# DOWNLOADER_MIDDLEWARES = {
# 'mySpider_2.middlewares.Myspider2DownloaderMiddleware': 543,
# }
# Enable or disable extensions
# See https://docs.scrapy.org/en/latest/topics/extensions.html
# EXTENSIONS = {
# 'scrapy.extensions.telnet.TelnetConsole': None,
# }
# Configure item pipelines
# See https://docs.scrapy.org/en/latest/topics/item-pipeline.html
ITEM_PIPELINES = {
'mySpider_2.pipelines.CaiPipeline': 300,
}
# Enable and configure the AutoThrottle extension (disabled by default)
# See https://docs.scrapy.org/en/latest/topics/autothrottle.html
# AUTOTHROTTLE_ENABLED = True
# The initial download delay
# AUTOTHROTTLE_START_DELAY = 5
# The maximum download delay to be set in case of high latencies
# AUTOTHROTTLE_MAX_DELAY = 60
# The average number of requests Scrapy should be sending in parallel to
# each remote server
# AUTOTHROTTLE_TARGET_CONCURRENCY = 1.0
# Enable showing throttling stats for every response received:
# AUTOTHROTTLE_DEBUG = False
# Enable and configure HTTP caching (disabled by default)
# See https://docs.scrapy.org/en/latest/topics/downloader-middleware.html#httpcache-middleware-settings
# HTTPCACHE_ENABLED = True
# HTTPCACHE_EXPIRATION_SECS = 0
# HTTPCACHE_DIR = 'httpcache'
# HTTPCACHE_IGNORE_HTTP_CODES = []
# HTTPCACHE_STORAGE = 'scrapy.extensions.httpcache.FilesystemCacheStorage'
数据可视化生成折线图:
import requests, json, sqlite3, xlwt
import requests, json, sqlite3, xlwt, time, datetime
import matplotlib.pyplot as plt
def get_information():
url = 'http://www.cwl.gov.cn/cwl_admin/front/cwlkj/search/kjxx/findDrawNotice?name=ssq&issueCount=100'
response = requests.get(url)
response.raise_for_status()
data = json.loads(response.text).get('result')
return data
def json_data(json_data):
json_data = get_information()
days = datetime.datetime.fromtimestamp(time.time()).strftime('(%Y%m%d)')
with open('Ssq_data' + days + '.json', 'w', encoding='utf-8') as json_file:
json.dump(json_data, json_file, indent=4, ensure_ascii=False)
print("Data saved successfully")
def probability_data(json_data):
json_data = get_information()
red_num_frequency = {}
blue_num_frequency = {}
for entry in json_data:
for number in entry['red'].split(","): # .split(): change str to list
red_num_frequency[number] = red_num_frequency.get(number, 0) + 1
blue_num_frequency[entry['blue']] = blue_num_frequency.get(entry['blue'], 0) + 1
return red_num_frequency, blue_num_frequency
def sorted_dict(dicnary):
sorted_dict = {}
for i in sorted(dicnary):
sorted_dict[i] = dicnary[i]
return sorted_dict
def lineChart(data):
data = probability_data(data)
redx_lst = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28,
29, 30, 31, 32, 33]
red_data = sorted_dict(data[0])
redy_lst = list(red_data.values())
bluex_lst = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16]
blue_data = sorted_dict(data[1])
bluey_lst = list(blue_data.values())
fig, d_image = plt.subplots()
fig.set_size_inches(12, 8)
d_image.plot(redx_lst, redy_lst, "r-.o", c='#CC3333', linestyle='-', label='red_number')
d_image.plot(bluex_lst, bluey_lst, "r-.o", c='#0099CC', linestyle='-', label='blue_number')
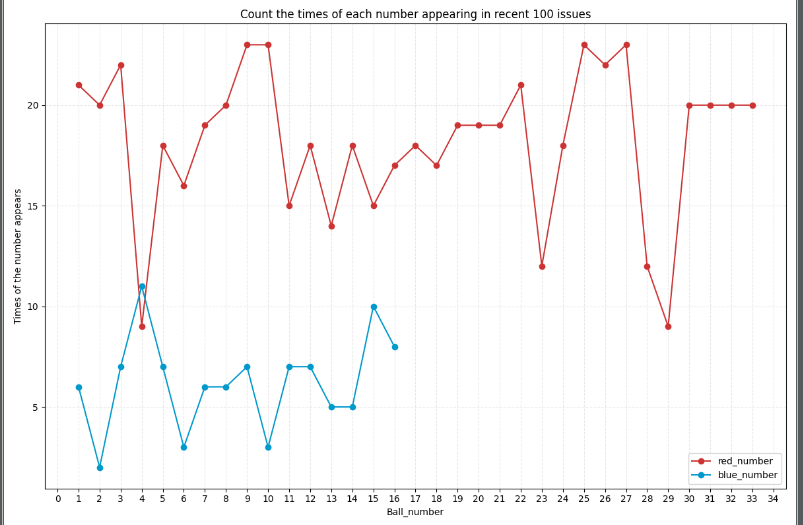
d_image.set_title('Count the times of each number appearing in recent 100 issues')
d_image.set_xlabel('Ball_number')
d_image.set_ylabel('Times of the number appears')
days = datetime.datetime.fromtimestamp(time.time()).strftime('(%Y%m%d)')
x_tick_label = range(35)
plt.xticks(x_tick_label)
plt.grid(True, linestyle='--', alpha=0.3)
plt.legend(loc='lower right', fontsize=10) # legend's setting (position,upper or lower,fontsize etc)
plt.savefig('doublex_color' + days + '.jpg') # saving image
plt.show()
lineChart(1)
数据可视化pyecharts生成折线图官方).html、折线图自定义).html、系统主题.html
import requests, time
from bs4 import BeautifulSoup
import openpyxl
from pyecharts.charts import Bar, Line # 官方已取消 pyecharts.Bar 方式导入
from pyecharts import options
from pyecharts.globals import ThemeType
from datetime import datetime
from pyecharts.datasets import register_files
# 获取双色球中奖号码信息
def get_data(n):
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36 QIHU 360SE'
}
url = 'https://chart.cp.360.cn/kaijiang/ssq?lotId=220051&chartType=undefined&spanType=0&span={}'.format(
n) # 爬取期数
respons = requests.get(url, headers=headers)
text = respons.text
soup = BeautifulSoup(text, 'lxml')
tbody = soup.find_all('thead', class_="kaijiang")[0]
tbody_th = tbody.find_all('th')
# 创建一个excel文件
wb = openpyxl.Workbook() # 新建excel文件
ws = wb.active # 激活sheet,用于后续将数据写入
ws.title = '双色球中奖信息' # 指定sheet的名称
# 将“表头”写入excel中
ws.cell(row=1, column=1,
value=list(tbody_th[0].stripped_strings)[0]) # cell 方法给excel写入数据,row= 行,column=列,value=要写入的值
ws.cell(row=1, column=2, value=list(tbody_th[1].stripped_strings)[0])
ws.cell(row=1, column=3, value=list(tbody_th[-6].stripped_strings)[0])
ws.cell(row=1, column=4, value=list(tbody_th[-5].stripped_strings)[0])
tbody = soup.find_all('tbody', id="data-tab")[0]
trs = tbody.find_all('tr')
data_list = [] # 要写入excel的数据
red_list = [] # 红球
blue_list = [] # 蓝球
for tr in trs:
tds = tr.find_all('td')[:4]
blue_list.append(list(tds[3].stripped_strings)[0]) # 获取蓝球号码
tds_text = [] # 中奖号码信息
redBall = ''
for index, td in enumerate(tds):
if index == 2: # 红球
for i in list(td.stripped_strings):
redBall = redBall + ' ' + i
red_list.append(i)
tds_text.append(redBall.lstrip())
else:
tds_text.append(list(td.stripped_strings)[0])
data_list.append(tds_text)
for i, dl in enumerate(data_list):
for j, dt in enumerate(dl):
ws.cell(row=i + 2, column=j + 1, value=dt) # 将中奖号码信息写入excel中
wb.save('双色球中奖信息.xlsx') # 将数据保存到本地excel中
return red_list, blue_list
# 获取球出现的次数
def count_ball(ball_list, color_list):
'''
:param ball_list: 所有中奖号码,红球+蓝球 剔重数据
:param color_list: 红球号码或蓝球号码
:return: 中奖号码出现的次数
'''
ball_dict = {}
for d in ball_list:
ball_dict[d] = 0
for ball in ball_list:
ball_dict[ball] = color_list.count(ball) # 获取球出现的次数
count_y = list(ball_dict.values())
return count_y
# 柱状图
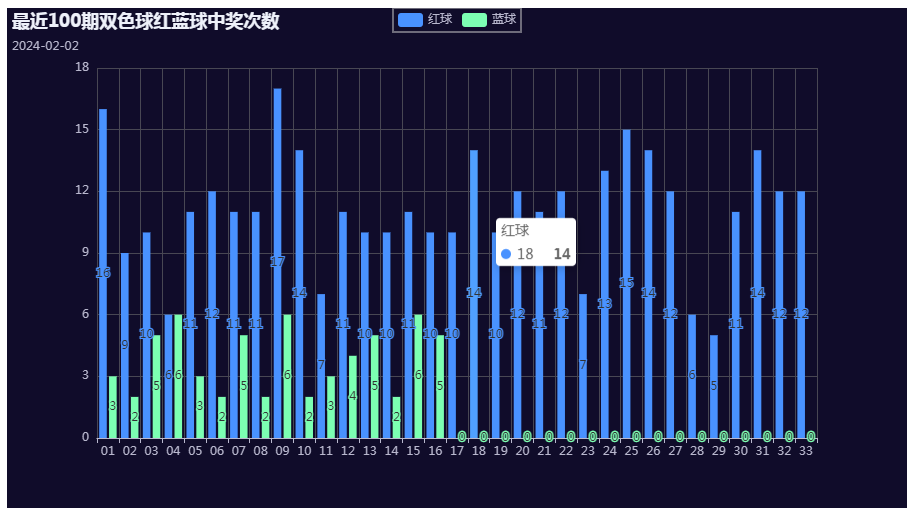
def mkCharts(x, y1, y2, n):
bar = Bar(init_opts=options.InitOpts(theme=ThemeType.DARK)) # 对表格添加主题
bar.add_xaxis(x) # x轴:所有中奖号码,红球+蓝球
bar.add_yaxis('红球', y1)
bar.add_yaxis('蓝球', y2)
tim = datetime.now().strftime('%Y-%m-%d')
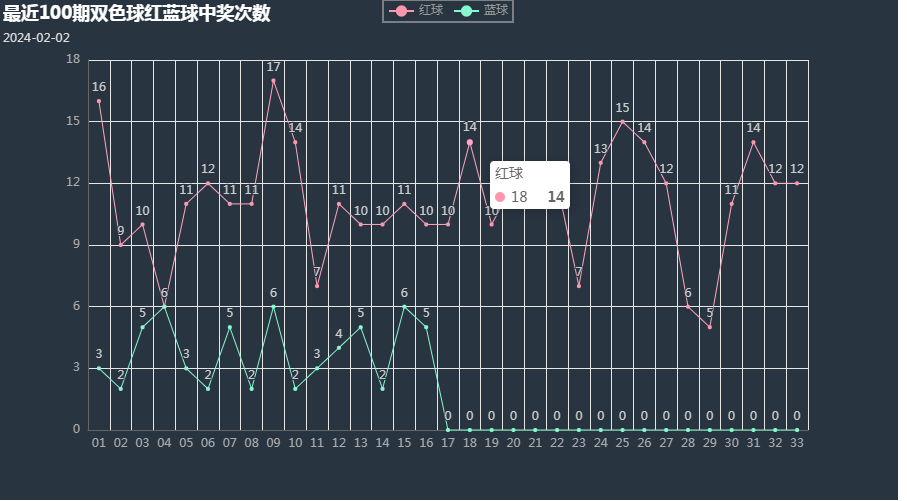
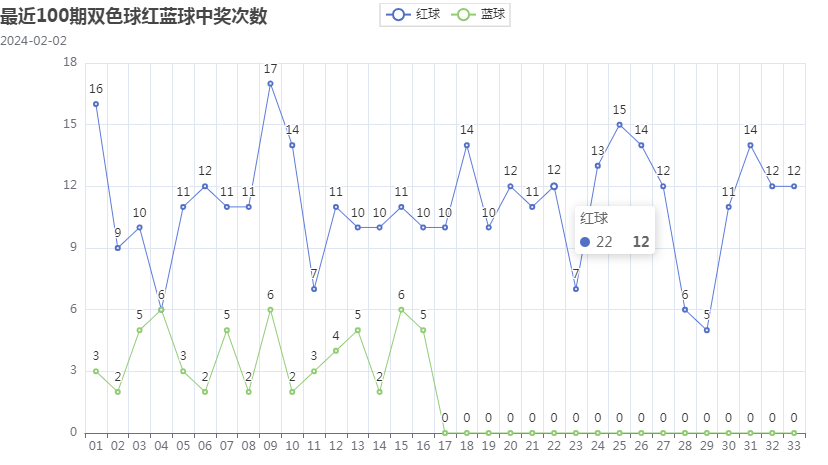
bar.set_global_opts(title_opts=options.TitleOpts(title="最近{}期双色球红蓝球中奖次数".format(n), subtitle=tim))
bar.render('双色球(柱状图).html')
# 折线图,使用官方主题 https://pyecharts.org/#/zh-cn/themes?id=%e4%b8%bb%e9%a2%98%e9%a3%8e%e6%a0%bc
def mkLine1(x, y1, y2, n):
tim = datetime.now().strftime('%Y-%m-%d')
line = (
Line(init_opts=options.InitOpts(theme=ThemeType.CHALK))
.add_xaxis(x)
.add_yaxis('红球', y1)
.add_yaxis('蓝球', y2)
.set_global_opts(title_opts=options.TitleOpts(title="最近{}期双色球红蓝球中奖次数".format(n), subtitle=tim))
)
line.render('双色球(折线图官方).html')
# 使用主题工具创建主题 https://echarts.baidu.com/theme-builder/
def mkLine2(x, y1, y2, n):
register_files({'myTheme': ['/js/customed.project', 'json']})
tim = datetime.now().strftime('%Y-%m-%d')
line = (
# Line(init_opts=options.InitOpts(theme=ThemeType.WESTEROS))
Line(init_opts=options.InitOpts(theme="myTheme"))
.add_xaxis(x)
.add_yaxis('红球', y1)
.add_yaxis('蓝球', y2)
.set_global_opts(title_opts=options.TitleOpts(title="最近{}期双色球红蓝球中奖次数".format(n), subtitle=tim))
)
line.render('双色球(折线图自定义).html')
def main(n):
red_list = get_data(n)[0]
blue_list = get_data(n)[1]
x = sorted(set(red_list + blue_list))
y_red = count_ball(x, red_list)
y_blue = count_ball(x, blue_list)
mkCharts(x, y_red, y_blue, n) # 柱状图
mkLine1(x, y_red, y_blue, n) # 系统主题
mkLine2(x, y_red, y_blue, n) # 自定义主题
if __name__ == '__main__':
print("正在爬取双色球近100期数据,请不要关闭此窗口,大约等待1分钟左右")
time.sleep(5)
# n = input('您想获取最近多少期的数据?\n')
main(5)
print('统计信息已爬取完成,请查看本文件夹内的双色球中奖信息.xlsx和双色球(折线图官方).html和双色球(折线图自定义).html和双色球(柱状图).html')
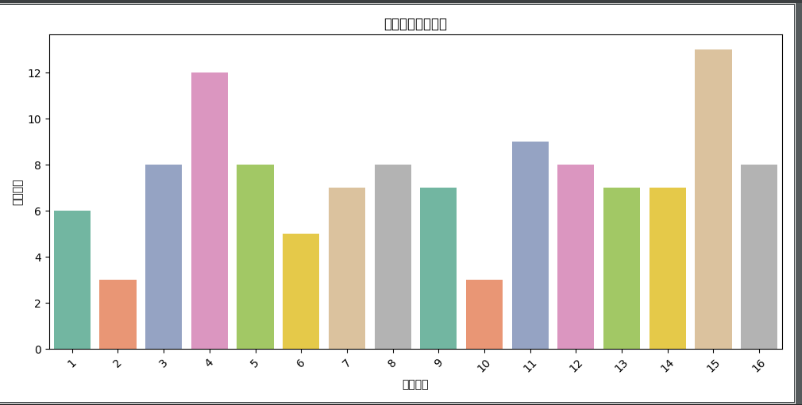
matplotlib生成柱形图片
import matplotlib.pyplot as plt
import seaborn as sns
import pandas as pd
import warnings,time
import time
warnings.filterwarnings("ignore") # 去除不影响程序运行的警告
print("可视化生成中,请稍等")
df = pd.read_csv('ssq.csv')
# 查看文件内容以决定可视化方案
df.head()
# 预处理红球数据
df['红球'] = df.iloc[:, 1].apply(lambda x: [int(num) for num in x.split('_')])
red_balls = df['红球'].explode()
# 预处理蓝球数据
blue_balls = df.iloc[:, 2].astype(int) # 转换蓝球数据为整型
# 红球分布情况可视化
plt.figure(figsize=(12, 6))
sns.countplot(x=red_balls, palette='Set3')
plt.title('红球号码分布情况')
plt.xlabel('红球号码')
plt.ylabel('出现频次')
plt.xticks(rotation=45)
plt.tight_layout()
plt.show()
# 蓝球分布情况可视化
plt.figure(figsize=(10, 5))
sns.countplot(x=blue_balls, palette='Set2')
plt.title('蓝球号码分布情况')
plt.xlabel('蓝球号码')
plt.ylabel('出现频次')
plt.xticks(rotation=45)
plt.tight_layout()
plt.show()
time.sleep(10)



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· Manus爆火,是硬核还是营销?
· 终于写完轮子一部分:tcp代理 了,记录一下
· 别再用vector<bool>了!Google高级工程师:这可能是STL最大的设计失误
· 单元测试从入门到精通
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了