

爬虫常用写法和用法
1、查找所有:结果 = re.findall(正则, 字符串) => 返回列表,用法:r""专业写正则的。 没有转义的烦恼,result = re.findall(r"\d+", "我有1000万,不给你花,我有1块我给你")
2、结果 = re.finditer(正则, 字符串) => 返回迭代器(需要for循环),
result = re.finditer(r"\d+", "我有1000万,不给你花,我有1块我给你")
print(result) # iterator 循环拿结果
for it in result: # <re.Match object; span=(2, 6), match='1000'>
# print(it) # 从每一个Match里拿结果
print(it.group()) # group叫分组
# finditer =》迭代器 =》循环 => match => group()
3、# 结果 = re.search(正则,字符串), 全局搜索。 搜索到了。直接返回结果(返回第一个结果)
r = re.search(r"\d+", "我有1000万,不给你花,我有1块我给你")
print(r) # <re.Match object; span=(2, 6), match='1000'>
print(r.group())
4、多个相同格式的结果: finditer、单个格式的结果: search
5、加载好一个正则表达式用compile:obj = re.compile(r"\d+")
6、() 分组,?P<名字> 给这一组起名字,提取的时候就可以根据分组名字来提取具体数据,
s = """hahah<div class='西游记'><span id='10010'>中国联通</span></div><div class='三国杀'><span id='10086'>中国移动</span></div>heheh"""
obj = re.compile(r"<div class='(?P<jay>.*?)'><span id='(?P<id>.*?)'>(?P<lt>.*?)</span></div>")
result = obj.finditer(s)
for item in result:
print(item.group("jay"))
print(item.group("id"))
print(item.group("lt"))
7、常用元字符
. √匹配除换行符以外的任意字符, 未来在python的re模块中是一个坑.
\w √匹配字母或数字或下划线.
\s 匹配任意的空白符
\d √匹配数字
\n 匹配一个换行符
\t 匹配一个制表符
^ 匹配字符串的开始
$ 匹配字符串的结尾
\W 匹配非字母或数字或下划线
\D 匹配非数字
\S 匹配非空白符
a|b 匹配字符a或字符b
() √匹配括号内的表达式,也表示一个组
[...] √匹配字符组中的字符
[^...] 匹配除了字符组中字符的所有字符
8、量词: 控制前面的元字符出现的次数
* 重复零次或更多次
+ 重复一次或更多次
? 重复零次或一次
{n} 重复n次
{n,} 重复n次或更多次
{n,m} 重复n到m次
.* 贪婪匹配, 尽可能多的去匹配结果
.*? 惰性匹配, 尽可能少的去匹配结果 -> 回溯
9、xpath解析:
from lxml import etree
# import lxml
# etree = lxml.etree
# 准备一段html
f = open("index.html", mode="r", encoding="utf-8")
content = f.read() # 页面源代码 # type: xxxxxx
# 1. etree.HTML(页面源代码) BeautfulSoup(页面源代码)
page = etree.HTML(content) # type: etree._Element # 给pycharm看的 # 默认pycharm不知道什么类型. 没有代码提示
# 2. xpath() # 筛选
# page.xpath("?????")
# print(main_page)
# print(type(main_page)) # <class 'lxml.etree._Element'>
# main_page
# 以后写代码. 没提示怎么办?
# 用type() 得到数据类型.
# 去变量被赋值位置, 添加 # type: 类型
# 语法1, 根节点
# / 出现在开头. 表示根节点
# xpath得到的结果永远永远是列表
root = page.xpath("/html") # [<Element xxx at xxx>]
print(type(root))
print(root)
# / 出现在中间 直接子节点
p = page.xpath("/html/body/div/p")
print("p", p) # type(p) ????
# / 出现在中间 也有可能是找某个节点内部的东西
# text() 提取内部的文本
s = page.xpath("/html/body/div/p/text()") # []
print("s", s) # ['一个很厉害的人']
# # // 提取的后代节点
s = page.xpath("/html/body/div/p//text()")
print("s", s)
# // 查找所有子节点 /p 所有子节点中的p
divs = page.xpath("//div/p/text()")
print("divs", divs)
# 在xpath里 [] 里面可以给出位置. 位置是从1开始数的
zi = page.xpath("//ol/ol/li[2]/text()")
print("zi", zi)
# li[3] 表示 上层标签中第三个li
r = page.xpath("//li[3]/text()")
print(r) # ?
# xpath语法中 @属性
z = page.xpath("//ol/li[@id='10086']/text()")
print(z)
z = page.xpath("//li[@id='10086']/text()")
print(z)
# 这里写属性选择的时候. 直接复制即可(页面源代码).
j = page.xpath("//li[@class='jay haha']/text()")
print(j)
# * 单个任意标签
x = page.xpath("//*[@ygl='杜景泽']/text()")
print(x)
z = page.xpath("//div/*/span/text()")
print(z)
# 拿到ul中每一个href
# @href 拿href的值
# 方案一. A
href = page.xpath("//ul/li/a/@href")
for h in href:
print(h)
# 后续的操作。和该页面没有其他关系了
# 此时直接拿href没问题!!
# 方案二. B 可扩展性更好一些。
a_list = page.xpath("//ul/li/a")
for a in a_list:
href = a.xpath("./@href")[0]
txt_lst = a.xpath("./text()")
if txt_lst: # 判断
txt = txt_lst[0]
else:
txt = ""
# 需要把文字和href写入文件
print(txt, href) # index out of range
# last() 最后一个
li = page.xpath("//ol/li[last()]/a/@href")
print(li)
10、Cookie:cookie就是保存在客户端(浏览器)上的一个字符串. 在每次发送请求时, 浏览器会自动的带上cookie的信息传递给服务器,尤其在用户登录后, 为了能准确的获取到用户登录信息. cookie一般都会在请求是跟随请求头一起提交到服务器
import requests
# 用户名, 密码, url => 抓包
url = "https://passport.17k.com/ck/user/login"
data = {
"loginName": "16538989670",
"password": "q6035945",
}
resp = requests.post(url, data=data)
# print(resp.headers)
# 如何拿到这一堆cookie
# print(resp.headers['Set-Cookie']) # 字符串
# print(resp.cookies)
d = resp.cookies # requestscookieJar
# 书架
url = "https://user.17k.com/ck/author/shelf?page=1&appKey=2406394919"
resp_2 = requests.get(url, cookies=d)
print(resp_2.text)
11、session:在`requests`模块中提供了session这个功能. 它能保持会话过程, 听着听绕嘴. 但其实就是它能自动帮我们管理和维护cookie. <span style="color:red;background:yellow;">但请注意, 它能自动维护的只能是响应头返回的cookie. `js`动态添加的cookie. 它可管不了.</span>
import requests
# 1.创建一个session
session = requests.session()
# 2.可以提前给session设置好请求头或者cookie
session.headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/99.0.4844.84 Safari/537.36"
}
# 登录
url = "https://passport.17k.com/ck/user/login"
data = {
"loginName": "16538989670",
"password": "q6035945",
}
session.post(url, data=data) # resp.header set-cookie
# 后续的所有请求. 都会带着cookie
url = "https://user.17k.com/ck/author/shelf?page=1&appKey=2406394919"
resp_2 = session.get(url)
12、代理:当我们反复抓取一个网站时, 由于请求过于频繁, 服务器很可能会将你的IP进行封锁来反爬. 应对方案就是通过网络代理的形式进行伪装,
13、代理网站:http://www.kxdaili.com/dailiip/2/1.html
import requests
headers = {
"User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_4) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.141 Safari/537.36",
}
# 准备代理
dic = {
"http": "http://223.96.90.216:8085",
"https": "https://223.96.90.216:8085",
}
# proxies = 代理
resp = requests.get("http://www.baidu.com/s?ie=UTF-8&wd=ip", proxies=dic, headers=headers)
print(resp.text)
14、进程: 运行中的程序. 每次我们执行一个程序, 咱们的操作系统对自动的为这个程序准备一些必要的资源(例如, 分配内存, 创建一个能够执行的线程. )
线程: 程序内, 可以直接被CPU调度的执行过程. 是操作系统能够进行运算调度的最小单位. 它被包含在进程之中, 是进程中的实际运作单位.
进程与线程之间的关系:进程是资源单位(公司). 线程是执行单位(员工). 就好比是一家公司. 一家公司的资源就是桌椅板凳, 电脑饮水机这些资源, 但是, 我们如果说一家公司正在运转着, 运行着. 那里面必须要有能为这家公司工作的人. 程序里面也一样, 进程就是为了程序运行而需要的各种资源. 但是程序想要运行, 就必须由线程来被CPU调度执行.
我们运行的每一个程序默认都会有一个线程. 哪怕是只有helloworld级别的程序. 想要执行. 也会有一个线程产生.,多线程就是让程序产生多个线程一起去执行. 还拿公司举例子. 一家公司里如果只有一个员工, 工作效率肯定不会高到哪里去. 怎么提高效率? 多招点儿人就OK了.
15、从浏览器复制cookie并加工使用
def start_requests(self):
# 直接从浏览器复制
cookies = "GUID=bbb5f65a-2fa2-40a0-ac87-49840eae4ad1; c_channel=0; c_csc=web; Hm_lvt_9793f42b498361373512340937deb2a0=1627572532,1627711457,1627898858,1628144975; accessToken=avatarUrl%3Dhttps%253A%252F%252Fcdn.static.17k.com%252Fuser%252Favatar%252F16%252F16%252F64%252F75836416.jpg-88x88%253Fv%253D1610625030000%26id%3D75836416%26nickname%3D%25E5%25AD%25A4%25E9%25AD%2582%25E9%2587%258E%25E9%25AC%25BCsb%26e%3D1643697376%26s%3D73f8877e452e744c; sensorsdata2015jssdkcross=%7B%22distinct_id%22%3A%2275836416%22%2C%22%24device_id%22%3A%2217700ba9c71257-035a42ce449776-326d7006-2073600-17700ba9c728de%22%2C%22props%22%3A%7B%22%24latest_traffic_source_type%22%3A%22%E7%9B%B4%E6%8E%A5%E6%B5%81%E9%87%8F%22%2C%22%24latest_referrer%22%3A%22%22%2C%22%24latest_referrer_host%22%3A%22%22%2C%22%24latest_search_keyword%22%3A%22%E6%9C%AA%E5%8F%96%E5%88%B0%E5%80%BC_%E7%9B%B4%E6%8E%A5%E6%89%93%E5%BC%80%22%7D%2C%22first_id%22%3A%22bbb5f65a-2fa2-40a0-ac87-49840eae4ad1%22%7D; Hm_lpvt_9793f42b498361373512340937deb2a0=1628145672"
cookie_dic = {}
for c in cookies.split("; "):
k, v = c.split("=")
cookie_dic[k] = v
yield Request(
url=LoginSpider.start_urls[0],
cookies=cookie_dic,
callback=self.parse
)
16、用.py文件执行虫子,创建runner.py,代码如下:
from scrapy.cmdline import execute
if __name__ == '__main__':
execute("scrapy crawl baidu".split())
或execute(["scrapy", "crawl", "baidu"])
17、LinkExtractor: 链接提取器. 可以非常方便的帮助我们从一个响应页面中提取到url链接. 我们只需要提前定义好规则即可. 参数如下:
allow, 接收一堆正则表达式, 可以提取出符合该正则的链接
deny, 接收一堆正则表达式, 可以剔除符合该正则的链接
allow_domains: 接收一堆域名, 符合里面的域名的链接被提取
deny_domains: 接收一堆域名, 剔除不符合该域名的链接
restrict_xpaths: 接收一堆xpath, 可以提取符合要求xpath的链接
restrict_css: 接收一堆css选择器, 可以提取符合要求的css选择器的链接
tags: 接收一堆标签名, 从某个标签中提取链接, 默认a, area
attrs: 接收一堆属性名, 从某个属性中提取链接, 默认href
import scrapy
from scrapy.linkextractors import LinkExtractor
class JiaSpider(scrapy.Spider):
name = 'jia'
allowed_domains = ['che168.com']
start_urls = ['https://www.che168.com/beijing/a0_0msdgscncgpi1ltocsp1exx0/']
def parse(self, resp, **kwargs):
# 提取链接用的
lk1 = LinkExtractor(restrict_xpaths="//ul[@class='viewlist_ul']/li/a",
deny_domains=("topicm.che168.com",)) # 提取详情页的url地址
links = lk1.extract_links(resp)
for link in links:
url = link.url
text = link.text
# print(url)
# 分页的连接提取
lk2 = LinkExtractor(allow=r"beijing/a0_0msdgscncgpi1ltocsp\d+exx0")
links = lk2.extract_links(resp)
for link in links:
print(link.url)
18、CrawlSpider的工作流程:前期和普通的spider是一致的. 在第一次请求回来之后. 会自动的将返回的response按照rules中订制的规则来提取链接. 并进一步执行callback中的回调. 如果follow是True, 则继续在响应的内容中继续使用该规则提取链接. 相当于在parse中的scrapy.request(xxx, callback=self.parse)
import scrapy
from scrapy.linkextractors import LinkExtractor # 链接提取器
from scrapy.spiders import CrawlSpider, Rule
class TangSpider(CrawlSpider):
name = 'tang'
allowed_domains = ['shicimingjv.com']
start_urls = ['https://www.shicimingjv.com/tangshi/index_1.html'] # => parse
lk1 = LinkExtractor(restrict_xpaths="//div[@class='sec-panel-body']/ul/li/div/h3/a")
lk2 = LinkExtractor(restrict_xpaths="//ul[@class='pagination']/li/a")
rules = (
# 这里crawlspider会自动提取链接, 并自动发送请求
Rule(lk1, callback='parse_item'),
# 把刚才的逻辑在来一遍
# lk2 能够拿到-》 2.html, 3.html...4.5.6
Rule(lk2, follow=True), # follow: 表示是否继续重新来一遍 =>前面的callback=self.parse
)
def parse_item(self, response, **kwargs):
# 解析详情页的内容
title = response.xpath("//h1[@class='mp3']/text()").extract_first()
print(title)
19、创建python虚拟环境:
pip install virtualenv
d:
mkdir envs
mkdir crm
python3 -m venv testvenv
20、安装pyqt5失败时解决办法:pip install PyQt5==5.10.1 -i https://pypi.tuna.tsinghua.edu.cn/simplepip install PyQt5 -i https://pypi.tuna.tsinghua.edu.cn/simple
https://blog.csdn.net/qq_41185868/article/details/80903095
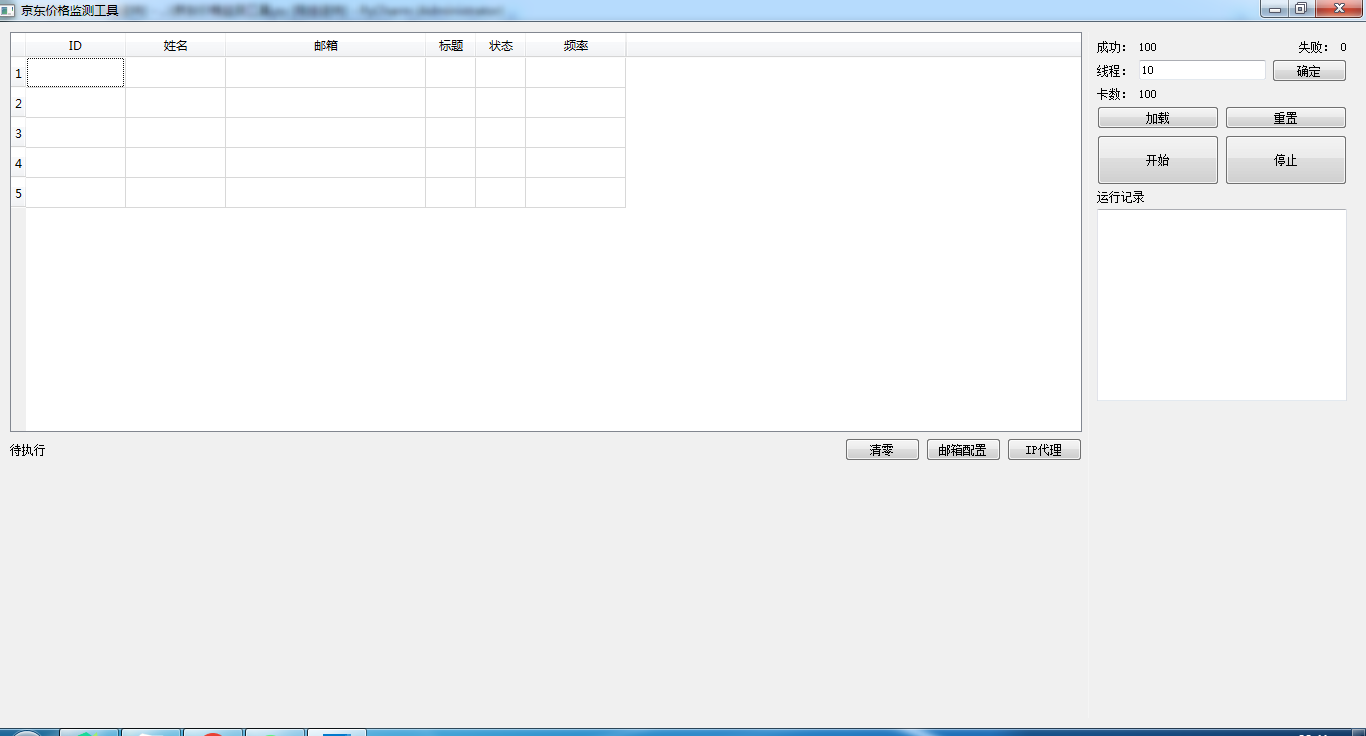
21、那就来一个京东价格监测工具.py
import sys
from PyQt5.QtWidgets import QApplication, QWidget, QDesktopWidget, QHBoxLayout, QVBoxLayout, QPushButton, QLineEdit, \
QTextEdit
from PyQt5.QtWidgets import QTableWidget, QTableWidgetItem, QLabel
class MainWindow(QWidget):
def __init__(self):
super().__init__()
# 窗体标题和尺寸
self.setWindowTitle('京东价格监测工具')
# 窗体的尺寸
self.resize(1150, 450)
# 窗体位置
qr = self.frameGeometry()
cp = QDesktopWidget().availableGeometry().center()
qr.moveCenter(cp)
# 创建布局 div
layout = QHBoxLayout() # 水平方向
layout.setContentsMargins(10, 10, 10, 10)
left = QVBoxLayout()
headers = [("ID", 100), ("姓名", 100), ("邮箱", 200), ("标题", 50), ("状态", 50), ("频率", 100)]
table = QTableWidget(5, len(headers))
table.setMinimumHeight(400)
for idx, ele in enumerate(headers):
text, width = ele
item = QTableWidgetItem()
item.setText(text)
table.setHorizontalHeaderItem(idx, item)
table.setColumnWidth(idx, width)
left.addWidget(table)
footer_layout = QHBoxLayout() # 水平反向
lbl = QLabel("待执行")
footer_layout.addWidget(lbl)
footer_layout.addStretch(1) # 弹簧
footer_layout.addWidget(QPushButton("清零"))
footer_layout.addWidget(QPushButton("邮箱配置"))
footer_layout.addWidget(QPushButton("IP代理"))
left.addLayout(footer_layout)
left.addStretch(1)
layout.addLayout(left, 4)
# 右边
r = QWidget()
r.setStyleSheet("border-left:1px solid rgb(245,245,245)")
right = QVBoxLayout()
h1 = QHBoxLayout()
h1.addWidget(QLabel("成功:"))
h1.addWidget(QLabel("100"))
h1.addStretch(1)
h1.addWidget(QLabel("失败:"))
h1.addWidget(QLabel("0"))
right.addLayout(h1)
h2 = QHBoxLayout()
h2.addWidget(QLabel("线程:"))
h2.addWidget(QLineEdit("10"))
h2.addWidget(QPushButton("确定"))
right.addLayout(h2)
h3 = QHBoxLayout()
h3.addWidget(QLabel("卡数:"))
h3.addWidget(QLabel("100"))
h3.addStretch(1)
right.addLayout(h3)
h4 = QHBoxLayout()
h4.addWidget(QPushButton("加载"))
h4.addWidget(QPushButton("重置"))
right.addLayout(h4)
h5 = QHBoxLayout()
btn_start = QPushButton("开始")
btn_start.setFixedHeight(50)
h5.addWidget(btn_start)
btn_stop = QPushButton("停止")
btn_stop.setFixedHeight(50)
h5.addWidget(btn_stop)
right.addLayout(h5)
h6 = QHBoxLayout()
h6.addWidget(QLabel("运行记录"))
right.addLayout(h6)
h7 = QHBoxLayout()
log = QTextEdit()
h7.addWidget(log)
right.addLayout(h7)
right.addStretch(1)
r.setLayout(right)
layout.addWidget(r, 1)
self.setLayout(layout)
if __name__ == '__main__':
app = QApplication(sys.argv)
window = MainWindow()
window.show()
sys.exit(app.exec_())
22、图片下载函数
def downloadImg(img_url, file_path):
req = requests.get(url=img_url)
with open(file_path, 'wb') as f:
f.write(req.content)
downloadImg(r'http://s7.sinaimg.cn/mw690/005AsbCIzy7wpLTnkcC76&690',
r'D:\Python70个实战案例教程\实例67_Python爬取博客的所有文章并存为带目录的word文档\1.jpg')
23、Python之warnings模块忽略warning警告错误:
import warnings
warnings.filterwarnings("ignore") # 去除不影响程序运行的警告
24、字体纠正
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
25、
