import pandas as pd
import matplotlib.pyplot as plt
# 更改设计风格
plt.style.use("ggplot")
# 用户id、购买日期、购买产品数、购买金额
columns = ["user_id", "order_dt", "order_products", "order_amount"]
# 默认多个空格分隔
df = pd.read_table(r"D:\mycode\用pandas\data\CDNOW_master.txt", names=columns, sep="\s+")
print(df.head())
print("1,--------")
![]()
# 查看字段类型
print(df.info())
print("2,--------")
![]()
# 解析日期
df['order_dt'] = pd.to_datetime(df.order_dt, format="%Y%m%d")
df['month'] = df.order_dt.values.astype("datetime64[M]")
print(df)
print("3,--------")
![]()
print(df.info())
print("4,--------")
print(df.order_dt.values)
print("5,--------")
# 聚合月份
grouped_month = df.groupby("month")
# 每月消费总金额
order_month_amount = grouped_month.order_amount.sum()
print(order_month_amount.head())
print("6,----------")
# 展示折现图
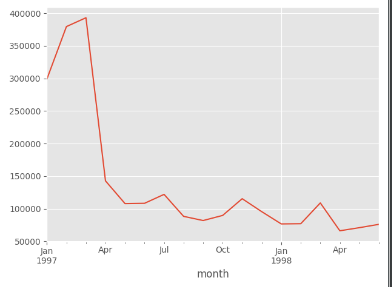
order_month_amount.plot()
plt.show()
![]()
# 由上图可知,消费金额在前三个月达到最高峰,后续消费额较为稳定,有轻微下降趋势
# 每月订单趋势
grouped_month.user_id.count().plot()
plt.show()
# 前三个月消费订单数在10000人左右,后续月份的平均消费人数则在2500人
# 每月消费产品数
grouped_month.order_products.sum().plot()
plt.show()
# 去重后每月消费人数
df.groupby("month").user_id.apply(lambda x: len(x.drop_duplicates())).plot()
plt.show()
# 每月消费人数低于每月消费次数,但差异不大,前三个月每月的消费人数在8000-10000之间,后续月份,平均消费人数在2000人不到
# 每月用户id
print(df.groupby(["month", "user_id"]).count().reset_index())
print("7,----------")
# 数据透视生成每月消费总额、商品总数、用户id总计
print(df.pivot_table(index="month", values=["order_products", "order_amount", "user_id"],
aggfunc={
"order_products": "sum",
"order_amount": "sum",
"user_id": "count"}).head())
print("8,-------")
# 用户个体消费分析
grouped_user = df.groupby("user_id")
print(grouped_user.sum().describe())
print("9,---------")
# 用户平均购买了7张CD,但是中位值只有3,说明小部分用户购买了大量的CD用户平均消费106元,中位值有43,
# 判断同上,有极值干扰
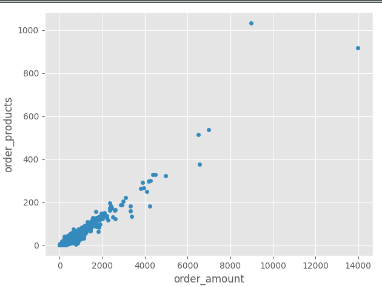
# 生成散点图
grouped_user.sum().plot.scatter(x="order_amount", y="order_products")
plt.show()
print("10,-------")
![]()
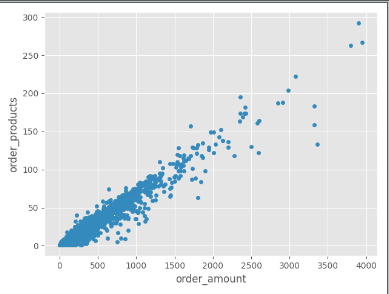
# 过滤散点图
grouped_user.sum().query("order_amount < 4000").plot.scatter(x="order_amount", y="order_products")
plt.show()
print("11,----")
![]()
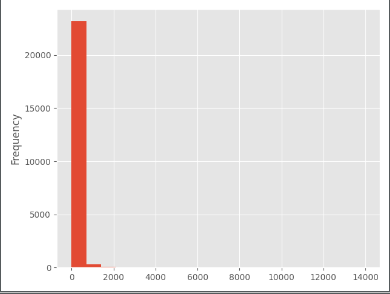
# 消费金额生成直方图
grouped_user.sum().order_amount.plot.hist(bins=20)
plt.show()
print("12,--------")
![]()
# 从直方图可知,用户消费金额,绝大部分呈现集中趋势,小部分异常值干扰了判断。可以使用过滤操作排除异常
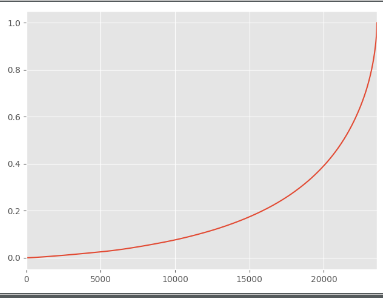
# 逐渐累加和除以总和占比图
user_cumsum = grouped_user.sum().sort_values("order_amount").apply(lambda x: x.cumsum() / x.sum())
print(user_cumsum)
user_cumsum.reset_index().order_amount.plot()
plt.show()
print("13,-------")
![]()
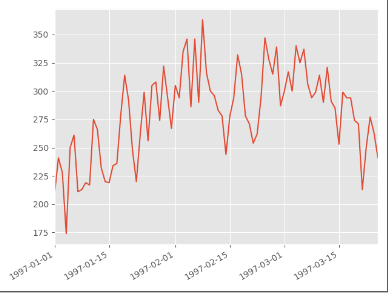
# 用户第一次购买分布图
grouped_user.min().order_dt.value_counts().plot()
plt.show()
print("14,-------")
![]()
# 用户第一次购买分布,集中在前三个月其中在2月11日至2月25日有一次剧烈的波动
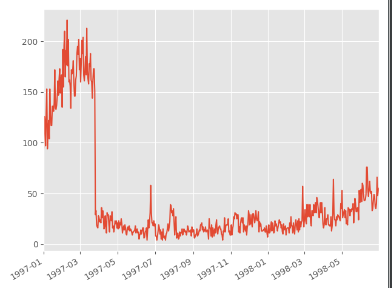
# 用户第一次消费分布图
grouped_user.max().order_dt.value_counts().plot()
plt.show()
![]()
# 用户最后一次购买的分布比第一次分布广,大部分最后一次购买,集中在前三个月,说明有很多用户购买了一次后就
# 不再进行购买,随着时间的递增,最后一次购买数也在递增,消费呈现流失上升的状况
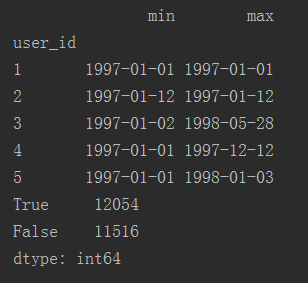
# 根据用户判断第一次消费和最后一次消费日期
user_life = grouped_user.order_dt.agg(["min", "max"])
print(user_life.head())
![]()
# 只消费一次计数
print((user_life["min"] == user_life["max"]).value_counts())

 浙公网安备 33010602011771号
浙公网安备 33010602011771号