MongoDB
服务端
MongDB:
1.默认监听端口是 27017 | Mysql:3306 | Redis:6379 orcal:1521 sql server:1433/5419/5413/5416
2.MongoDB 启动 "mongod"
指定 MongoDB 数据存储目录 --dbpath="d:/MongoData/db"
mongod --dbpath="d:/MongoData/db"
安装MongoDB数据库服务:
进入D:\mongodb\bin目录
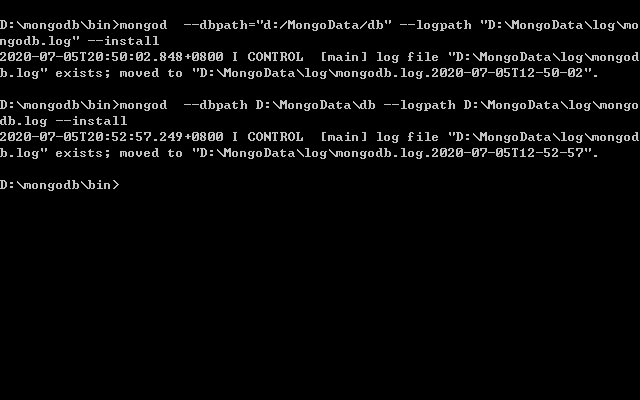
输入命令mongod --dbpath D:\MongoData\data --logpath D:\MongoData\log\mongodb.log --install
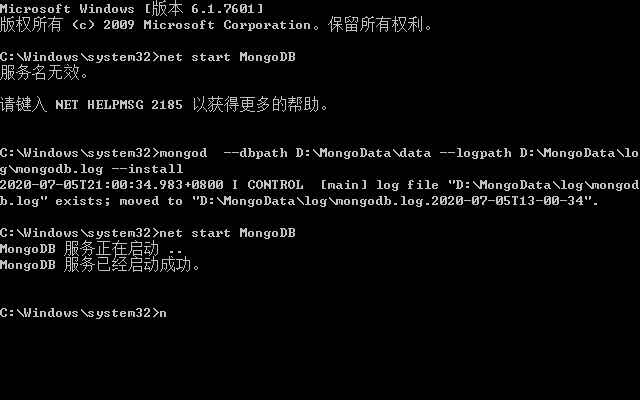
启动MongoDB服务:
net start MongoDB
介绍MongoDB:
NoSQL 文件型数据库 非关系型
自由
MySQL:
id name age sp wq
1 孙悟空 99999999 null 定海神针
2 沙悟净 9999999 唐僧同款项链 null
3.MongoDB 指令
1.show databases 查看本地磁盘中的数据库
2.use databasename 切换当前使用的数据库
3.db 查看当前使用的数据库
4.show tables 查看当前数据库磁盘中的表
4.MongoDB 数据 新建
use 不存在的数据库名 即 在内存中创建该数据库
db.不存在的表名 即 在数据库中创建该表(内存中)
使用了不存在的对象 即 创建该对象
5.增删改查
1.增
db.tablename.insert({})
db.user.insert({name:"沙悟净",age:66.666,hobby:[1,2,3,4,5]})
db.user.insert([{},{}])
官方推荐写法 in 3.2:
db.user.insertOne({}) 增加一条数据
db.user.insertMany([{},{}]) 批量增加数据
2.查询
db.tablename.find({查询条件}) 查询所有符合条件的数据
db.user.find({name:"沙悟净"}) 条件查询
db.user.find({name:"沙悟净",age:77}) 并列条件查询
db.user.findOne({}) 查询符合条件的第一条数据 返回JSON数据
$数据比较符
$lt 小于
$lte 小于等于
$gt 大于
$gte 大于等于
$eq 等于
$ne 不等于
3.改
db.tablename.update() 修改符合条件的第一条数据
# 所有MongoDB的修改全部基于 修改器
# $修改器 关键字
# $关键字:
db.user.updateOne({name:"太白金星","stdent.name":"MPy"},{$set:{"stdent.$.name":"Anyway"}})
db.user.updateOne({name:"太白金星",hobby:"喝酒"},{$set:{"hobby.$":"飙车"}})
$是用来存储符合当前Array条件元素的下标索引
当前Array - ["抽烟","喝酒","剃头"]
条件元素 - {hobby:"喝酒"}
当前Array - 第2个元素符合条件 它的下表索引是 1
当前$ 的值就是 1
如果使用".索引"的方式来操作Array "字段.索引位置"
官方推荐
db.user.updateOne({},{}) 修改符合条件的第一条数据
db.user.updateMany({},{}) 修改符合条件的所有数据
$set
db.user.update({age:66.666},{$set:{age:44}})
强制的将某字段值修改
db.user.update({name:"孙大圣"},{$set:{ag18e:18}})
如果该字段不存在即创建该字段并赋值
$unset
db.user.update({name:"孙大圣"},{$unset:{ag18e:1}})
删除字段
$inc
db.user.update({name:"孙大圣"},{$inc:{age:1}})
引用增加 先引用原有数据 在原有数据基础上增加
db.user.update({name:"孙大圣"},{$inc:{age:-1}})
减少
针对 Array List操作
$push == append
db.user.update({name:"孙大圣"},{$push:{hobby:"8"}})
在Array类型中增加数据在最末端增加
$pushAll == extends
db.user.update({name:"孙大圣"},{$pushAll:{hobby:[9,10,11,12]}})
在Array类型中增加数据在最末端增加多条数据
$pull == remove()
db.user.update({name:"孙大圣"},{$pull:{hobby:"8"}})
删除所有符合条件的数据
$pullAll
db.user.update({name:"孙大圣"},{$pushAll:{hobby:[9,10,11,12]}})
遍历删除所有符合条件的数据
$pop ~= pop() 删除Array中第一条或最后一条
db.user.update({name:"孙大圣"},{$pop:{hobby:-1}})
删除第一个数据
db.user.update({name:"孙大圣"},{$pop:{hobby:1}})
删除最后一个数据
4.删除
db.tablename.remove({查询条件}) 删除符合条件的所有数据
db.user.remove({}) 如果条件为空则删除所有数据 危险!
官方推荐的写法:
db.user.deleteOne({}) # 删除符合条件的第一条数据
db.user.deleteMany({}) # 删除所有符合条件的数据 危险! 如果条件为空则删除所有数据
6.MongoDB 的数据类型
ObjectID :Documents 自生成的 _id
String: 字符串,必须是utf-8
Boolean:布尔值,true 或者false (这里有坑哦~在我们大Python中 True False 首字母大写)
Integer:整数 (Int32 Int64 你们就知道有个Int就行了,一般我们用Int32)
Double:浮点数 (没有float类型,所有小数都是Double)
Arrays:数组或者列表,多个值存储到一个键 (list哦,大Python中的List哦)
Object:如果你学过Python的话,那么这个概念特别好理解,就是Python中的字典,这个数据类型就是字典
Null:空数据类型 , 一个特殊的概念,None Null
Timestamp:时间戳
Date:存储当前日期或时间unix时间格式 (我们一般不用这个Date类型,时间戳可以秒杀一切时间类型)
7.选取 跳过 排序
排序
db.user.find({}).sort({age:-1}) 倒序
db.user.find({}).sort({age:1}) 正序
跳过
db.user.find({}).skip(跳过条目) 跳过
选取
db.user.find({}).limit(300) 选取300条数据
如果数据条目小于300 则全部查询
大于300 则只查询300条
db.user.find({}).sort({age:-1}).skip(1).limit(2)
当3个关键全部出现在一条语句中时,先排序 再跳过 再选取
分页(每页2条数据):
count = 2
page = 1
skip(page-1*count)
db.user.find({}).sort({age:-1}).skip(page-1*count).limit(count)
客户端:
非关系型数据库 - NoSQL 文件型数据库
3306 MySQL
6379 Redis
1433 MSSQL - 微软的sqlserver
DB2 - IBM
ORCL - 甲骨文
MySQL - 甲骨文
MSSQL - 微软
Sybase - MSSQL鼻祖
MongoDB 启动
mongod 启动MongoDB服务 默认端口 27017
-- 默认数据库文件的存放地址 C:/data/db or /data/db
-- dbpath="D:/data/db"
mongo 启动客户端
-- 默认连接 localhost:27017
MongoDB 指令
show databases 查看当前数据库服务器磁盘中的数据库
use dbname 使用dbname数据库 / 在内存中创建dbname数据库 只有在dbname不存在时才会创建
db 查看当前使用的数据库 / 当前使用的数据库变量
show tables 查看当前数据库磁盘中的数据表
db.tablename 创建或使用tablename数据表
MongoDB 增删改查
1.增:
db.tablename.insert({name:123}) 官方认可但不推荐
res = db.tablename.insertOne({name:123}) # 增加一条数据 inserted_id
res = db.tablename.insertMany([{name:123},{name:456}]) # 增加多条数据 inserted_ids
2.删除数据:
db.tablename.remove({查询条件}) #官方认可但不推荐
db.tablename.deleteOne({查询条件}) # 删除符合条件的第一条数据 _id
db.tablename.deleteMany({查询条件})# 删除所有符合条件的数据
3.查询数据:
db.tablename.find({查询条件}) # 查询所有符合条件的数据
db.tablename.findOne({查询条件}) # 查询符合条件的第一条数据
并列条件查询 and
db.tablename.find({查询条件1,查询条件2})
$比较符:
$lt <
$lte <=
$gt >
$gte >=
$eq ==
$ne !=
4.修改数据
db.tablename.update({查询条件},{$修改器:{修改值}}) # 官方认可但不推荐
db.tablename.updateOne({查询条件},{$修改器:{修改值}}) # 修改符合条件的第一条数据
db.tablename.updateMany({查询条件},{$修改器:{修改值}}) # 修改所有符合条件的数据
$修改器 字段:
$set 强制修改 创建字段
$unset 删除字段 {字段:1}
$inc 引用增加 {$inc:{age:1/-1}} 只能增加不能减少
$修改器 Array List
$push == append #追加数据 {$push:{hobby:6}}
$pull == remove #删除元素 {$pull:{hobby:6}}
$pop ~= pop #删除第一个(1)或者最后一个元素(-1) {$pop:{hobby:1/-1}}
$pushAll == extends #追加批量元素 {$pushAll:{hobby:[4,5,6,7]}}
$pullAll # 批量删除元素 {$pullAll:{hobby:[4,5,6,7]}}
5.sort skip limit
逻辑顺序
先排序 - 再跳过 - 最后选取
# 程序 > OS-操作系统 > 内存
内存 - 空间(大箱子)
1 前言
MongoDB 是一个基于分布式文件存储的开源数据库系统。
MongoDB 将数据存储为一个文档,数据结构由键值(key=>value)对组成。MongoDB 文档类似于 JSON 对象。字段值可以包含其他文档,数组及文档数组。
2 安装(mac)
- 安装 homebrew
- 使用 brew 安装 mongodb
brew install mongodb- 可视化工具 Robomongo
3 mongodb 启动与连接(mac)
3.1 服务端启动
3.1.1 启动步骤
在要启动的目录下新建一个目录(如:data)
mkdir data命令行中输入(--dbpath 参数指定数据库路径)
mongod --dbpath='./data'如果出现 waiting for connections on port 27017 就表示启动成功。
注意:这个命令窗体绝对不能关,关闭这个窗口就相当于停止了 mongodb 服务。
3.1.2 mongod 启动命令 mongod 参数说明

3.2 客户端启动
命令行输入
mongo也可以设置 host
mongo --host 127.0.0.14 MongoDB基本概念
数据库MongoDB的单个实例可以容纳多个独立的数据库,比如一个学生管理系统就可以对应一个数据库实例。集合数据库是由集合组成的,一个集合用来表示一个实体,如学生集合。文档集合是由文档组成的,一个文档表示一条记录,比如一位同学张三就是一个文档
对应关系如下图:

5 数据库操作
5.1 查看所有数据库
show dbs返回如下:
admin 0.000GBbook 0.000GBleave 0.000GBlocal 0.000GBpage 0.000GBschool 0.000GBstudents 0.000GB5.2 使用数据库
实例切换到 school 数据库下:
use school返回如下:
switched to db school注:如果此数据库存在,则切换到此数据库下,如果此数据库还不存在也可以切过来,我们刚创建的数据库 school 如果不在列表内,要显示它,我们需要向 school 数据库插入一些数据
db.school.insert({name:'为民小学',age:10});5.3 查看当前使用的数据库
db 或 db.getName()5.4 删除数据库
db.dropDatabase()返回如下:
{ "dropped" : "school", "ok" : 1 }6 集合操作
6.1 查看集合帮助
db.school.help()返回如下:
BCollection help db.school.find().help() - show DBCursor help db.school.bulkWrite( operations, <optional params> ) - bulk execute write ...6.2 查看数据库下的集合
show collections返回如下:
grade1grade26.3 创建集合
- 创建一个空集合(
db.createCollection(collection_Name))
db.createCollection('grade3')返回如下:
{ "ok" : 1 }- 创建集合并插入一个文档(
db.collection_Name.insert(document))
db.grade1.insert({name: 'Lily', age: 8})返回如下:
WriteResult({ "nInserted" : 1 })7 文档操作
7.1 插入文档
insert
db.collection_name.insert(document)
db.grade1.insert({name: 'Tom', age: 9})每当插入一条新文档的时候 mongodb 会自动为此文档生成一个 _id 属性,_id一定是唯一的,用来唯一标识一个文档 _id 也可以直接指定,但如果数据库中此集合下已经有此 _id 的话插入会失败。
{ "_id" : ObjectId("5addbfbb163098017a6a72ed"), "name" : "Tom", "age" : 9.0}save
db.collection_name.save(document)
如果不指定 _id 字段 save() 方法类似于 insert() 方法。如果指定 _id 字段,则会更新该 _id 的数据。
// insertdb.grade1.insert({_id: '1',name: 'Han Meimei', age: 8})// WriteResult({ "nInserted" : 1 })// 存在{_id:1},则更新 _id为1的documentdb.grade1.save({_id: '1',name: 'Han Meimei', age: 9})// WriteResult({ "nMatched" : 1, "nUpserted" : 0, "nModified" : 1 })// 不存在{_id:2},则插入一条新文档db.grade1.save({_id: '2',name: 'Han Meimei', age: 9})// WriteResult({ "nMatched" : 0, "nUpserted" : 1, "nModified" : 0, "_id" : "2" })执行脚本插入
mongo exc_js/1.js> load exc_js/1.js7.2 更新文档
7.2.1 语法 & 参数说明
db.collection.update( <query>, <updateObj>, { upsert: <boolean>, multi: <boolean> })query查询条件,指定要更新符合哪些条件的文档update更新后的对象或指定一些更新的操作符$set直接指定更新后的值$inc在原基础上累加
upsert可选,这个参数的意思是,如果不存在符合条件的记录时是否插入updateObj. 默认是false,不插入。multi可选,mongodb 默认只更新找到的第一条记录,如果这个参数为true,就更新所有符合条件的记录。
7.2.2 操作符
(1) $inc
{ $inc: { <field1>: <amount1>, <field2>: <amount2>, ... } }在原基础上累加(increment)
// 给 {name: 'Tom'} 的文档的age累加 10db.grade1.update({name: 'Tom'}, {$inc: {age:10}})// WriteResult({ "nMatched" : 1, "nUpserted" : 0, "nModified" : 1 })(2) $push
{ $push: { <field1>: <value1>, ... } }向数组中添加元素
db.grade1.update({name:'Tom'}, {$push: {'hobby':'reading'} })// WriteResult({ "nMatched" : 1, "nUpserted" : 0, "nModified" : 1 })// { "_id" : ObjectId("5addbfbb163098017a6a72ed"), "name" : "Tom", "hobby" : [ "reading" ] }// 不会覆盖已有的db.grade1.update({name:'Tom'}, {$push: {'hobby':'reading'} })// WriteResult({ "nMatched" : 1, "nUpserted" : 0, "nModified" : 1 })// { "_id" : ObjectId("5addbfbb163098017a6a72ed"), "name" : "Tom", "hobby" : [ "reading", "reading" ] }(3) $addToSet
{ $addToSet: { <field1>: <value1>, ... } }- 给数组添加或者设置一个值,
- 有 - do nothing,没有 - 添加
// /第一次没有 hugedb.grade1.update({_id:3}, {$addToSet: {friends:'huge'}})// WriteResult({ "nMatched" : 1, "nUpserted" : 0, "nModified" : 1 })// 第二次 有 hugedb.grade1.update({_id:3}, {$addToSet: {friends:'huge'}})// WriteResult({ "nMatched" : 1, "nUpserted" : 0, "nModified" : 0 })(4) $pop
{ $pop: { <field>: <-1 | 1>, ... } }- 删除数组的第一个或者最后一个元素。
- 传入
1删除最后一个元素 - 传入
-1删除第一个元素
db.grade1.update({_id:3}, {$pop:{friends: 1}})// WriteResult({ "nMatched" : 1, "nUpserted" : 0, "nModified" : 1 })db.grade1.update({_id:3}, {$pop:{friends: -1}})// WriteResult({ "nMatched" : 1, "nUpserted" : 0, "nModified" : 1 })(5) $each
{ $addToSet: { <field>: { $each: [ <value1>, <value2> ... ] } } }- Use with the $addToSet operator to add multiple values to an array if the values do not exist in the .
db.grade1.update({_id:3}, {$addToSet:{friends:{$each: ['huangbo','zhangyixing']}}})//WriteResult({ "nMatched" : 1, "nUpserted" : 0, "nModified" : 1 })// 已经有的时候就不会再添加了db.grade1.update({_id:3}, {$addToSet:{friends:{$each: ['huangbo','zhangyixing']}}})//WriteResult({ "nMatched" : 1, "nUpserted" : 0, "nModified" : 0 }){ $push: { <field>: { $each: [ <value1>, <value2> ... ] } } }Use with the $push operator to append multiple values to an array .
db.grade1.update({_id:3}, {$push:{friends:{$each: ['huangbo','zhangyixing']}}})// WriteResult({ "nMatched" : 1, "nUpserted" : 0, "nModified" : 1 })在 $addToSet 中使用时,若有则忽略,若没有则添加。在 $push 中使用时,不管有没有都会添加。
(6) $ne
{field: {$ne: value} }not equal
// 给 name为'Han Meimei' && hobby中不等于'reading' && _id不等于'2'的文档 的hobby 属性 添加一个 'drinking'db.grade1.update({name: 'Han Meimei', hobby:{$ne:'reading'}, _id: {$ne:'2'}}, {$push: {hobby: 'drinking'}})// WriteResult({ "nMatched" : 1, "nUpserted" : 0, "nModified" : 1 })(7)$set
{ $set: { <field1>: <value1>, ... } }- 设置字段的第一层的值(Set Top-Level Fields)
- 设置嵌套字段的值 (Set Fields in Embedded Documents)
- 修改指定索引元素
/*原来的数据:{_id:3, info:{id: '11'}, friends:['liudehua', 'zhourunfa']}*//*设置字段的第一层的值(Set Top-Level Fields)*/ db.grade1.update({_id:3}, {$set:{"info11":{id:'11'}}})// WriteResult({ "nMatched" : 1, "nUpserted" : 0, "nModified" : 1 })/*设置嵌套字段的值 (Set Fields in Embedded Documents)*/db.grade1.update({_id:3}, {$set:{"info.id":'22'}})// WriteResult({ "nMatched" : 1, "nUpserted" : 0, "nModified" : 1 })/*修改指定索引元素*/db.grade1.update({_id:3}, {$set:{"friends.1":'zhangmanyu'}})// WriteResult({ "nMatched" : 1, "nUpserted" : 0, "nModified" : 0 })(8) $unset
{ $unset: { <field1>: "", ... } }删除指定的键
// 把 {name: 'Tom'} 的文档中的 age 键给删除掉db.grade1.update({name: 'Tom'}, {$unset:{'age':''}})// WriteResult({ "nMatched" : 1, "nUpserted" : 0, "nModified" : 1 })/* { "_id" : ObjectId("5addbfbb163098017a6a72ed"), "name" : "Tom"}*/7.3 删除文档
remove方法是用来移除集合中的数据
语法
db.collection.remove( <query>, { justOne: <boolean> })参数说明
query :(可选)删除的文档的条件。justOne : (可选)如果设为 true 或 1,则只删除匹配到的多个文档中的第一个。默认为 true/*{justOne:true} 值删除匹配到的第一条文档*/db.grade1.remove({'name': 'Han Meimei'}, {justOne: true})// WriteResult({ "nRemoved" : 1 })/*删除匹配到的所有文档*/db.grade1.remove({'name': 'Han Meimei'})// WriteResult({ "nRemoved" : 2 })7.4 查询文档
7.4.1
语法
db.collection_name.find(query, projection);参数
query - 使用查询操作符指定选择过滤器projection - 指定配到到的文档中的返回的字段。/*projection*/{ field1: <value>, field2: <value> ... }/*value:*/1 or true: 在返回的文档中包含这个字段0 or false:在返回的文档中排除这个字段 _id 字段默认一直返回,除非手动将 _id 字段设置为 0 或 false
举个栗子
//查询grade1下所有的文档db.grade1.find()7.4.2 findOne()
- 只返回匹配到的第一条文档
7.4.3 查询操作符
(1) $in
- Matches any of the values specified in an array.
- 在数组范围内的
//原始数据():{ "_id" : 1, "name" : "Tom1", "age" : 9 }{ "_id" : 2, "name" : "Tom2", "age" : 15 }{ "_id" : 3, "name" : "Tom3", "age" : 11 }db.grade1.find({age:{$in:[9,11]}})// { "_id" : 1, "name" : "Tom1", "age" : 9 }// { "_id" : 3, "name" : "Tom3", "age" : 11 }(2) $nin
- Matches none of the values specified in an array.
db.grade1.find({age:{$nin:[9,11]}})// { "_id" : 2, "name" : "Tom2", "age" : 15 }(3) $not
- Inverts the effect of a query expression and returns documents that do not match the query expression.
db.grade1.find({age:{$not:{$lt:11}}})//{ "_id" : 2, "name" : "Tom2", "age" : 15 }//{ "_id" : 3, "name" : "Tom3", "age" : 11 }(4) $gt
- Matches values that are greater than a specified value.
- 大于
(5) $gte
- Matches values that are greater than or equal to a specified value.
- 大于等于
(6) $lt
- Matches values that are less than a specified value.
- 小于
(7) $lte
- Matches values that are less than or equal to a specified value.
- 小于等于
(8)$ne
- Matches all values that are not equal to a specified value.
- 不等于
db.grade1.find({age:{$ne:9}})// { "_id" : 2, "name" : "Tom2", "age" : 15 }// { "_id" : 3, "name" : "Tom3", "age" : 11 }7.4.4 数组的用法
// 原始数据{ "_id" : 1, "name" : "Tom1", "age" : 9, "friends" : [ "Lily", "Jobs", "Lucy", "Zhang San" ] }{ "_id" : 2, "name" : "Tom2", "age" : 15, "friends" : [ "Zhange San", "Li Si" ] }{ "_id" : 3, "name" : "Tom3", "age" : 11, "friends" : [ "Zhange San", "Lily" ] }db.grade1.find({"friends" : [ "Lily", "Jobs", "Lucy", "Zhang San" ]})// { "_id" : 1, "name" : "Tom1", "age" : 9, "friends" : [ "Lily", "Jobs", "Lucy", "Zhang San" ] }db.grade1.find({"friends" : [ "Lily" ]})// 空// $alldb.grade1.find({"friends" :{$all: ["Zhang San"]}})// { "_id" : 1, "name" : "Tom1", "age" : 9, "friends" : [ "Lily", "Jobs", "Lucy", "Zhang San" ] }// $indb.grade1.find({"friends" :{$in: ["Zhang San"]}}){ "_id" : 1, "name" : "Tom1", "age" : 9, "friends" : [ "Lily", "Jobs", "Lucy", "Zhang San" ] }// $sizedb.grade1.find({"friends" :{$size:4}})//{ "_id" : 1, "name" : "Tom1", "age" : 9, "friends" : [ "Lily", "Jobs", "Lucy", "Zhang San" ] }// $slicedb.collection.find( { field: value }, { array: {$slice: count } } );> db.grade1.find({"friends" :{$size:4}}, {"friends":{$slice:2}})//{ "_id" : 1, "name" : "Tom1", "age" : 9, "friends" : [ "Lily", "Jobs" ] }7.4.5 $where
$where可以接收两种参数传递给查询系统,一种是包含 JavaScript 表达式的字符串,另外一种是 JavaScript 函数。$where非常灵活,但是它需要数据库集合中的每一个文档中处理这个 JavaScript 表达式或者 JavaScript 函数,所以会比较慢。- 在 JavaScript 表达式或者 JavaScript 函数中引用文档的时候,可是使用
this或者obj。
// 数据库数据{ "_id" : 1, "name" : "Tom1", "age" : 9, "friends" : [ "Lily", "Jobs", "Lucy", "Zhang San" ] }{ "_id" : 2, "name" : "Tom2", "age" : 15, "friends" : [ "Zhange San", "Li Si" ] }{ "_id" : 3, "name" : "Tom3", "age" : 11, "friends" : [ "Zhange San", "Lily" ] }// JS表达式的字符串> db.grade1.find({$where:'this.name == "Tom1"'})//{ "_id" : 1, "name" : "Tom1", "age" : 9, "friends" : [ "Lily", "Jobs", "Lucy", "Zhang San" ] }// 函数> db.grade1.find({$where: function(){return this.age == 9}})// { "_id" : 1, "name" : "Tom1", "age" : 9, "friends" : [ "Lily", "Jobs", "Lucy", "Zhang San" ] }7.4.6 Cursor Methods
这些方法改变了执行基础查询方式。
包括 cursor.forEach()、cursor.map()、cursor.limit()、cursor.size()、cursor.count() 等。
// forEach举例> var result = db.grade1.find({$where: function(){return this.age >= 9}});> result.forEach(elem => printjson(elem))/*{ "_id" : 1, "name" : "Tom1", "age" : 9, "friends" : [ "Lily", "Jobs", "Lucy", "Zhang San" ]}{ "_id" : 2, "name" : "Tom2", "age" : 15, "friends" : [ "Zhange San", "Li Si" ]}{ "_id" : 3, "name" : "Tom3", "age" : 11, "friends" : [ "Zhange San", "Lily" ]}*/8 条件操作符
8.1 条件操作符
$gt- 大于$gte- 大于等于$lt- 小于$lte- 小于等于
// 大于等于db.grade1.find({age:{$gte:9}})/*{ "_id" : 1, "name" : "Tom1", "age" : 9, "friends" : [ "Lily", "Jobs", "Lucy", "Zhang San" ] }{ "_id" : 2, "name" : "Tom2", "age" : 15, "friends" : [ "Zhange San", "Li Si" ] }{ "_id" : 3, "name" : "Tom3", "age" : 11, "friends" : [ "Zhange San", "Lily" ] }*/// 大于等于9 并且 小于等于13db.grade1.find({age:{$gte:9}, age: {$lte:13}})/*{ "_id" : 1, "name" : "Tom1", "age" : 9, "friends" : [ "Lily", "Jobs", "Lucy", "Zhang San" ] }{ "_id" : 3, "name" : "Tom3", "age" : 11, "friends" : [ "Zhange San", "Lily" ] }*/8.2 使用_id进行查询
//原始数据{ "_id" : ObjectId("5ae1b6e3e4366d57f3307239"), "name" : "Tom4" }> db.grade1.find({_id: '5ae1b6e3e4366d57f3307239'}).count()// 0> db.grade1.find({_id:ObjectId('5ae1b6e3e4366d57f3307239')}).count()// 1count() 查询结果的条数
8.3 正则匹配
db.collection.find({key:/value/})
// name是以`T`开头的数据db.grade1.find({name: /^T/})/*{ "_id" : 1, "name" : "Tom1", "age" : 9, "friends" : [ "Lily", "Jobs", "Lucy", "Zhang San" ] }{ "_id" : 2, "name" : "Tom2", "age" : 15, "friends" : [ "Zhange San", "Li Si" ] }{ "_id" : 3, "name" : "Tom3", "age" : 11, "friends" : [ "Zhange San", "Lily" ] }{ "_id" : ObjectId("5ae1b6e3e4366d57f3307239"), "name" : "Tom4" }*/9 与和或
9.1 and
db.collection_name.find({field1: value1, field2:value2})
//原始数据{ "_id" : 1, "name" : "Tom1", "age" : 9, "friends" : [ "Lily", "Jobs", "Lucy", "Zhang San" ] }{ "_id" : 2, "name" : "Tom2", "age" : 15, "friends" : [ "Zhange San", "Li Si" ] }{ "_id" : 3, "name" : "Tom3", "age" : 11, "friends" : [ "Zhange San", "Lily" ] }// and name是以‘T’开头 并且 age是9 的数据> db.grade1.find({name: /^T/, age: 9})// { "_id" : 1, "name" : "Tom1", "age" : 9, "friends" : [ "Lily", "Jobs", "Lucy", "Zhang San" ] }9.2 or
db.collection_name.find({ $or: [{key1: value1}, {key2:value2} ] })
// name 是Tom1 或者 age是11 的数据> db.grade1.find({$or:[{name: 'Tom1'}, {age: 11}]})/*{ "_id" : 1, "name" : "Tom1", "age" : 9, "friends" : [ "Lily", "Jobs", "Lucy", "Zhang San" ] }{ "_id" : 3, "name" : "Tom3", "age" : 11, "friends" : [ "Zhange San", "Lily" ] }*/9.3 and 和 all 联合使用
> db.grade1.find({age: 9,$or:[{name: 'Tom1'}, {age: 11}]})/*{ "_id" : 1, "name" : "Tom1", "age" : 9, "friends" : [ "Lily", "Jobs", "Lucy", "Zhang San" ] }*/10 分页查询
10.1 limit
读取指定数量的数据记录 语法
db.collectoin_name.find().limit(number)
10.2 skip
跳过指定数量的数据
db.collectoin_name.find().skip(number)
10.3 sort
通过参数指定排序的字段,并使用 1 和 -1 来指定排序的方式,其中 1 为升序排列,而 -1 是用于降序排列。
db.collectoin_name.find().sort({field:1})
db.collectoin_name.find().sort({field:-1})
10.4 分页
// 原始数据为 1 2 3 4 5 6 7 8 9> var pageIndex = 3;> var pageSize = 3;> var res = db.grade1.find({}).skip((pageIndex - 1) * pageSize).limit(pageSize).sort({username: 1});> res/*{ "_id" : ObjectId("5ae1cbc609f3ac9a41442546"), "username" : "Lily_7", "password" : 7 }{ "_id" : ObjectId("5ae1cbc609f3ac9a41442547"), "username" : "Lily_8", "password" : 8 }{ "_id" : ObjectId("5ae1cbc609f3ac9a41442548"), "username" : "Lily_9", "password" : 9 }*/var res1 = db.grade1.find().skip((pageIndex - 1) * pageSize).limit(pageSize).sort({username: -1});/*{ "_id" : ObjectId("5ae1cbc609f3ac9a41442542"), "username" : "Lily_3", "password" : 3 }{ "_id" : ObjectId("5ae1cbc609f3ac9a41442541"), "username" : "Lily_2", "password" : 2 }{ "_id" : ObjectId("5ae1cbc609f3ac9a41442540"), "username" : "Lily_1", "password" : 1 }*/没有先后顺序
11 ObjectId 构成
之前我们使用 MySQL 等关系型数据库时,主键都是设置成自增的。但在分布式环境下,这种方法就不可行了,会产生冲突。为此,MongoDB 采用了一个称之为 ObjectId 的类型来做主键。ObjectId 是一个12字节的 BSON 类型字符串。按照字节顺序,一次代表:
- 4字节:UNIX 时间戳
- 3字节:表示运行 MongoDB 的机器
- 2字节:表示生成此 _id 的进程
- 3字节:由一个随机数开始的计数器生成的值
