
#1、导入
# import cal,time
#2、引用
# from cal import add
# from cal import sub
#3、飘红不代表错误原因是pycharm检测不出来
#4、*星代表一切(不推荐:
# from cal import *
# print(add(3,5))
# print(sub(3,5))
# def add(x,y):
# return x + y + 100
# from cal import *
# print(add(3,6))
#5、
# from my_module import cal
# import xxxx
# print(cal.add(1,3))
#6、sys里面放的是执行文件的路径
# import sys
# print(sys.path)
#7、bin代表程序入口
#8、main代表逻辑相关主函数
#9、与功能相关的放在其他文件里面
#10、通过main文件执行cal里面的add
from my_module import main
main.run()
#12、__name__的作用是用于测试和不想被其他人调用
from my_module import main
def looger():
pass
if __name__ == '__main__':
main.run
#13、
Python标准库模块
time时间模块
#1、time.time打印当前系统时间并转做浮点表达式--时间戳(1970-当前时间经过的秒数、1970Unix诞辰
import time
print(time.time())
#2、time.sleep休眠
print(time.sleep(1))
#3、对象化时间
print(time.localtime())
t = time.localtime()
print(t.tm_year) #打印年
print(t.tm_mon)
print(time.gmtime()) #时区
#4、结构化的时间转换成时间戳
print(time.mktime(time.localtime()))
#5、将结构化时间转成字符串时间
print("当前时间是",time.strftime("%Y-%m-%d %X",time.localtime()))
#6、将字符串时间转化成结构化时间
print(time.strptime("2016:12:24:17:50:36","%Y:%m:%d:%X"))
#7、
print(time.asctime())
#8、
print(time.ctime())
#9、
import datetime
print(datetime.datetime.now())
random随机模块
import random
#1、
ret = random.random()
print(ret)
#2、
ret = random.randint(1,6)
print(ret)
#3、
ret = random.randrange(1,3)
print(ret)
#4、
ret = random.choice([11,22,33])
print(ret)
#5、
ret = random.sample([11,22,33,44,55],2)
print(ret)
#6、
ret = random.uniform(1,4)
print(ret)
#7、
ret = [1,2,3,4,5]
random.shuffle(ret)
print(ret)
#8、
def v_code():
ret = ""
for i in range(5):
num = random.randint(0,9)
alf = chr(random.randint(65,122))
s = str(random.choice([num,alf]))
ret += s
return ret
print(v_code())
sys模块
sys.path.append()
os模块
#1、显示当前目录
import os
# print(os.getcwd())
#2、显示当前文件
# os.chdir("test1")
#3、
# print(os.getcwd())
#4、新建
# os.makedirs("dirname1/dirname2")
# print(os.getcwd())
#5、删除
# os.removedirs("python_s3/dirname1/dirname2")
#6、清单
print(os.listdir())
#7、获取文件目录信息
print(os.stat("sss.py"))
#8、s分隔符
print(os.sep)
#9、分割文件 路径字符串
print(os.pathsep)
#10、name是当前文件使用的平台
print(os.name)
#11、system显示当前目录的文件信息
print(os.system("dir"))
#12、
print(os.path.split(r"C:\Users\zd\Desktop\python_s3\day22\sss.py"))
#13、dirname
print(os.path.dirname(r"C:\Users\zd\Desktop\python_s3\day22\sss.py"))
#14、basename
print(os.path.basename(r"C:\Users\zd\Desktop\python_s3\day22\sss.py"))
#15、exists判断路径是否存在
print(os.path.exists(r"C:\Users\zd\Desktop\python_s3\day22\sss.py"))
#16、isabs判断绝对路径
print(os.path.isabs(r"C:\Users\zd\Desktop\python_s3\day22\sss.py"))
#17、判断path是否存在一个文件isfile
print(os.path.isfile(r"C:\Users\zd\Desktop\python_s3\day22\sss.py"))
#18、isdir判断path存在一个目录
print(os.path.isdir(r"C:\Users\zd\Desktop\python_s3\day22\sss.py"))
#19、join将路径进行拼接
# a = "C:\users\zd"
# b = "python_s3\day22\sss.py"
# print(os.path.join())
#20、getatime最后存取时间
print(os.path.getatime(r"C:\Users\zd\Desktop\python_s3\day22\sss.py"))
#21、最后修改时间
print(os.path.getmtime(r"C:\Users\zd\Desktop\python_s3\day22\sss.py"))
#22、
sys模块
import sys
#1、命令行参数列表、
print(sys.argv)
#2、version获取Python解释器版本信息
print(sys.version)
#3、返回系统平台名称
print(sys.platform)
#4、
import time
for i in range(10):
sys.stdout.write("#")
time.sleep(0.1)
sys.stdout.flush()
#5、
json&pickle模块
#1、
dic = '{"name":"alex"}'
f = open("hello","w")
f.write(dic)
#2、json模块字符串必须双引dumps
import json
dic = {"name":"alex"}
i = 8
s = 'hello'
l = [11,22]
data = json.dumps(l)
print(l)
print(type(data))
#3、loads
# f_read = open("new_hello","r")
# data = json.loads(f_read.read())
# print(data)
# print(type(data))
#4、
import json
with open("json_test","r") as f:
data = f.read()
data = json.loads(data)
print(data["name"])
#5、pickle转化后的类型 是bytes字节类型
import pickle
dic = {"name":"alvin","age":23,"sex":"male"}
print(type(dic))
j = pickle.dumps(dic)
print(j)
print(type(j)) #
f = open("序列化对象_pickle","wb") #w是写入str、wb是写入bytes、j是bytes
f.write(j)
#6、
shelve模块
#1、将字典放入文本
import shelve
f = shelve.open(r"shelve")
f["stul_info"] = {"name":"alex","age":"18"}
f.close()
# dic = {}
# dic["name"] = "alvin"
# dic["info"] = {"name":"alex"}
#2、
XML模块
#1、用getroot打印根节点
import xml.etree.ElementTree as ET #as后面的ET代指前面模块的名字
tree = ET.parse("xml_lesson.xml") #用ET里面的parse方法并赋予对象tree、
root = tree.getroot()
print(root.tag)
#2、遍历xml文档
for i in root:
print(i)
#3、遍历属性tag
for i in root:
print(i.tag)
#4、双层循环遍历
for i in root:
for j in i:
print(j.tag)
#5、看值attrib属性组成键值对
for i in root :
print(i.attrib)
#6、遍历打印子元素
for i in root:
for j in i:
print(j.attrib)
#7、text
for i in root:
for j in i:
print(j.text)
re正则模块
import re
#1、找到以a开头和l结尾的
s = "hellocdalexfdsfdsfdsf"
print(s.find("alex"))
#2、371481198506143635(alex身份证号)
print(re.findall("\d+","alex22ccsd45vcxvcx767bvcbcv876"))
#3、findall(匹配规则+内容)
print(re.findall("alex","afdsvcxvfsg"))
#4、a..x(代表以a开头中间任意两个字符以x结尾的
print(re.findall("a..x","affxcvcvsdf"))
#5、^尖角号代表以什么开头
print(re.findall("^a..c","acxcxacxcx"))
#6、$代表以什么结尾
print(re.findall("a..x$","acxvfsdfsdarrx"))
#7、*代表0到无穷次
print(re.findall("d*","dfdsfdsfdsadsadddddddddvcxvxc"))
#8、?
#9、{}为范围取
#10、[]中括号字符集
#11、(小括号
print(re.findall("\([^()]*\)","12 + (34 * 6 + 2 - 5*(2-1)"))
#12\d
#13\D
#14
#14、|管道符代表或的意思
print(re.findall(r"ka|b","sdjkbsf"))
print(re.findall(r"ka|b","sdjkabsf"))
print(re.findall(r"ka|bc","sdjkabcsf"))
#15、d+
print(re.sub("\d+","A","fdsfdsfjaskd4324vcxvxc"))
#16、加参数
print(re.subn("\d","A","jackcxcvsdfd4343543543vcxvxcavcxvxd543534fdfds",8))
#17、
loging日志模块
#1、日志级别
import logging
#2、增加参数
# logging.basicConfig(
# level=logging.DEBUG,
# filename="logger.log",
# filename="w" #模式是追加
# )
# logging.debug("debug message")
# logging.info("info message")
# logging.warning("warning message")
# logging.error("error message")
# logging.critical("critical message")
#3、
import configparser
config = configparser.ConfigParser() #用configparser模块里面的ConfigParser类生成config对象
config["DEFAULT"] = {"ServerAliveInterval" : "45", #键值对
"Compression": "yes",
"CompressionLevel" : "9"}
config["bitbucket.org"] = {}
config["bitbucket.org"]["User"] = "hg"
config["topsecret.server.com"] = {}
topsecret = config["topsecret.server.com"]
topsecret["Host Port"] = "50022"
topsecret["ForwardXll"] = "no"
config["DEFAULT"]["ForwardXll"] = "yes"
with open("example.ini","w") as configfile:
config.write(configfile)
hashlib哈希模块
#1、摘要算法、hash算法
import hashlib
obj = hashlib.md5("dsfdsfdsfds".encode("utf8")) #fdsfsdfds指的是加颜
obj.update("admin".encode("utf-8"))
print(obj.hexdigest())
socketserver模块


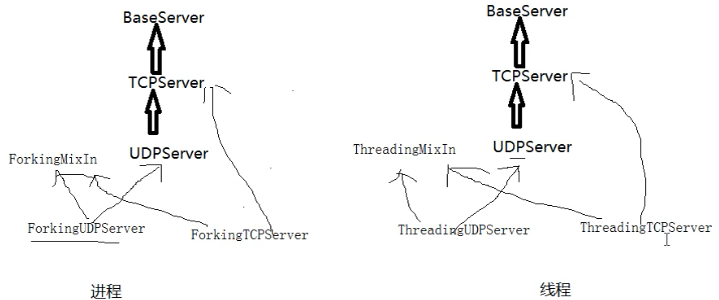
server类:处理链接包含:BaseServer、TcpServer、UdpServer、UnixStreamServer、UnixDatagramServer。
request类:处理通信包含BaseRequestHandler、StreamRequestHandler、DatagramRequestHandler。
对于tcp来说
self.request=conn
对于udp来说
self.request=(client_data_bytes,udp的套接字对象)
socketserver源码分析udp版服务端代码:
import socketserver
class MyServer(socketserver.BaseRequestHandler):
def handle(self):
print(self.request)
print("收到客户端的消息是",self.request[0])
self.request[1].sendto(self.request[0].upper(),self.client_address)
if __name__ == '__main__':
s = socketserver.ThreadingUDPServer(("127.0.0.1",8000),MyServer)
s.serve_forever()
socketserver源码分析udp版客户端1代码:
from socket import *
ip_port = ("127.0.0.1",8000)
buffer_size = 1024
udp_client = socket(AF_INET,SOCK_DGRAM)
while True:
msg = input(">>:").strip()
udp_client.sendto(msg.encode("utf-8"),ip_port)
data,addr = udp_client.recvfrom(buffer_size)
print(data)
socketserver源码分析udp版客户端2代码:
from socket import *
ip_port = ("127.0.0.1",8000)
buffer_size = 1024
udp_client = socket(AF_INET,SOCK_DGRAM)
while True:
msg = input(">>:").strip()
udp_client.sendto(msg.encode("utf-8"),ip_port)
data,addr = udp_client.recvfrom(buffer_size)
print(data)

