函数
#1、函数function的创建,def关键字,函数名,参数,return返回值
def test(x):
x += 1
return x
print(test)#打印出函数内存地址
a = test(1)#变量接收传入的值
print(a)
print(test(1))#传入参数并打印
#2、使用函数的好处?
代码重用,保持一致性,易维护,可扩展性
#3、函数返回值,
返回0个值时是None,
返回一个值是object对象,
返回多个值时是tuple元组
def test01():
msg = "hello the little green frog"
print(msg)
def test02():
msg = "hello zd"
print(msg)
return msg
t1 = test01()
t2 = test02()
print(t1)
print(t2)
#4、函数参数(形参和实参)
def cale(x,y): #定义形参x,y
res = x * y
return res
c = cale(2,4) #传入实参2,4
print(c)
#5、位置参数
def test(x,y,z):
print(x)
print(y)
print(z)
test(1,2,3)
#6、关键字参数
def test(x,y,z):
print(x)
print(y)
print(z)
test(y = 1,z = 9,x = 7)
#8、默认参数
def handle(x,type = None):
print(x)
print(type)
handle(1,3)
#9、参数组
def test(x,*args): #args当做元组
print(x)
print(args)
print(args[0])
test(1,2,3,4,5,6)
#10、关键字参数处理
def test(x,**kwargs):
print(x)
print(kwargs)
test(1,y = 2,z = 3)
#10、万能组合*args接受的是元组的形式、**kwargs接受的是字典形式
def test(x,*args,**kwargs):
print(x)
print(args,args[-1])
print(kwargs,kwargs.get("y"))
test(1,*[1,2,3],**{"y":1})
全局变量和局部变量
name = "zd" #全局变量
def change_name():
name = 1 #局部变量
print("change_name",name)
change_name()
#2、局部变量修改全局变量用global
name = "zd1"
def change_name():
global name
name = "zd2"
print("change_name",name)
change_name()
print(name)
#3、
names = "zs"
def ls():
global names
print("输出",names)
names = "ww"
print("输出",names)
def zl():
#names = "xh"
print("输出",names)
zl()
ls()
#4、无global可以用append增加
name = ["小明1","小明2"]
def dy():
name.append("小明3")
print("输出",name)
dy()
#5、总结:如果函数无global关键字,就先读取局部变量,能读取全局变量,无法对全局变量重新赋值,对于可变类型可以对内部元素进行操作,
#6、如果有global关键字本质上就是全局变量可以append
#7、全局变量全部大写,局部变量全部小写
NAME = "zx"
def test():
name = "cc"
global NAME
print("热烈欢迎",name)
test()
print("=============================================================================================================end")
#8、函数嵌套nest定义:程序自上而下执行,遇到函数内部不执行,只进行编译,
NAME = "海风"
def huangwei():
name = "黄伟"
print(name)
def liuyang():
name = "刘洋"
print(name)
def nulige():
name = "沪指花"
print(name)
print(name)
nulige()
liuyang()
print(name)
huangwei()
print("//////////////////////////////////////////////////////////////////////////end")
#9、global调用全局变量
name = "刚娘"
def weihou():
name = "陈卓"
def weiweihou():
global name
name = "冷静"
weiweihou()
print(name)
print(name)
weihou()
print(name)
print("\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\end")
#10、return接收返回值
def test3():
x = 1+1+1
return x
a= test3()
print(a)
print("cccccccccccccccccccccccccccccccccccccccccccccccccccccccccccccccccccccccccccccend")
#11、nonlocal的用法作用于上一级的作用
name = "刚娘"
def weihou():
name = "陈卓"
def weiweihou():
nonlocal name
name = "冷静"
weiweihou()
print(name)
print(name)
weihou()
print(name)
print("")
#1、前向引用forward direction
def foo():
print("from foo")
bar()
def bar():
print("from bar")
foo()
#1、风湿理论rheumatism theory创建
name = "海风"
def huangwei():
name = "黄伟"
print(name)
def liyang():
name = "李样"
print(name)
def nulige():
name = "沪指花"
print(name)
nulige()
liyang()
print(name)
print(name)
huangwei()
print(name)
#1、递归函数recursive function,函数内部自己调用自己,必须有明确的结束条件,
# import time
# def calc(n):
# print(n)
# time.sleep(1)
# calc(n)
# calc(10)
#2、
def calc(n):
print(n)
if int(n / 2) == 0 :
return n
res = calc(int(n / 2))
return res
calc(10)
#3、问路函数递归,每次进入更深一层递归时,问题规模相比上次递归都应有所减少,递归效率不高,递归层次过多会导致栈溢出(在计算机中,函数调用就是通过栈(stack)这种数据结构实现的,
#每当进入一个函数调用时,栈就会增加一层栈,每当函数返回时,栈就会减少一层,由于栈的大小不是无限的,所以,递归调用的次数过多,会导致栈溢出。
import time
person_list = ["alex","wupeiqi","yuanhao","linhaifeng"]
def ask_way(person_list):
print("-"*60)
if len(person_list) == 0:
return "没人知道"
person = person_list.pop(0)
if person == "linhaifeng":
return "%s说:我知道,老男孩就在沙河汇德商厦,下地铁就是" %person
print("hi 美男[%s],敢问路在何方"%person)
print("%s回答道:我不知道,但念你慧眼识珠,你等着,我帮你问问%s..."%(person,person_list))
time.sleep(1)
res = ask_way(person_list)
return res
res = ask_way(person_list)
print(res)
#1、作用域action scope首先返回内存地址
def test1():
print("in the test1") #无return默认是None
def test():
print("in the test")
return test1
res = test()
print(res())
print("*"*100)
#2、
def foo():
name = "lhf"
def bar():
name = "wupeiqi"
print(name)
def tt():
print(name)
return tt
return bar
foo()
#1、匿名函数lanbda function,加括号只是调用,前面加等号并赋值打印才是输出结果
def calc(x):
return x + 1
res = calc(10)
print(res)
#2、lambda语法结构
func = lambda x : x + 1 #x是形参,x + 1是返回值
print(func(10))
#3、实现zd加下划线_yy的需求?
name = "zd"
def change_name(x): #:冒号代表写子代码
return name + "_yy"
a = change_name(name)
print(a)
print("*"*100)
#4、lambda自动实现return功能
name = "zd"
f = lambda x : x + "_yy"
print(f(name))
print("结束1=======================================")
#5、匿名函数返回的结果可以是字符串的拼接、乘法、乘方、方法判断
a = lambda x : x.startswith("n")
print(a("nhm"))
#6、传送3个值加法
func = lambda x,y,z : x + y + z
print(func(1,2,3))
#7、自增1返回值记得加括号拼一块儿,而函数的return不用加括号的原因是默认返回的是元组自动加了括号
func1 = lambda x,y,z : (x + 1,y + 1,z + 1)
print(func1(1,2,3))
print("结束2+++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++")
#8、函数返回值
def foo(x,y,z):
return x + 1,y + 1,z +1
a = foo(1,2,3)
print(a)
编程届三种方法论:面向过程、函数式、面向对象


#1、函数式编程function programming
#y = 2 * x +1
#2、函数式编程思想举例:代码精简可读性差
def cal(x):
return 2 * x + 1
a = cal(3)
print(a)
#3、面向过程编程举例
def cal(x):
res = 2 * x
res += 1
return res
a = cal(3)
print(a)
print("================================================================end")
#1、高阶函数higher order function
#4、函数即变量:把函数当做参数传给另外一个函数
def foo(n):
print(n)
def bar(name):
print("my name is %s" %name) #此处没有None并传递给了上一个函数foo返回的也是None
foo(bar("zd"))
print("-------------------------------------------------------------------------------------------------------------------------end")
#5、有return返回函数的内存地址,无return返回None
def foo():
print("from foo")
return foo
a = foo()
print(a)
print("结束了-------------------------------------------------")
#6、返回值中包含函数
def bar():
print("from bar")
def foo():
print("from foo")
return bar
n = foo()
n()
print("nnnnnnnnnnnnnnnnnnnnnnnnnnnnnnnnnnnnnnnnnnnnnnnnnnnnnnn")
#7、
def hanle():
print("from hanle")
return hanle
h = hanle()
h()
#8、

#尾调用优化

#9、最后一步调用不一定是最后一行举例如下
def test(x):
if x > 1:
return True
elif x == 1:
return False
else:
return True
a = test(1)
print(a)
#10、尾递归调用优化,在函数最后一步
#1、map function创建列表,再定义空列表,再append到空列表中
num_l = [1,2,10,5,3,7]
num1_l = [1,2,10,5,3,7]
#自增1功能
def add_one(x):
return x + 1
#自减1功能
def reduce_one(x):
return x -1
#乘方功能
def pf(x):
return x ** 2
#开平方功能
def map_test(func,array): #array数组
ret = []
for i in num_l:
res = func(i)
ret.append(res)
return ret
print(map_test(add_one,num_l))
print(map_test(lambda x : x + 1,num_l))
print(map_test(reduce_one,num_l)) #reduce是上面定义的方法,num_l是待处理的数据
print(map_test(lambda x : x - 1,num_l))
print(map_test(pf,num_l))
print(map_test(lambda x : x ** 2,num_l))
# ret = map_test(num_l)
# rett = map_test(num1_l)
# print(ret)
# print(rett)
print("---------------------------------------------------------------------------上面结束了")
#2、终极版本
num_l = [1,2,10,5,3,7]
def map_test(func,array):
ret = []
for i in array:
res = func(i)
ret.append(res)
return ret
print(map_test(lambda x : x +1,num_l))
res = map(lambda x : x + 1,num_l)
print("内置函数map,处理结果",res) #object是对象地址,是可迭代的数据类型
for i in res:
print(i)
print(list(res)) #迭代器只能迭代一次,
大数据处理用到的函数map、filter、reduce:
#3、用map转大写变列表
msg = "zd"
print(list(map(lambda x:x.upper(),msg)))
#1、filter function看电影过滤开头
movie_people = ["sb_alex","sb_wupeiqi","linhaifeng","sb_yuanhao"]
def filter_test(array):
ret = []
for p in array:
if not p.startswith("sb"):
ret.append(p)
return ret
print(filter_test(movie_people))
#2、["linhaifeng"]指的是只是定义了一个数据类型列表,没人用,没有门牌号、在内存中存在立马就会回收
#3、print(res = filter_test(movie_people))指的是打印整个等式执行的结果,打印的是赋值过程
print("上面打印结束+++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++")
#4、过滤结尾
movie_people = ["alex_sb","wupeiqi_sb","linhaifeng","yuanhao_sb"]
def sb_show(n):
return n.endswith("sb")
def filter_test(func,array):
ret = []
for p in array:
if not func(p):
ret.append(p)
return ret
res = filter_test(sb_show,movie_people)
print(res)
print("上面结束了xxxxxxxxxxxxxxxxx--xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx-")
#5、终极版本filter函数得到一个bool值,如果是true,保留,filter处理的内存地址
movie_people = ["alex_sb","wupeiqi_sb","linhaifeng","yuanhao_sb"]
def filter_test(func,array):
ret = []
for p in array:
if not func(p):
ret.append(p)
return ret
res = filter_test(lambda n : n.endswith("sb"),movie_people)
print(res)
res = filter(lambda n :not n.endswith("sb"),movie_people) #记得加not
print(list(res))
print(list(filter(lambda n : not n.endswith("sb"),movie_people)))
#1、reduce function
from functools import reduce #从functools模块中导入reduce模块
num_l = [1,2,3,100]
res = 0
for num in num_l: #for循环实现列表里面的数字相加之和
res += num
print(res)
print("这里已经结束---------------------------------------------------------------")
#2、reduce函数实现
num_l = [1,2,3,100]
# def multi(x,y):
# return x * y
# lambda x,y :x * y
def reduce_test(func,array):
res = array.pop(0)
for num in array:
res = func(res,num)
return res
print(reduce_test(lambda x,y : x * y,num_l))
print("//////////////////////////////////////////////////////////////////////////")
#3、人为指定初始值
num_l = [1,2,3,100]
def reduce_test(func,array,init = None):
if init is None:
res = array.pop(0)
else:
res = init
for num in array:
res = func(res,num)
return res
print(reduce_test(lambda x,y : x * y,num_l,100))
print(reduce(lambda x,y : x * y,num_l,1))
#4、map函数是装一个列表依次处理得到的还是一个列表,跟原先的列表顺序一样、只不过每个元素被处理了、
#5、filter函数是把列表中的值所有的都筛选一遍最后在得到一个值(列表),
#6、reduce函数是可以把完整的序列合并到一块儿最终得到一个值,
#7、大数据里面的概念map和reduce
#1、过滤列表嵌套字典中的value用filter函数
people = [
{"name":"alex","age":1000},
{"name":"wupeiqi","age":10000},
{"name":"yuanhao","age":9000},
{"name":"linhaifeng","age":18},
]
print(list(filter(lambda p : p["age"] <= 18,people)))
a = filter(lambda x : x["age"] <= 18,people)
print(list(a))
#内置函数built-in function
#1、绝对值函数abs
print(abs(-1))
#2、all把序列中的每个元素做bool运算
print(all([1,2,"1"]))
print(all([1,2,"",0]))
#3、any是只要满足一个true就返回true
print(any([0,"",1]))
#4、bin把十进制转成二进制
print(bin(3))
#5、bool判断布尔值
print(bool(""))
#6、bytes把字符串转成字节, 电脑上的内存上的编码是uncode,utf-8一个中文用三个字节代表、斜杠x代表16进制
name = "你好"
print(bytes(name,encoding="utf-8").decode("utf-8")) #.decode代表解码,用什么方式编码就用什么方式解码,所以decode里面加入默认参数编码utf-8
print(bytes(name,encoding="gbk"))
print(bytes(name,encoding="gbk").decode("gbk")) #gbk保存中文是4个字节,python3默认的decode解码是utf-8
#print(bytes(name,encoding="ascii")) #ascii不能编码中文
#7、出现乱码的原因是编码和解码不一致
#8、chr是ascii码表的转换
print(chr(97))
print(chr(45))
print(chr(46))
#9、dir打印对象下面有哪些方法
print(dir(all))
#10、divmod取商得余数
print(divmod(10,3)) #用于做分页功能
#11、eval指的是把字典中的字符串中的数据结构提取出来
#12、eval可以把字符串中的数值运算
express = "1 + 2 * (3/3 - 1) - 2"
a = eval(express)
print(a)
#13、可hash的数据类型即不可变数据类型(元组tuple),不可hash的数据类型即可变数据类型(列表list)
print(hash("1")) #不管传入的参数有多长,得到的结果都是18位,不能根据结果反推字符串的原值
#14、hex十进制转16进制
print(hex(12))
#15、十进制转8进制
print(oct(12))
#16、id打印对象的内存地址
#17、isinstance判断数据类型的布尔值
print(isinstance(1,int))
print(isinstance("abc",str))
print(isinstance([],list))
print(isinstance({},dict))
#18、__file__是pycharm工具处理文件的地址
print(__file__)
#19、locals打印局部的
def test():
age = "111"
print(locals())
test()
#20、max取最大值
print(max(1,2,3))
#21、min取最小值
print(min(1,2,3))

#22、zip拉链,zip方法传两个参数,这两个参数都是序列类型:列表、元组、字符串
print(list(zip(("a","b","c"),(1,2,3))))
#23、用拉链取字典的key和value
p = {"name":"alex","age":18,"gender":"none"}
print(list(zip(p.keys(),p.values())))
print(list(zip(({"name":"alex"}.keys(),{"age":18}.values()))))
print(list(zip("hello","12345")))
#24、max高级应用
age_dic = {"age1":18,"age2":23,"age3":34}
print(max(age_dic.values()))
print(max(age_dic)) #默认是比较的key,取自ascii码表
for i in zip(age_dic.values(),age_dic.keys()):
print(i)
print(list(max(zip(age_dic.values(),age_dic.keys()))))
l = [
(5,"e"),
(1,"b"),
(3,"a"),
(4,"d"),
]
print(max(zip(l)))
print("/////////////////////////////////////////////////////////////////////////////////")
#25、max传入lambda方法
people = [
{"name":"alex","age":1000},
{"name":"wupeiqi","age":10000},
{"name":"yuanhao","age":9000},
{"name":"linhaifeng","age":18},
]
max(people,key=lambda dic:dic["age"])
ret = []
for item in people:
ret.append(item["age"])
print(ret)
print("取出来了",max(people,key=lambda dic:dic["age"]))
#26、进行大小比较的有字符串、数字、集合
# 27、ord根据数字对应ascii码表
print(ord("a"))
# 28、pow次方取余
print(pow(3, 3, 2))
# 29、reversed翻转
l = [1, 2, 3, 4]
print(list(reversed(l)))
print(list(reversed([1, 2, 3, 4])))
# 30、round四舍五入
print(round(3.5))
# 31、set组成集合
print(set("hello"))
# 32、slice切片
l = "hello"
s1 = slice(3, 5)
s2 = slice(1, 4, 2) # 指定步长
print(l[s1])
print(l[s2])
print(l[3:5]) # [3:5]是硬编码
# 33、sorted排序
l = [3, 2, 1, 5, 7]
print(sorted(l)) # 排序本质是在比较大小,必须是同类型的
people = [
{"name": "alex", "age": 1000},
{"name": "wupeiqi", "age": 10000},
{"name": "yuanhao", "age": 9000},
{"name": "linhaifeng", "age": 18},
]
print(sorted(people, key=lambda dic: dic['age']))
# 34、字符串中的数据类型提取出来用eval
dic_str = str({"a": 1})
print(eval(dic_str))
# 35、type判断数据类型
msg = "123"
if type(msg) is str:
msg = int(msg)
res = msg + 1
print(res)
# 36、sum函数
# 37、vars函数
# 38、模块就是py文件
# 39、.点代表调用
# 40、调用test.py文件
import test
test.say_hi()
test.say_hi()
#41、__import__是处理字符串类型的文件
module_name = "test"
m = __import__(module_name)
m.say_hi()
getattr()方法是属性不存在时触发
setattr()设置未找到时触发
delattr是删除的时候触发
函数进阶:
闭包closure函数
装饰器decorator
# l = [1,3]
# a = l.__iter__() #就等于iter(l)
# print(a.__next__())
# print(a.__next__())
#2、装饰器本质就是函数,功能是为其他函数添加附加功能,原则:不修改被修饰函数的源代码,不修改被装饰函数的调用方式
# import time
# def timmer(func):
# def wapper(*args,**kwargs):
# start_time = time.time()
# res = func(*args,**kwargs)
# stop_time = time.time()
# print("函数运行时间是%s" %(stop_time - start_time))
# return res
# return wapper
# @timmer
# def cal(l):
# res = 0
# for i in l:
# time.sleep(0.1)
# res += i
# return res
# res = cal(range(20))
# print(res)
# print("结束了。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。")
#3、装饰器 = 高阶函数 + 嵌套函数 + 闭包
#4、高阶函数:函数接收的参数是一个函数名,函数的返回值是一个函数名,
# def foo():
# print("你好啊张师傅")
# def test(func):
# print(func) #这个是打印func的内存地址
# start_time = time.time()
# time.sleep(2)
# func()
# stop_time = time.time()
# print("运行时间是%s" %(stop_time - start_time))
# test(foo)
#5、
# def foo():
# print("from the foo")
# def test(func):
# return func
# res = test(foo)
# print(res)
# res()
# foo = test(foo)
# print(foo)
# foo()
#6、
# import time
# # def foo():
# # time.sleep(3)
# # print("来自 foo")
# # #不修改foo源代码、不修改foo的调用方式
# # def timmer(func):
# # start_time = time.time()
# # func()
# # stop_time = time.time()
# # print("函数运行时间是%s" %(stop_time - start_time))
# # return func
# # foo = timmer(foo)
# # foo()
#7、
# def father(name):
# print("from father%s" %name)
# def son():
# print("from son")
# def grandson():
# print("from grandson")
# grandson()
# son()
# father("zd")
# print("上面运行结束。。。。。。。。。。。。")
# def father(auth_type):
# # print("from father%s" %name)
# def son():
# name = "zs"
# print("我的爸爸是%s" %auth_type)
# # print(locals()) #locals是打印当前层的局部变量
# son()
# father("zd")
#8、装饰器框架
import time
def timmer(func):
def wrapper(*args,**kwargs): #*args代表把所有的位置参数接收成元组、**kwargs代表用户传值的时候可能是关键字
# print(func)
start_time = time.time()
res = func(*args,**kwargs) #就是在运行test
stop_time = time.time()
print("运行时间是%s" %(stop_time - start_time))
return res
return wrapper #最后再返回结束状态
@timmer #等同于test = timmer(test)
def test(name,age):
time.sleep(3)
print("test函数运行完毕,名字是【%s】 年龄是【%s】" %(name,age))
return "这是test的返回值"
@timmer
def test1(name,age,gender):
time.sleep(1)
print("test1函数运行完毕,名字是【%s】 年龄是【%s】 性别是【%s】" %(name,age,gender))
return "这是test1的返回值"
# res = timmer(test) #返回的是wrapper地址
# res() #执行的是wrapper()
# test = timmer(test)
# test()
res = test("linhaifeng",18) #就是在运行wrapper
# print(res)
test1("alex",18,"male")
#9、
# def test1():
# time.sleep(3)
# print("test函数运行完毕")
# return "嘿嘿和"
# res = test1() #加括号只是调用、加括号后并赋值打印后才是函数的返回值、默认是None、也可以定义return 加字符串或列表或其他值、return应写在当前函数里面
# print(res)
生成器
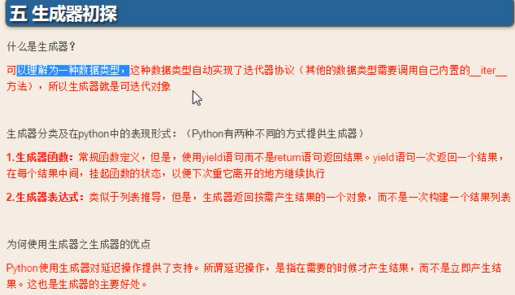
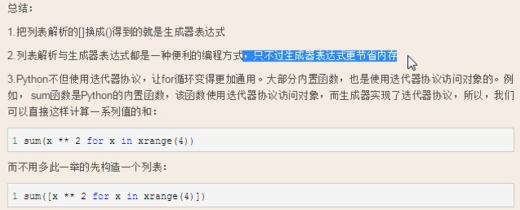
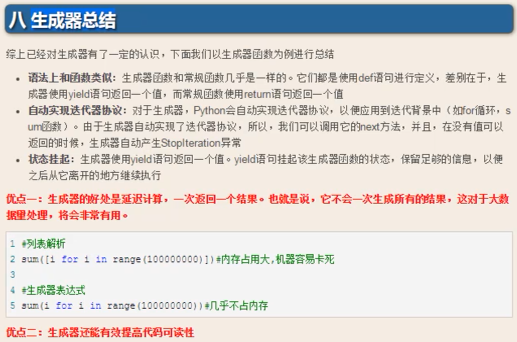
#1、generator生成器
def test():
yield 1
yield 2
yield 3
g = test()
print(g)
print(g.__next__())
#2、yield可以return多次
#3、三元表达式
name = "alex"
res = "sb" if name == "alex" else "heihei"
print(res)
#4、峰哥与Alex的故事
laomuji = ("鸡蛋%s" %i for i in range(10))
print(laomuji)
print(laomuji.__next__()) #下蛋1
print(laomuji.__next__()) #下蛋2
print(next(laomuji)) #下蛋3
#5、列表解析
egg_list = []
for i in range(10):
egg_list.append("鸡蛋%s"%i)
print(egg_list)
l = ["鸡蛋%s"%i for i in range(10) if i > 5]
print(l)
#6、
def test():
yield 1
yield 2
yield 3
yield 4
print(test().__next__())
print(test().__next__())
#7、包子程序
def prduct_baozi():
ret = []
for i in range(100):
ret.append("包子%s"%i)
return ret
baozi_list = prduct_baozi()
print(baozi_list)
#8、
def product_baozi():
for i in range(100):
yield "一屉包子%s" %i
pro_g = product_baozi()
baozi1 = pro_g.__next__()
print("来了一个人吃包子",baozi1)
print("-------------------------------------------------------------结束了")
#9、for循环生成器
def xiadan():
for i in range(100):
yield "鸡蛋%s" %i
alex_lmj = xiadan()
for i in alex_lmj:
print(i)
迭代器
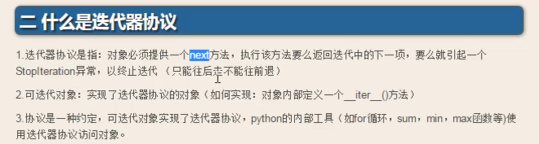

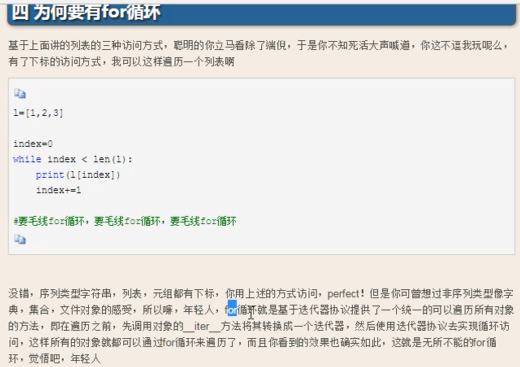
#1、iteration迭代
#2、迭代器协议、可迭代对象、协议
x = "hello" #hello有__iter__方法迭代器协议,x有__next__方法是可迭代对象
iter_test = x.__iter__()
print(iter_test)
print(iter_test.__next__())
l = [1,2,3]
for i in l : #l列表里面有__iter__方法
print(i)
#3、循环字典
dic = {"a":1,"b":2}
iter_d = dic.__iter__()
print(iter_d.__next__())
print(iter_d.__next__())
print("结束了--------------------")
#4、用while去模拟for循环做的事情
l = [1,2,3,4,5]
diedai_1 = l.__iter__()
while True:
try:
print(diedai_1.__next__())
except StopIteration:
print("迭代完毕了,循环终止了")
break
#5、next方法就是在调用__next__方法
l = ["die","erzi","sunzi"]
iter_l = l.__iter__()
print(iter_l.__next__())
print(next(iter_l))
#6、只要遵循迭代器协议那就是可迭代对象、调用iter__方法的最终结果就是生成了一个迭代器

 浙公网安备 33010602011771号
浙公网安备 33010602011771号