


Scrapy框架基本使用
整理自思维导图
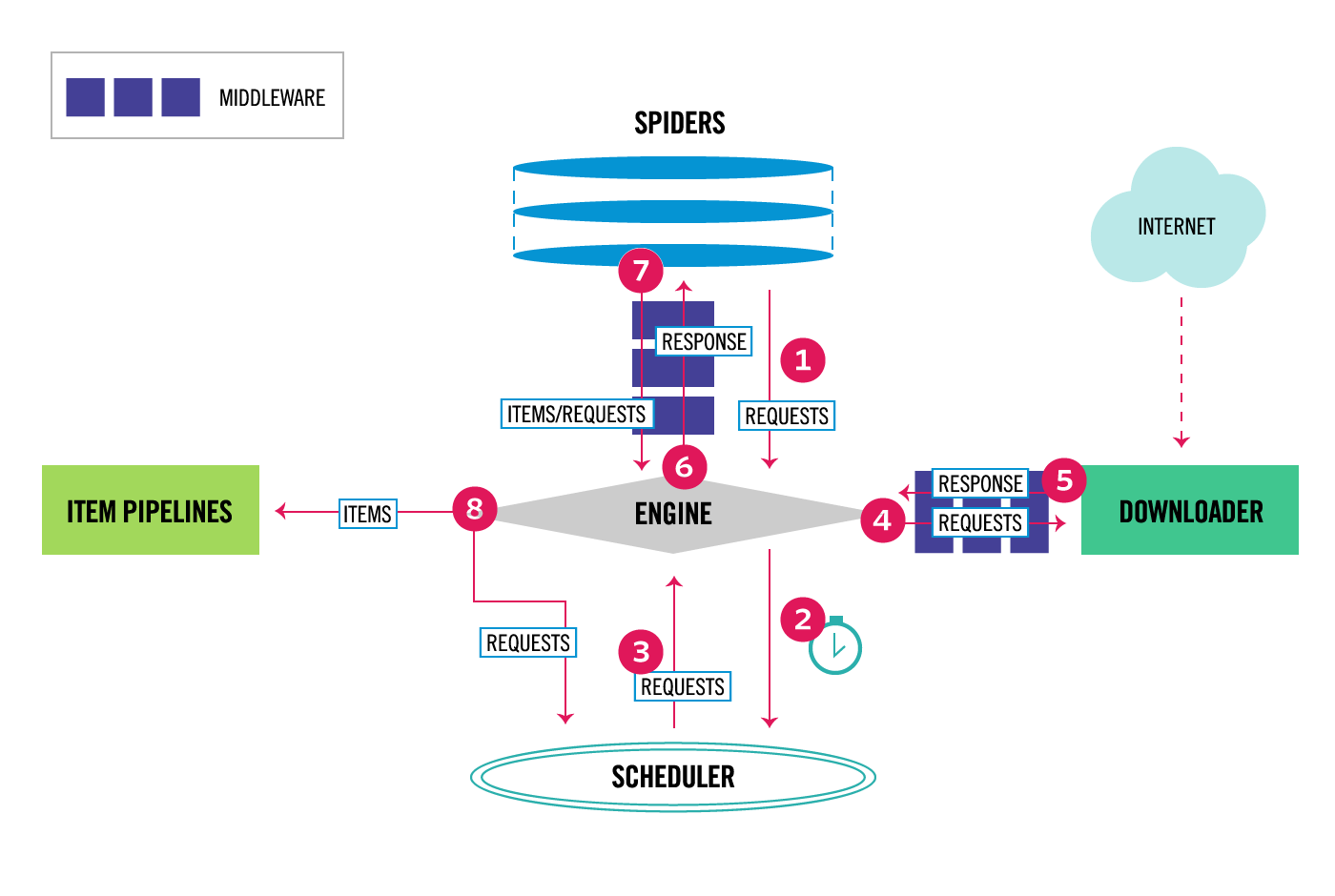
Scrapy一个开源和协作的框架
是基于twisted框架开发而来,twisted是一个流行的事件驱动的python网络框架。因此Scrapy使用了一种非阻塞(又名异步)的代码来实现并发。整体架构大致如下


命令行工具
常用的全局命令:


项目命令:

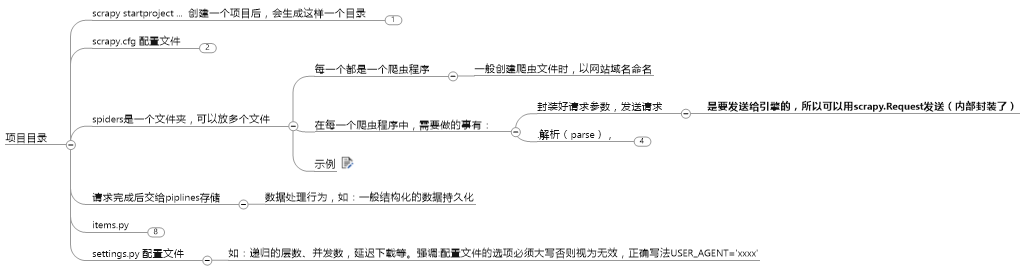
项目目录
解析器:


组件详解
spider:
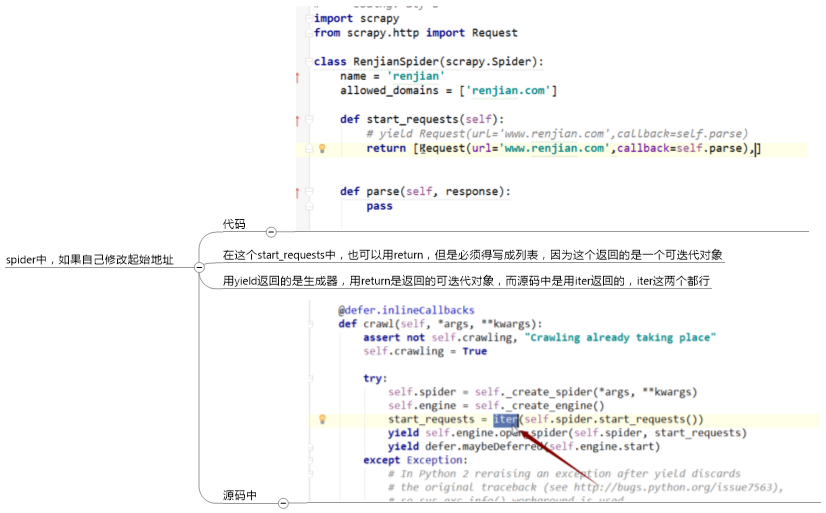
1.自己修改起始url
2.pipeline
使用前先配置:

优先级越小越先执行
方法:
process是一直执行的,但是open_spider是第一次打开爬虫的时候执行
close_spider是关闭爬虫的时候执行
如果有两个pipline
就是先执行上面那个process_item,在执行下面的process_item,一人一下
如果想上面执行,下面不执行,就需要在return里面,触发一个异常,这样就不会执行下面的proocess_item了
每个方法后面都有一个spider参数,可以用这个区分不同的爬虫程序
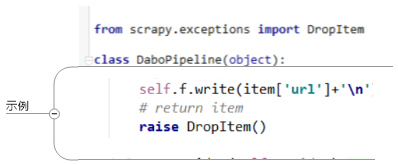
3.去重规则
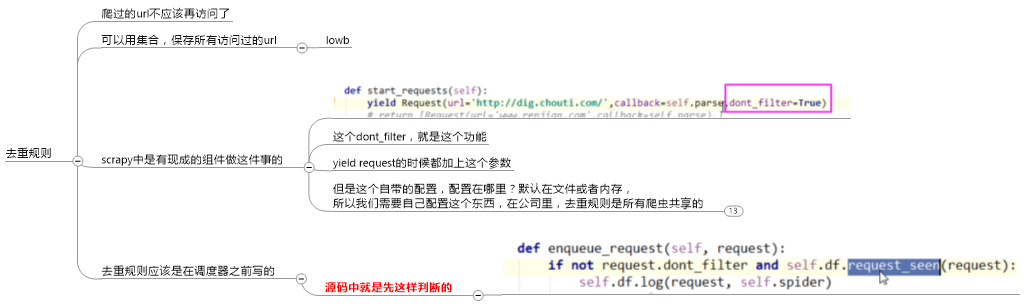
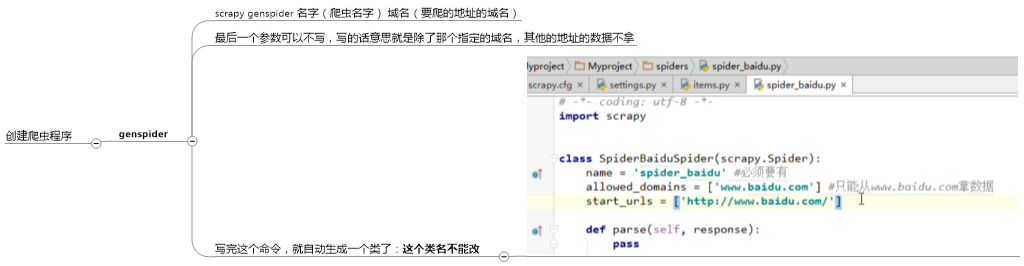
4.自定制命令:
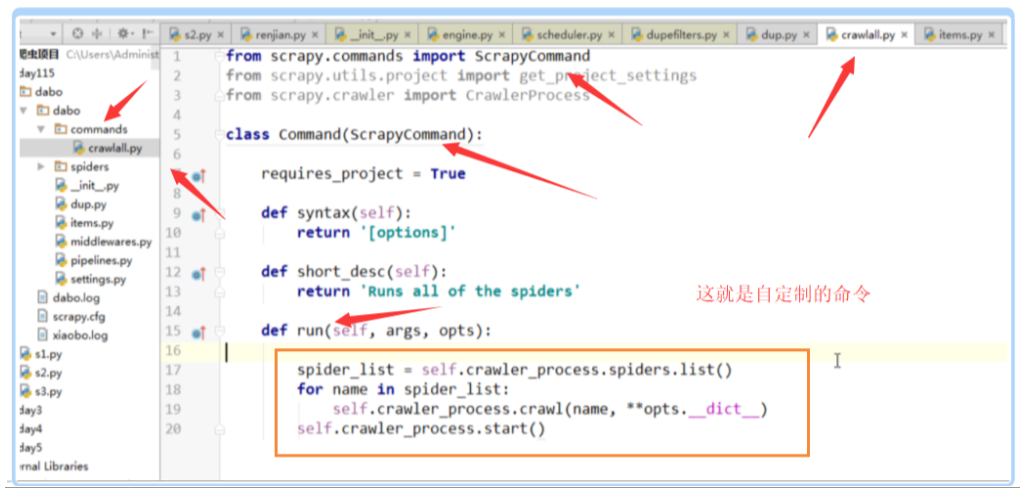
这个spider_list就是我们自己要找的所有的爬虫
重点是这几个代码,是爬虫源码的入口,我们可以通过这几个命令,都可以顺着找到爬虫是怎么做的
5.scrapy的信号
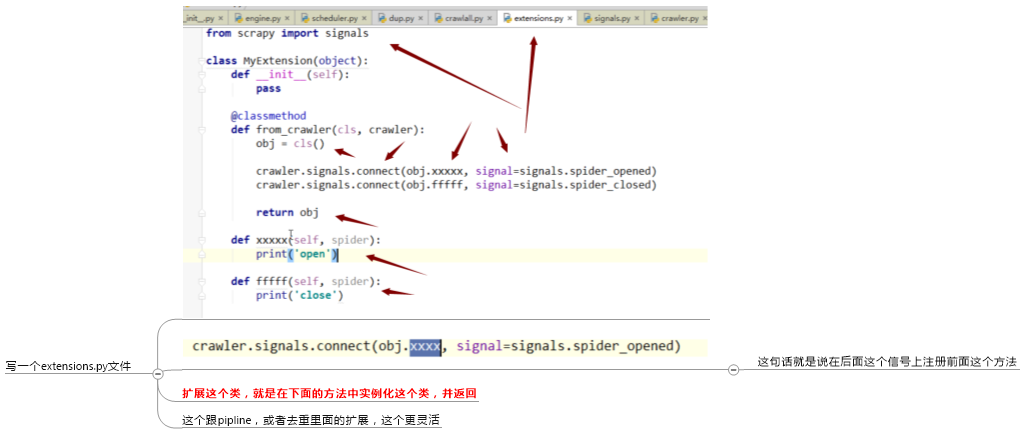
需要这样配置:
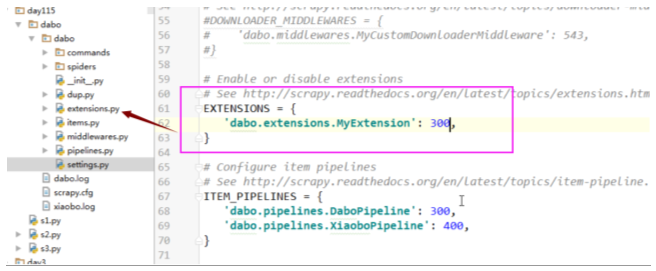
6.中间件
scrapy的中间件分为下载中间件和爬虫中间件,重点介绍下载中间件
下载中间件:
使用自己的中间件,得先配置:

下载中间件有三个方法:
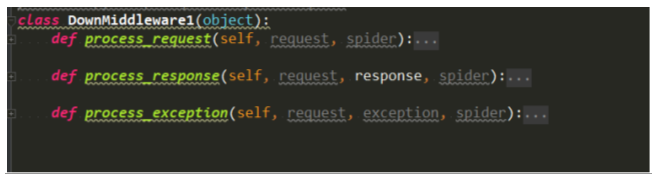
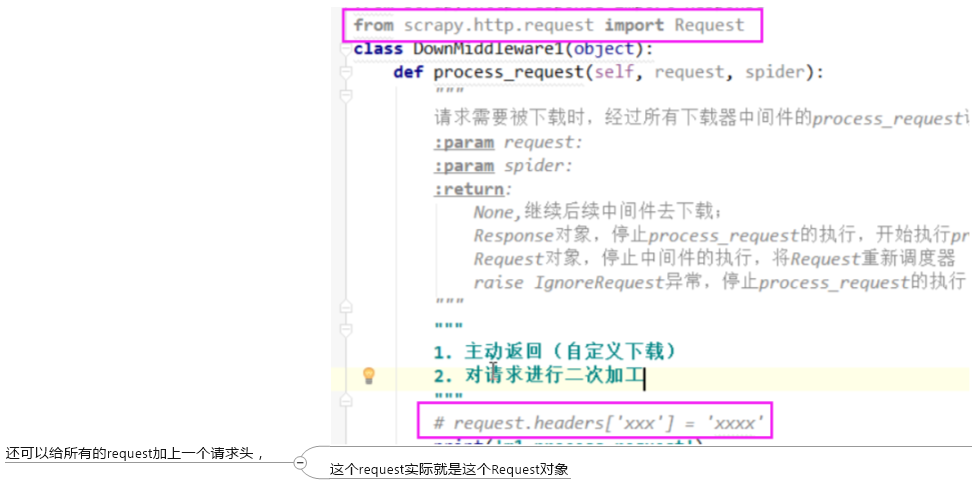
其中process_request的返回值,

返回一个request对象,将会直接返回到调度器,重新开始访问url,如果一直这样,就变成死循环了,,可以用来做重试,比如没有下载成功,就再重新走一次
如果想返回一个response:
首先应该返回的是一个response对象,而不是自己瞎写的什么返回值
def process_response(self, request, response, spider): """ spider处理完成,返回时调用 :param response: :param result: :param spider: :return: Response 对象:转交给其他中间件process_response Request 对象:停止中间件,request会被重新调度下载 raise IgnoreRequest 异常:调用Request.errback """ from scrapy.http.response import Response #response对象是从这里导入的 return Response(url='http://www.baidu.com',request=request)
如果返回一个response,结果是所有的response都执行了,这个跟Django1.7,1.8的做法是一样的,但是和现在的版本不一样
应用:1.缓存,自己返回了response,就不执行后续代码了
2.设置代理,
3.为所有的请求设置请求头
说一说这个代理,scrapy默认是支持的,但是他的代理是需要配置环境变量的,在程序运行之前,是先从一个地方拿代理,所以要先去这个地方写好,这个地方就是环境变量
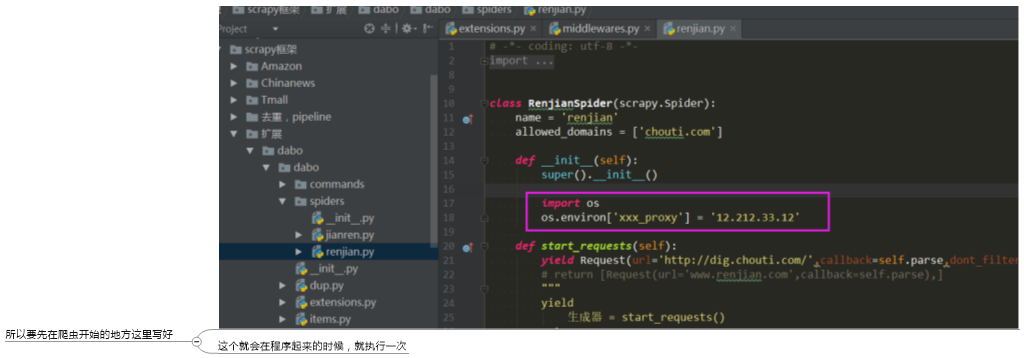
os.environ就是当前的环境变量
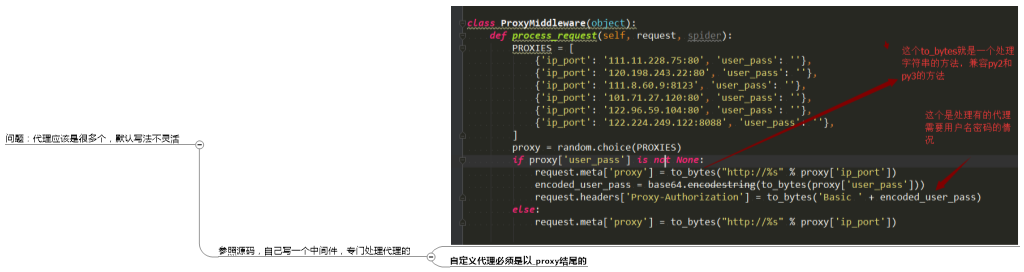
详细可以参照http://www.cnblogs.com/wupeiqi/articles/6229292.html
设置请求头:
爬虫中间件:
class SpiderMiddleware(object): def process_spider_input(self,response, spider): """ 下载完成,执行,然后交给parse处理 :param response: :param spider: :return: """ pass def process_spider_output(self,response, result, spider): """ spider处理完成,返回时调用 :param response: :param result: :param spider: :return: 必须返回包含 Request 或 Item 对象的可迭代对象(iterable) """ return result def process_spider_exception(self,response, exception, spider): """ 异常调用 :param response: :param exception: :param spider: :return: None,继续交给后续中间件处理异常;含 Response 或 Item 的可迭代对象(iterable),交给调度器或pipeline """ return None def process_start_requests(self,start_requests, spider): """ 爬虫启动时调用 :param start_requests: :param spider: :return: 包含 Request 对象的可迭代对象 """ return start_requests
7.配置相关
scrapy支持离线操作,即缓存页面信息,需要这样配置:
实战:爬取天猫Python书籍信息


3.修改起始url
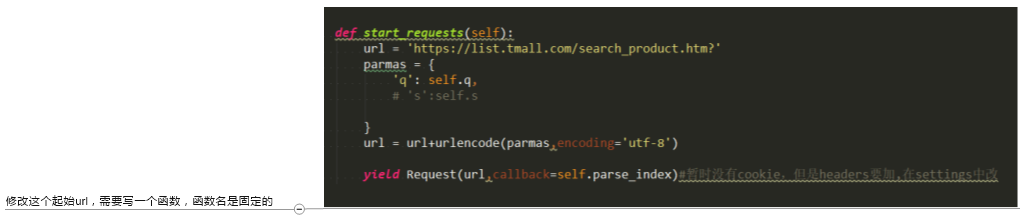
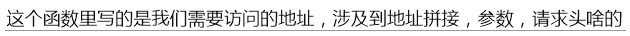


还有注意是用yield,对于这种io操作,要想让scrapy识别,必须用yield返回
4.解析函数
有两个,因为需要到详情页,所以需要一个解析首页的函数,一个解析详情页的函数
首页的函数:


def start_requests(self): url = 'https://list.tmall.com/search_product.htm?' parmas = { 'q': self.q, # 's':self.s } url = url+urlencode(parmas,encoding='utf-8') yield Request(url,callback=self.parse_index)#暂时没有cookie,但是headers要加,在settings中改
爬取详情页的逻辑也差不多,就不多说了
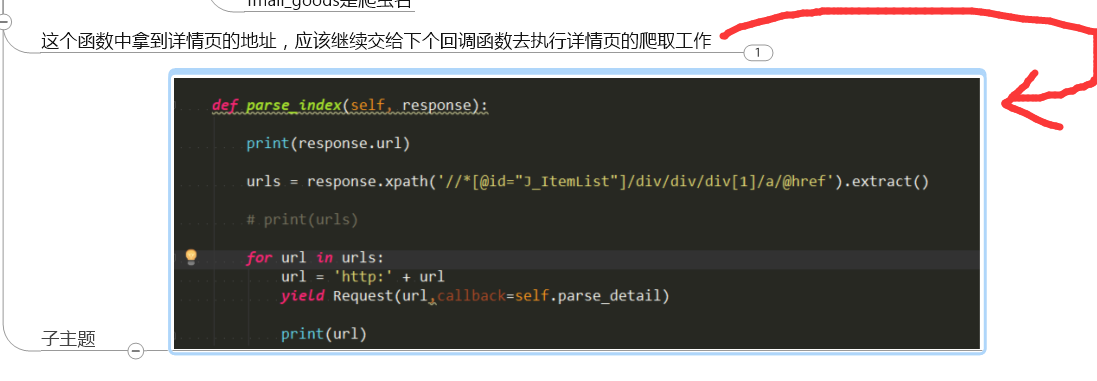
5.写item

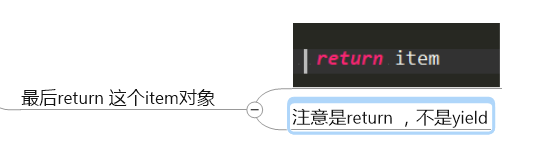
6.把数据保存到数据库


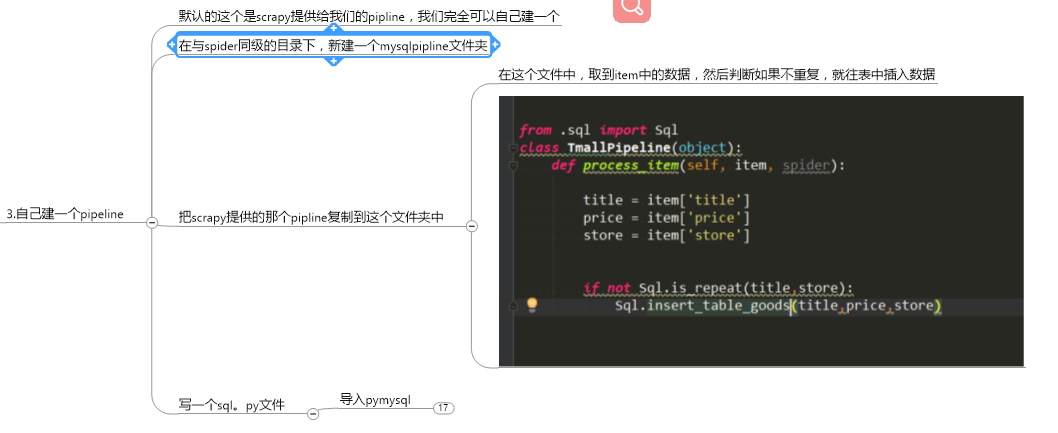
这个pymysql的具体操作:

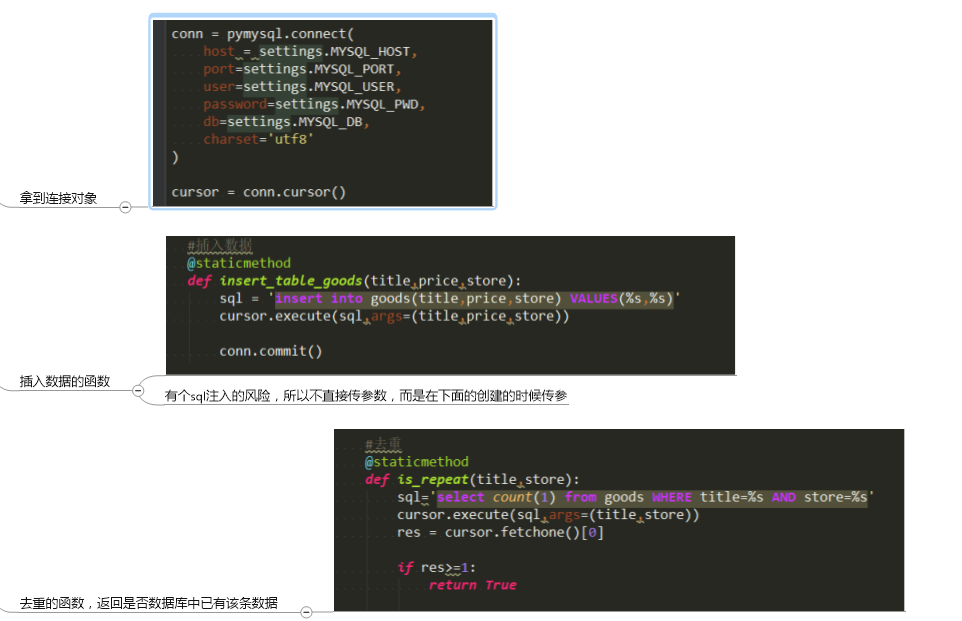
完整代码:
import pymysql from .. import settings conn = pymysql.connect( host = settings.MYSQL_HOST, port=settings.MYSQL_PORT, user=settings.MYSQL_USER, password=settings.MYSQL_PWD, db=settings.MYSQL_DB, charset='utf8' ) cursor = conn.cursor() class Sql(object): #插入数据 @staticmethod def insert_table_goods(title,price,store): sql = 'insert into goods(title,price,store) VALUES(%s,%s)' cursor.execute(sql,args=(title,price,store)) conn.commit() #去重 @staticmethod def is_repeat(title,store): sql='select count(1) from goods WHERE title=%s AND store=%s' cursor.execute(sql,args=(title,store)) res = cursor.fetchone()[0] if res>=1: return True
最后整理一下scrapy的操作流程:
- name - start_url, start_requests - request对象,封装:请求相关和回调函数 - reponse对象,封装:响应相关和请求相关 - 获取start_requests中返回的【迭代器】 - 执行爬虫中间件 process_start_requests - 去重规则:request_seen - 放入调度器,requests可能会有序列化操作,===> enqueue_request - 去调度器中获取任务, ===> next_request - 下载中间件 - 设置请求头 - 代理【内置 _proxy;自定义下载中间件】 - 自己下载返回response - 爬虫的回调函数 parse yield request对象 yield item对象 - pipeline - 扩展,基于信号 - Https
好了,关于scrapy_redis的使用,请关注我下一篇博客
