使用ecplise开发MapReduce
一、环境准备
1.添加插件到eclipse plugins目录下就可以了

2.把Window编译后的hadoop的文件放到 hadoop的bin目录下
3.配置环境变量
HADOOP_HOME=E:\hadoop\hadoop-2.7.7
Path=%HADOOP_HOME%\bin;%HADOOP_HOME%\sbin
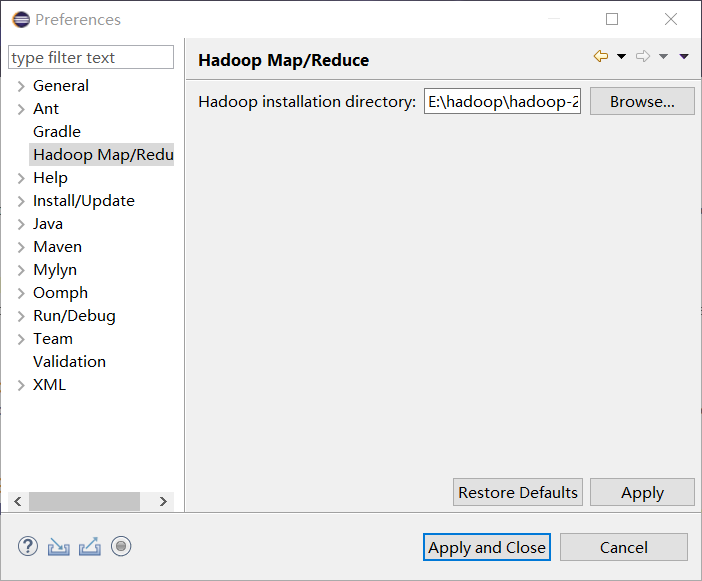
4.在eclipse中添加hadoop Window >> Preferences
若是找不到Hadoop Map/Reduce 删除eclipse安装目录configuration文件中的org.eclipse.update文件夹,重启eclipse即可。
5.切换到Map/Reduce视图 >>Window->Show View->Other->MapReduce Tools,双击打开

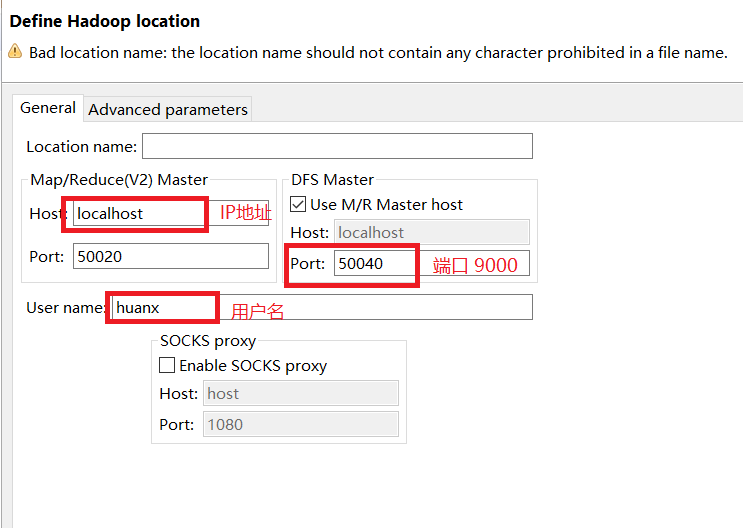
6.建立链接
7.准备数据集 设置为utf-8格式 >> 打开文件 >> 另存为 >> 编码utf-8

8.hadoop-2.7.7\share\hadoop 中的common、hdfs、mapreduce、yarn中的jar包导入到项目的lib目录
二、新建Map/Reduce项目
new >> other >> Map/Reduce Project

三、代码
1.WordCountMapper类
package hdfs; import java.io.IOException; import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.LongWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Mapper; public class WordCountMapper extends Mapper<LongWritable,Text,Text,IntWritable>{ @Override protected void map(LongWritable key, Text value, Mapper<LongWritable, Text, Text, IntWritable>.Context context) throws IOException, InterruptedException { //从文本中读出一行 String line = value.toString(); //将这一行字符串变成字符数组 char[] charArray = line.toCharArray(); //遍历每一个字符 for(char a:charArray) { //将字符以 字符 1 的格式一行行输出到临时文件中 context.write(new Text(a+""), new IntWritable(1)); //注:MapReduce中有自己的数据类型,需进行转换 } } }
2.WordCountReduce类
package hdfs; import java.io.IOException; import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Reducer; public class WordCountReduce extends Reducer<Text, IntWritable, Text, IntWritable>{ @Override protected void reduce(Text key, Iterable<IntWritable> values, Reducer<Text, IntWritable, Text, IntWritable>.Context content) throws IOException, InterruptedException { //设计一个变量统计总数 int num = 0; //遍历数据中整数部分 for(IntWritable v:values) { //get()获得int类型的整数,然后累加 num += v.get(); } //以 字符 总数 的格式输出到指定文件夹 content.write(key, new IntWritable(num)); } }
3.WordCountDriver类
package hdfs; import java.io.IOException; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; public class WordCountDriver{ public static void main(String[] arge) { //配置访问地址 Configuration conf = new Configuration(); conf.set("fs.defaultFS", "hdfs://192.168.124.26:9000"); try { //获得job任务对象 Job job = Job.getInstance(conf); //设置driver类 job.setJarByClass(WordCountDriver.class); //设置Map类 job.setMapperClass(WordCountMapper.class); //设置Map类输出的key数据的格式类 job.setMapOutputKeyClass(Text.class); //设置Map类输出的value数据的格式类 job.setMapOutputValueClass(IntWritable.class); //设置Reduce类 如果Reduce类输出格式类与Map类的相同,可不写 job.setReducerClass(WordCountReduce.class); //设置Map类输出的key数据的格式类 job.setOutputKeyClass(Text.class); //设置Map类输出的value数据的格式类 job.setOutputValueClass(IntWritable.class); //设置被统计的文件的地址 FileInputFormat.setInputPaths(job, new Path("/in/poetry.txt")); //设置统计得到的数据文件的存放地址 //注:文件所在的文件夹需不存在,由系统创建 FileOutputFormat.setOutputPath(job, new Path("/out/")); //true表示将运行进度等信息及时输出给用户,false的话只是等待作业结束 job.waitForCompletion(true); } catch (IOException e) { e.printStackTrace(); } catch (ClassNotFoundException e) { e.printStackTrace(); } catch (InterruptedException e) { e.printStackTrace(); } } }
4.权限问题:
1)关闭访问权限#core-site.xml
<property>
<name>dfs.permissions</name>
<value>false</value>
</property>
2)授权 hadoop fs -chmod 777 文件路径
5.结果显示

四、打包到linux上运行
1.打包项目 File >> export >> 选择JAR file >> 选择打包的类
2.使用rz上传wordcount.jar包,hadoop jar wordcount.jar hdfs/WordCountDriver(主类,加上路径)
3.如果报错Retrying connect to server: hdp-06/192.168.124.26:8032 8032端口没开,start-all.sh 开启所有服务
4.结果


 浙公网安备 33010602011771号
浙公网安备 33010602011771号