
六、事务和索引
一、事务
在日常的操作场景中(比如转账),需要判断多条语句都成功才能确定该操作成功(转账人扣除费用,收款人增加费用)。这种时候我们就需要用到事务,来将这多个语句视作一个整体,在保证功能的正常运行。
1. 事务的特点
- 原子性:多个语句看作一个整体,看作最小的原子,不可拆分
- 一致性:事务完成后,所有数据的状态都是一致的,即A账户只要减去了100,B账户则必定加上了100
- 隔离型:如果有多个事务并发执行,每个事务作出的修改必须与其他事务隔离
- 持久性:即事务完成后,对数据库数据的修改被持久化存储
2. 示例
2.1 数据准备
-- 准备数据 CREATE TABLE `account`( `id` INT(4) NOT NULL AUTO_INCREMENT COMMENT 'ID', `name` VARCHAR(10) NOT NULL COMMENT '姓名', `money` DOUBLE NOT NULL COMMENT '账户余额', PRIMARY KEY(`id`) )ENGINE=INNODB DEFAULT CHARSET=utf8; INSERT INTO `account`(`name`, `money`) VALUES('张三',5000),('李四',900);
我们准备了一张账户表,并插入了张三和李四两条数据,接下来我们要尝试实现转账的功能。
2.2 方式一:修改autocommit属性实现
-- 1.使用autocommit修改自动提交 SET AUTOCOMMIT=0; START TRANSACTION; UPDATE `account` SET `money`=`money`-500 WHERE `name`='张三'; UPDATE `account` SET `money`=`money`+500 WHERE `name`='李四'; COMMIT; ROLLBACK; SET AUTOCOMMIT=1;
在上面的sql中,我们关闭了自动提交,使用start transaction开始事务,然后进行一系列操作,最后commit提交,将改动持久化,最后再将自动提交开启。
2.3 方式二:使用begin关键字开始事务
-- 2.使用begin方式 BEGIN; UPDATE `account` SET `money`=`money`+400 WHERE `name`='张三'; UPDATE `account` SET `money`=`money`-400 WHERE `name`='李四'; COMMIT; ROLLBACK;
二、索引
MySQL中的索引相当于字典的目录,可以快速的定位到要查找的数据。
1. 索引分类
- 主键索引(PRIMARY KEY)-- 唯一的标识,主键不可重复,并且一个表中只有一个列作为主键
- 唯一索引(UNIQUE KEY)-- 避免重复的列出现,列上的数据的唯一性,一张表上可以有多个唯一索引
- 常规索引(KEY/INDEX)-- 默认的索引,可以用key或者index设置
- 全文索引(FullText)-- 在特定的数据库引擎中才有,可以快速定位文本中的数据
2. 索引的原则
- 索引不是越多越好
- 不要对经常变动的字段添加索引
- 小数据量的表不需要添加索引
- 索引一般加在常用来查询的字段上
3. 使用
3.1 数据准备
现在有一张student学生表,我们准备一些数据,往表中插入100,0000条学生信息。
DELIMITER DROP PROCEDURE IF EXISTS looppc; CREATE PROCEDURE looppc() BEGIN DECLARE i INT; SET i = 2; REPEAT INSERT INTO `student`(`name`,`sex`,`birthday`,`address`,`email`) VALUES(CONCAT('测试',CAST(i AS CHAR)),'女','2021-04-21','上海',CONCAT('test',CAST(i AS CHAR),'@qq.com')); SET i = i+1; UNTIL i >= 1000000 END REPEAT; END CALL looppc()
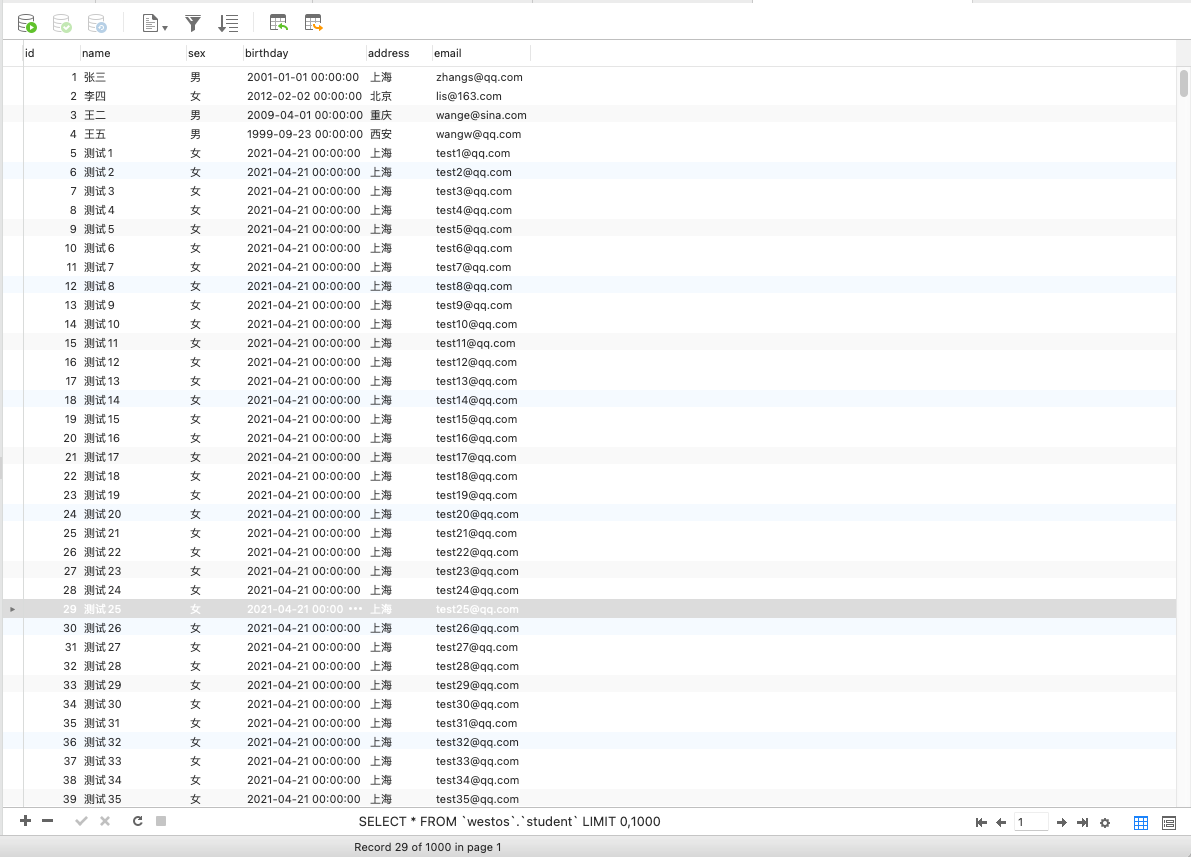
插入后的数据是这样的:
3.2 不使用索引查询一条数据
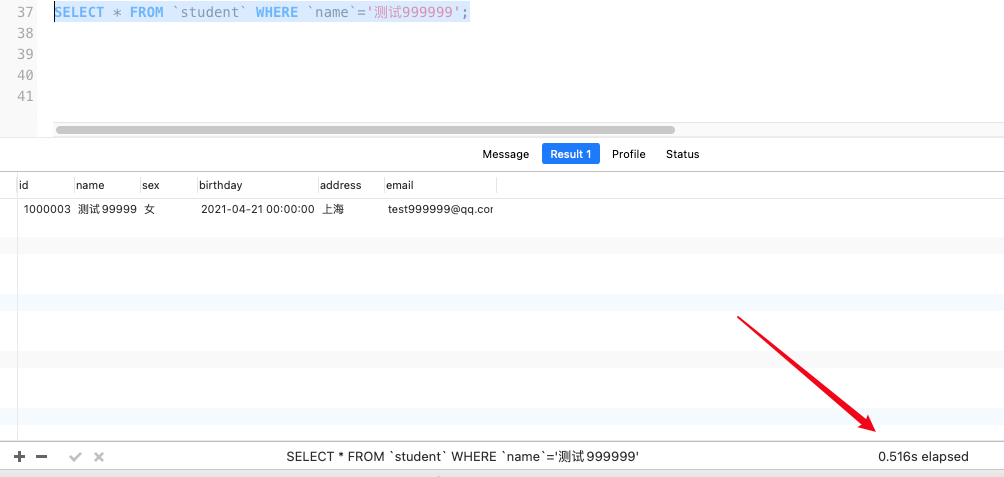
查询姓名是'测试999999'的学生数据,使用了0.516秒。
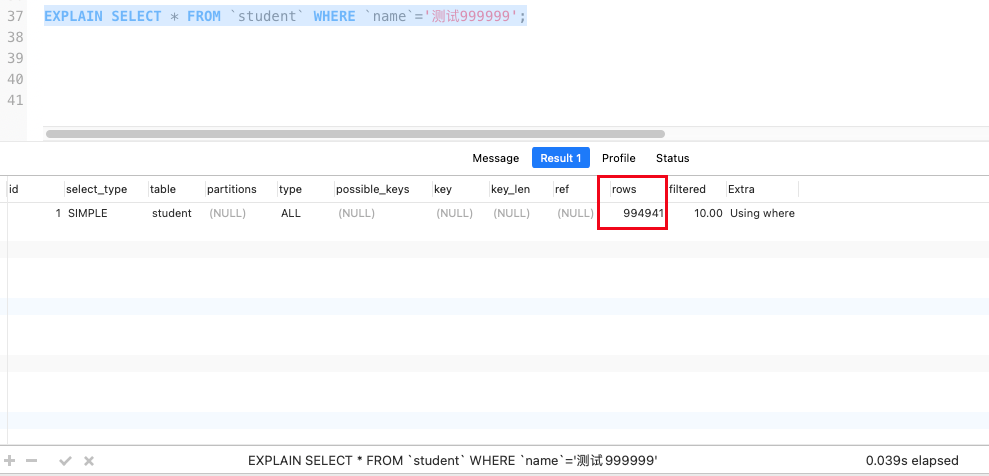
我们使用EXPLAIN命令查看这个语句的运行情况,可以看到,在查询了99万多条数据后,找到了我们想要的数据。
3.3 添加索引后再查询
我们为student表的name列增加索引studentName,添加索引需要一些时间,等待完成。
ALTER TABLE `student` ADD INDEX studentName(`name`);
索引添加完成后,我们再查询上面那一条数据:

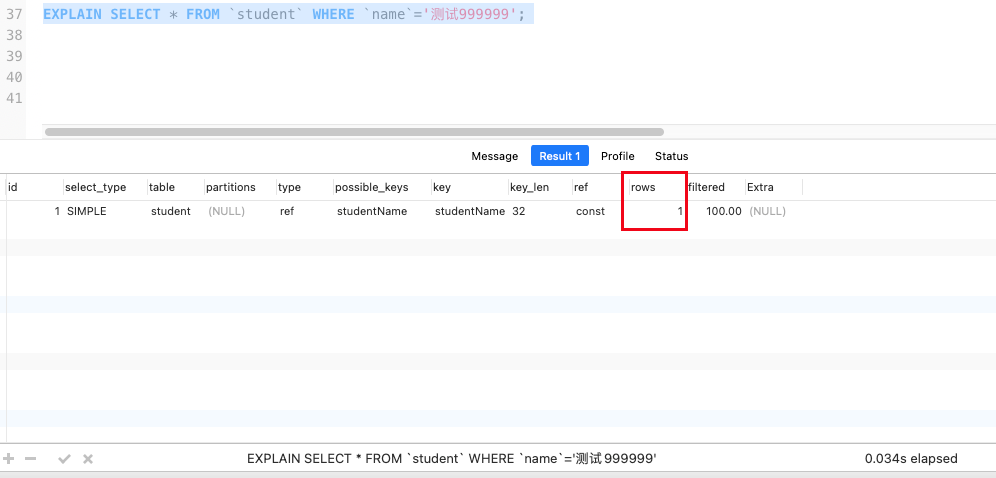
可以看到,在添加了索引后,查询只用了0.048秒,使用explain查看到,在查询时只查找了一条数据,就直接定位到该数据。这是在数据量不是特别大的情况下,如果业务场景更加复杂,使用索引带来的优化效果会更加明显。
3.4 删除索引
ALTER TABLE `student` DROP INDEX studentName;


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】博客园2025新款「AI繁忙」系列T恤上架,前往周边小店选购
【推荐】凌霞软件回馈社区,携手博客园推出1Panel与Halo联合会员
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 解锁.NET 9性能优化黑科技:从内存管理到Web性能的最全指南
· 通过一个DEMO理解MCP(模型上下文协议)的生命周期
· MySQL下200GB大表备份,利用传输表空间解决停服发版表备份问题
· 记一次 .NET某固高运动卡测试 卡慢分析
· 微服务架构学习与思考:微服务拆分的原则
· 解锁.NET 9性能优化黑科技:从内存管理到Web性能的最全指南
· .net clr 8年才修复的BUG,你让我损失太多了
· 一个神奇的JS代码,让浏览器在新的空白标签页运行我们 HTML 代码(createObjectURL
· 即时通信SSE和WebSocket对比
· 做Docx预览,一定要做这个神库!!