
Flink学习笔记
一、Flink 概述
- 分布式的 计算引擎
- 支持 批处理 ,即处理静态的数据集、历史的数据集
- 支持 流处理 ,即实时地处理一些实时数据流
- Flink认为 有界数据集 是 无界数据流 的一种特例,所以说有界数据集也是一种数据流,事件流也是一种数据流。
- 无界流 :意思很明显,只有开始没有结束。必须连续的处理无界流数据,也即是在事件注入之后立即要对其进行处理。不能等待数据到达了再去全部处理,因为数据是无界的并且永远不会结束数据注入。处理无界流数据往往要求事件注入的时候有一定的顺序性,例如可以以事件产生的顺序注入,这样会使得处理结果完整。
- 有界流 :也即是有明确的开始和结束的定义。有界流可以等待数据全部注入完成了再开始处理。注入的顺序不是必须的了,因为对于一个静态的数据集,我们是可以对其进行排序的。有界流的处理也可以称为 批处理 。
二、flink on yarn
yarn-session提供两种模式: 会话模式 和 分离模式
会话模式
- 使用Flink中的yarn-session(yarn客户端),会启动两个必要服务 JobManager 和 TaskManager
- 客户端通过yarn-session提交作业
- yarn-session会一直启动,不停地接收客户端提交的作用
- 有大量的小作业,适合使用这种方式
分离模式
- 直接提交任务给YARN
- 大作业,适合使用这种方式
三、Flink四个基石
- Checkpoint:Checkpoint 机制,这是Flink最重要的一个特性。Flink基于 Chandy-Lamport 算法实现了一个分布式的一致性的快照,从而提供了 一致性的语义 。
- State :Flink为了让用户在编程时能够更轻松、更容易地去 管理状态 ,还提供了一套非常简单明了的State API,包括里面的有ValueState、ListState、MapState,近期添加了BroadcastState,使用State API能够自动享受到这种一致性的语义。
- Time :Flink还实现了 Watermark 的机制,能够支持基于 事件的时间 的处理,或者说基于系统时间的处理,能够容忍数据的 迟到 、容忍 乱序 的数据。
- Window :Flink提供了开箱即用的各种窗口,比如 滑动窗口 、 滚动窗口 、 会话窗口 以及非常灵活的 自定义的窗口
四、flink批处理开发
- 基于本地集合的 source
- 基于文件的 source
- 基于网络套接字的 source
- 自定义的 source。自定义的 source 常见的有 Apache kafka、Amazon Kinesis Streams、RabbitMQ、Twitter、Streaming API、Apache NiFi 等,当然你也可以定义自己的 source。
- 写入文件、
- 打印输出、
- 写入 socket
- 自定义的 sink 。自定义的 sink 常见的有 Apache kafka、RabbitMQ、MySQL、ElasticSearch、Apache Cassandra、Hadoop FileSystem 等,同理你也可以定义自己的 Sink。
1、pom.xml环境
<?xml version="1.0" encoding="UTF-8"?> <project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd"> <modelVersion>4.0.0</modelVersion> <groupId>com.zhc</groupId> <artifactId>flink-base</artifactId> <version>1.0-SNAPSHOT</version> <properties> <maven.compiler.source>1.8</maven.compiler.source> <maven.compiler.target>1.8</maven.compiler.target> <encoding>UTF-8</encoding> <scala.version>2.11</scala.version> <flink.version>1.9.2</flink.version> <hadoop.version>2.7.6</hadoop.version> </properties> <dependencies> <!--Flink TableAPi--> <dependency> <groupId>org.apache.flink</groupId> <artifactId>flink-table-api-java-bridge_${scala.version}</artifactId> <version>${flink.version}</version> </dependency> <dependency> <groupId>org.apache.flink</groupId> <artifactId>flink-table-api-scala-bridge_${scala.version}</artifactId> <version>${flink.version}</version> </dependency> <dependency> <groupId>org.apache.flink</groupId> <artifactId>flink-table-planner-blink_${scala.version}</artifactId> <version>${flink.version}</version> </dependency> <dependency> <groupId>org.apache.flink</groupId> <artifactId>flink-table-planner_${scala.version}</artifactId> <version>${flink.version}</version> </dependency> <dependency> <groupId>org.apache.flink</groupId> <artifactId>flink-table-common</artifactId> <version>${flink.version}</version> <scope>provided</scope> </dependency> <!--导入scala的依赖--> <dependency> <groupId>org.apache.flink</groupId> <artifactId>flink-scala_${scala.version}</artifactId> <version>${flink.version}</version> </dependency> <dependency> <groupId>org.apache.flink</groupId> <artifactId>flink-connector-kafka_${scala.version}</artifactId> <version>${flink.version}</version> </dependency> <!--模块二 流处理--> <dependency> <groupId>org.apache.flink</groupId> <artifactId>flink-streaming-scala_${scala.version}</artifactId> <version>${flink.version}</version> </dependency> <dependency> <groupId>org.apache.flink</groupId> <artifactId>flink-streaming-java_${scala.version}</artifactId> <version>${flink.version}</version> </dependency> <!--对象和json 互相转换的--> <dependency> <groupId>com.alibaba</groupId> <artifactId>fastjson</artifactId> <version>1.2.44</version> </dependency> <dependency> <groupId>org.apache.flink</groupId> <artifactId>flink-runtime-web_2.11</artifactId> <version>${flink.version}</version> </dependency> <dependency> <groupId>org.apache.hadoop</groupId> <artifactId>hadoop-client</artifactId> <version>${hadoop.version}</version> </dependency> <!-- 指定mysql-connector的依赖 --> <dependency> <groupId>mysql</groupId> <artifactId>mysql-connector-java</artifactId> <version>5.1.38</version> </dependency> </dependencies> <build> <sourceDirectory>src/main/scala</sourceDirectory> <testSourceDirectory>src/test/scala</testSourceDirectory> <plugins> <plugin> <groupId>org.apache.maven.plugins</groupId> <artifactId>maven-compiler-plugin</artifactId> <version>2.5.1</version> <configuration> <source>${maven.compiler.source}</source> <target>${maven.compiler.target}</target> <!--<encoding>${project.build.sourceEncoding}</encoding>--> </configuration> </plugin> <plugin> <groupId>net.alchim31.maven</groupId> <artifactId>scala-maven-plugin</artifactId> <version>3.2.0</version> <executions> <execution> <goals> <goal>compile</goal> <goal>testCompile</goal> </goals> <configuration> <args> <!--<arg>-make:transitive</arg>--> <arg>-dependencyfile</arg> <arg>${project.build.directory}/.scala_dependencies</arg> </args> </configuration> </execution> </executions> </plugin> <plugin> <groupId>org.apache.maven.plugins</groupId> <artifactId>maven-shade-plugin</artifactId> <version>2.3</version> <executions> <execution> <phase>package</phase> <goals> <goal>shade</goal> </goals> <configuration> <filters> <filter> <artifact>*:*</artifact> <excludes> <!-- zip -d learn_spark.jar META-INF/*.RSA META-INF/*.DSA META-INF/*.SF --> <exclude>META-INF/*.SF</exclude> <exclude>META-INF/*.DSA</exclude> <exclude>META-INF/*.RSA</exclude> </excludes> </filter> </filters> <transformers> <transformer implementation="org.apache.maven.plugins.shade.resource.ManifestResourceTransformer"> <mainClass>com.itheima.batch.BatchFromCollection</mainClass> </transformer> </transformers> </configuration> </execution> </executions> </plugin> <plugin> <groupId>org.apache.maven.plugins</groupId> <artifactId>maven-jar-plugin</artifactId> <version>2.6</version> <configuration> <archive> <manifest> <addClasspath>true</addClasspath> <classpathPrefix>lib/</classpathPrefix> <mainClass>com.itheima.env.BatchRemoteEven</mainClass> </manifest> </archive> </configuration> </plugin> <plugin> <groupId>org.apache.maven.plugins</groupId> <artifactId>maven-dependency-plugin</artifactId> <version>2.10</version> <executions> <execution> <id>copy-dependencies</id> <phase>package</phase> <goals> <goal>copy-dependencies</goal> </goals> <configuration> <outputDirectory>${project.build.directory}/lib</outputDirectory> </configuration> </execution> </executions> </plugin> </plugins> </build> </project>
2、批处理DataSource
2.1、本地集合的source
import org.apache.flink.api.scala._ import scala.collection.mutable import scala.collection.mutable.{ArrayBuffer, ListBuffer} /** * 读取集合中的批次数据 */ object BatchFromCollection { def main(args: Array[String]): Unit = { //获取flink的执行环境 val env = ExecutionEnvironment.getExecutionEnvironment //导入隐式转换 import org.apache.flink.api.scala._ //0.用element创建DataSet(fromElements) val ds0: DataSet[String] = env.fromElements("spark", "flink") ds0.writeAsText("data1.txt") //1.用Tuple创建DataSet(fromElements) val ds1: DataSet[(Int, String)] = env.fromElements((1, "spark"), (2, "flink")) ds1.print() //2.用Array创建DataSet val ds2: DataSet[String] = env.fromCollection(Array("spark", "flink")) ds2.print() //3.用ArrayBuffer创建DataSet val ds3: DataSet[String] = env.fromCollection(ArrayBuffer("spark", "flink")) ds3.print() //4.用List创建DataSet val ds4: DataSet[String] = env.fromCollection(List("spark", "flink")) ds4.print() //5.用List创建DataSet val ds5: DataSet[String] = env.fromCollection(ListBuffer("spark", "flink")) ds5.print() //6.用Vector创建DataSet val ds6: DataSet[String] = env.fromCollection(Vector("spark", "flink")) ds6.print() //7.用Queue创建DataSet val ds7: DataSet[String] = env.fromCollection(mutable.Queue("spark", "flink")) ds7.print() //8.用Stack创建DataSet val ds8: DataSet[String] = env.fromCollection(mutable.Stack("spark", "flink")) ds8.print() //9.用Stream创建DataSet(Stream相当于lazy List,避免在中间过程中生成不必要的集合) val ds9: DataSet[String] = env.fromCollection(Stream("spark", "flink")) ds9.print() //10.用Seq创建DataSet val ds10: DataSet[String] = env.fromCollection(Seq("spark", "flink")) ds10.print() //11.用Set创建DataSet val ds11: DataSet[String] = env.fromCollection(Set("spark", "flink")) ds11.print() //12.用Iterable创建DataSet val ds12: DataSet[String] = env.fromCollection(Iterable("spark", "flink")) ds12.print() //13.用ArraySeq创建DataSet val ds13: DataSet[String] = env.fromCollection(mutable.ArraySeq("spark", "flink")) ds13.print() //14.用ArrayStack创建DataSet val ds14: DataSet[String] = env.fromCollection(mutable.ArrayStack("spark", "flink")) ds14.print() //15.用Map创建DataSet val ds15: DataSet[(Int, String)] = env.fromCollection(Map(1 -> "spark", 2 -> "flink")) ds15.print() //16.用Range创建DataSet val ds16: DataSet[Int] = env.fromCollection(Range(1, 9)) ds16.print() //17.用fromElements创建DataSet val ds17: DataSet[Long] = env.generateSequence(1, 9) ds17.print() } }
2.2、基于文件的source
import org.apache.flink.api.scala.ExecutionEnvironment /** * * 读取文件中的批次数据 * */ object BatchFromFile { // 用于映射CSV文件的样例类 case class Student(id:Int, name:String) def main(args: Array[String]): Unit = { //初始化环境 val environment = ExecutionEnvironment.getExecutionEnvironment //加载本地数据 val datas = environment.readTextFile("./data/data.txt") //读取压缩文件 //val datas = environment.readTextFile("./data/data.tar.gz") //加载hdfs数据 //val datas = environment.readTextFile("hdfs://master-100:8020/README.txt") //读取CSV数据 //val datas = environment.readCsvFile[Student]("./data/subject.csv") //出发程序执行 datas.print() } }
2.3、遍历目录
import org.apache.flink.api.scala.ExecutionEnvironment import org.apache.flink.configuration.Configuration /** * * 遍历目录的批次数据 * */ object BatchFromFolder { def main(args: Array[String]): Unit = { //初始化环境 val env = ExecutionEnvironment.getExecutionEnvironment val parameters = new Configuration //recursive.file.enumeration 开启递归 parameters.setBoolean("recursive.file.enumeration",true) val result = env.readTextFile("./data").withParameters(parameters) //触发执行程序 result.print() } }
3、Flink批处理Transformation
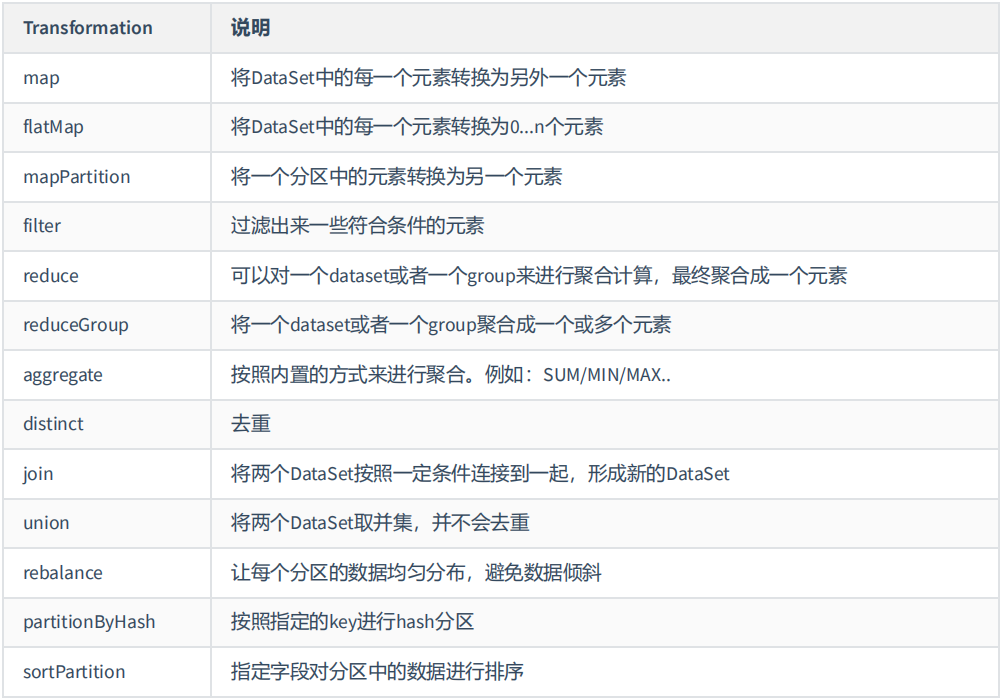
3.1、map
import org.apache.flink.api.scala._ /** * map练习 * 1. 获取 ExecutionEnvironment 运行环境 * 2. 使用 fromCollection 构建数据源 * 3. 创建一个 User 样例类 * 4. 使用 map 操作执行转换 * 5. 打印测试 * */ object BatchMapPract { //User样例类 case class User(id:String,name:String) def main(args: Array[String]): Unit = { //初始化环境 val env = ExecutionEnvironment.getExecutionEnvironment val textDataSet = env.fromCollection(List("1,张三", "2,李四", "3,王五", "4,赵六")) //map函数,将DataSet中的每一个元素转换为另外一个元素 val userDataSet = textDataSet.map{ text=> val fieldArr = text.split(",") User(fieldArr(0),fieldArr(1)) } userDataSet.print() } }
3.2、flatmap
import org.apache.flink.api.scala._ /** * flatmap练习 *1. 构建批处理运行环境 * 2. 构建本地集合数据源 * 3. 使用 flatMap 将一条数据转换为三条数据 * 4. 打印输出 * (张三,中国) * (张三,中国,江西省) * (张三,中国,江西省,江西省) * (李四,中国) * (李四,中国,河北省) * (李四,中国,河北省,河北省) * (Tom,America) * (Tom,America,NewYork) * (Tom,America,NewYork,NewYork) * */ object BatchFlatmapPract { def main(args: Array[String]): Unit = { //构建批处理运行环境 val env = ExecutionEnvironment.getExecutionEnvironment //构建本地集合数据源 val userDataSet = env.fromCollection(List( "张三,中国,江西省,南昌市", "李四,中国,河北省,石家庄市", "Tom,America,NewYork,Manhattan" )) //使用`flatMap`将一条数据转换为三条数据 val resultDataSet = userDataSet.flatMap{ text => // - 使用逗号分隔字段 val fieldArr = text.split(",") //- 分别构建国家、国家省份、国家省份城市三个元组 List( (fieldArr(0),fieldArr(1)),// 构建国家维度数据 (fieldArr(0),fieldArr(1)+fieldArr(2)),// 构建省份维度数据 (fieldArr(0),fieldArr(1)+fieldArr(2)+fieldArr(3))// 构建城市维度数据 ) } //打印 resultDataSet.print() } }
3.3、mapPartition
import org.apache.flink.api.scala._ /** * mapPartition * map 和 mapPartition 的效果是一样的,但如果在map的函数中,需要访问一些外部存储。例如: * 访问mysql数据库,需要打开连接 , 此时效率较低。而使用 mapPartition 可以有效减少连接数,提高效率 * */ object BatchMappartitionPract { // 创建一个`User`样例类 case class User(id:String,name:String) def main(args: Array[String]): Unit = { // 获取`ExecutionEnvironment`运行环境 val env = ExecutionEnvironment.getExecutionEnvironment // 使用`fromCollection`构建数据源 val userDataSet = env.fromCollection(List("1,张三","2,李四","3,王五","4,赵六")) // 使用`mapPartition`操作执行转换 val resultDataSet = userDataSet.mapPartition{ iter => //TODO:打开连接 // 对迭代器执行转换操作 iter.map{ ele => val fieldArr = ele.split(",") User(fieldArr(0),fieldArr(1)) } // TODO:关闭连接 } //打印 resultDataSet.print() } }
3.4、filter
import org.apache.flink.api.scala._ /** * filter函数练习 * * */ object BatchFilterPract { def main(args: Array[String]): Unit = { //获取`ExecutionEnvironment`运行环境 val env = ExecutionEnvironment.getExecutionEnvironment //使用`fromCollection`构建数据源 val worldDataSet = env.fromCollection(List("hadoop","hive","spark","flink")) //使用`filter`操作执行过滤 val resultDataSet = worldDataSet.filter(_.startsWith("h")) //打印测试 resultDataSet.print() } }
3.5、reduce
import org.apache.flink.api.scala._ /** *reduce聚合练习 */ object BatchReducePract { def main(args: Array[String]): Unit = { //获取`ExecutionEnvironment`运行环境 val env = ExecutionEnvironment.getExecutionEnvironment //使用`fromCollection`构建数据源 val worldCountDataSet = env.fromCollection(List(("java",1),("java",1),("java",1),("python",2),("python",3))) //使用`groupBy`按照单词进行分组 val groupedDataSet: GroupedDataSet[(String, Int)] = worldCountDataSet.groupBy(_._1) //使用`redice`执行聚合操作 val resultDataSet = groupedDataSet.reduce{ (wc1,wc2) => (wc2._1,wc1._2+wc2._2) } //打印测试 resultDataSet.print() } }
3.6、reduceGroup
import org.apache.flink.api.scala._ /** * reduceGroup聚合函数练习 * reduce是将数据一个个拉取到另外一个节点,然后再执行计算 * reduceGroup是先在每个group所在的节点上执行计算,然后再拉取 */ object BatchReduceGroupPract { def main(args: Array[String]): Unit = { // 获取`ExecutionEnvironment`运行环境 val env = ExecutionEnvironment.getExecutionEnvironment //使用`fromCollection`构建数据源 val worldDataSet = env.fromCollection(List(("java",1),("java",1),("java",1),("python",2),("python",3))) // 使用`groupBy`按照单词进行分组 val groupDataSet = worldDataSet.groupBy(_._1) //使用`reduceGroup`对每个分组进行统计 val resultDataSet = groupDataSet.reduceGroup{ iter => iter.reduce{ (wc1,wc2) => (wc1._1,wc2._2+wc1._2) } } //打印测试 resultDataSet.print() } }
3.7、aggregate
import org.apache.flink.api.java.aggregation.Aggregations import org.apache.flink.api.scala._ /** * 内置aggregate函数练习 *按照内置的方式来进行聚合, Aggregate只能作用于 元组 上。例如:SUM/MIN/MAX... * 要使用aggregate,只能使用字段索引名或索引名称来进行分组 groupBy(0) ,否则会报错误 */ object BatchAggregatePract { def main(args: Array[String]): Unit = { //获取`ExecutionEnvironment`运行环境 val env = ExecutionEnvironment.getExecutionEnvironment //使用`fromCollection`构建数据源 val worldDataSet = env.fromCollection(List(("java",1),("java",1),("java",1),("python",2),("python",3))) //使用`groupBy`按照单词进行分组 val groupedDataSet = worldDataSet.groupBy(0) //使用`aggregate`对每个分组进行`SUM`统计 val resultDataSet = groupedDataSet.aggregate(Aggregations.SUM,1) //打印测试 resultDataSet.print() } }
3.8、distinct
import org.apache.flink.api.scala._ /** * distinct函数练习 */ object BatchDistinctPract { def main(args: Array[String]): Unit = { //获取`ExecutionEnvironment`运行环境 val env = ExecutionEnvironment.getExecutionEnvironment //使用`fromCollection`构建数据源 val worldDataSet = env.fromCollection(List(("java",1),("java",1),("java",1),("python",2),("python",3))) //使用`distinct`指定按照哪个字段来进行去重 val resultDataSet = worldDataSet.distinct(0) // 打印测试 resultDataSet.print() } }
3.9、join
import org.apache.flink.api.scala._ /** * join练习 * */ object BatchJoinPract { //学科Subject(学科ID、学科名字) case class Subject(id:Int,name:String) //成绩Score(唯一ID、学生姓名、学科ID、分数) case class Score(id:Int,name:String,subjectId:Int,Score:Double) def main(args: Array[String]): Unit = { //获取`ExecutionEnvironment`运行环境 val env = ExecutionEnvironment.getExecutionEnvironment //分别使用`readCsvFile`加载csv数据源 val scoreDataSet = env.readCsvFile[Score]("./data/score.csv") val subjectDataSet = env.readCsvFile[Subject]("./data/subject.csv") //使用join连接两个DataSet,并使用`where`、`equalTo`方法设置关联条件 val joinDataSet = scoreDataSet.join(subjectDataSet).where(2).equalTo(0) //打印关联后的数据源 joinDataSet.print() } }
score.csv
1,张三,1,98
2,张三,2,77.5
3,张三,3,89
4,张三,4,65
5,张三,5,78
6,张三,6,70
7,李四,1,78
8,李四,2,58
9,李四,3,65
10,李四,4,78
11,李四,5,70
12,李四,6,78
13,王五,1,70
14,王五,2,78
15,王五,3,58
16,王五,4,65
17,王五,5,78
18,王五,6,98
19,赵六,1,77.5
20,赵六,2,89
21,赵六,3,65
22,赵六,4,78
23,赵六,5,70
24,赵六,6,78
25,小七,1,78
26,小七,2,70
27,小七,3,78
28,小七,4,58
29,小七,5,65
30,小七,6,78
subject.csv
1,语文
2,数学
3,英语
4,物理
5,化学
6,生物
3.10、union
import org.apache.flink.api.scala._ /** * union函数练习 * 将两个DataSet取并集,不会去重 */ object BatchUnionPract { def main(args: Array[String]): Unit = { //获取`ExecutionEnvironment`运行环境 val env = ExecutionEnvironment.getExecutionEnvironment //使用`fromCollection`创建两个数据源 val worldDataSet1 = env.fromCollection(List("hadoop","hive","flum")) val worldDataSet2 = env.fromCollection(List("hadoop","hive","spark")) //使用`union`将两个数据源关联在一起 val resultDataSet = worldDataSet1.union(worldDataSet2) //打印测试 resultDataSet.print() } }
3.11、rebalance
import org.apache.flink.api.common.functions.RichMapFunction import org.apache.flink.api.scala._ /** * rebalance会使用轮询的方式将数据均匀打散,这是处理数据倾斜最好的选择 * */ object BatchRebalancePract { def main(args: Array[String]): Unit = { //获取`ExecutionEnvironment`运行环境 val env = ExecutionEnvironment.getExecutionEnvironment //使用`env.generateSequence`创建0-100的并行数据 val numDataSet = env.generateSequence(0,100) //使用`fiter`过滤出来`大于8`的数字,在filter计算完后,调用 rebalance ,这样,就会均匀地将数据分布到每一个分区中。 val filterDataSet = numDataSet.filter(_ > 8).rebalance() //使用map操作传入`RichMapFunction`,将当前子任务的ID和数字构建成一个元组 val resultDataSet = filterDataSet.map( new RichMapFunction[Long, (Long, Long)] { override def map(in: Long): (Long, Long) = { (getRuntimeContext.getIndexOfThisSubtask, in) } }) resultDataSet.print() } }
3.12、hashPartition
import org.apache.flink.api.scala._ /** * partitionByHash,按照指定的key进行hash分区 * */ object BatchHashPartition { def main(args: Array[String]): Unit = { //获取`ExecutionEnvironment`运行环境 val env = ExecutionEnvironment.getExecutionEnvironment //设置并行度为`2` env.setParallelism(2) //使用`fromCollection`构建测试数据集 val numDataSet = env.fromCollection(List(1,1,1,1,1,1,1,2,2,2,2,2)) // 使用`partitionByHash`按照字符串的hash进行分区 val partitionDataSet = numDataSet.partitionByHash(_.toString) // 4. 调用`writeAsText`写入文件到`data/parition_output`目录中 partitionDataSet.writeAsText("./data/parition_output") partitionDataSet.print() } }
3.13、sortPartition
import org.apache.flink.api.common.operators.Order import org.apache.flink.api.scala._ /** * sortPartition指定字段对分区中的数据进行排序 */ object BatchSortPartitionPract { def main(args: Array[String]): Unit = { //获取`ExecutionEnvironment`运行环境 val env = ExecutionEnvironment.getExecutionEnvironment //使用`fromCollection`构建测试数据集 val worldDataSet = env.fromCollection(List("hadoop", "hadoop", "hadoop", "hive", "hive","spark", "spark", "flink")) //设置数据集的并行度为`2` worldDataSet.setParallelism(2) //使用`sortPartition`按照字符串进行降序排序 val sorteDataSet = worldDataSet.sortPartition(_.toString,Order.DESCENDING) //调用`writeAsText`写入文件到`data/sort_output`目录中 sorteDataSet.writeAsText("./data/sort_output/") //启动执行 env.execute("App") } }
4、Flink批处理Sink
4.1、基于本地集合的sink
import org.apache.flink.api.scala._ /** *sink *基于下列数据,分别 进行打印输出,error输出,collect() * (19, "zhangsan", 178.8), * (17, "lisi", 168.8), * (18, "wangwu", 184.8), * (21, "zhaoliu", 164.8) */ object BatchSinkCollection { def main(args: Array[String]): Unit = { //初始化环境 val env = ExecutionEnvironment.getExecutionEnvironment //定义数据 stu(age,name,height) val stu = env.fromElements( (19,"zhangsan",178.8), (17,"lisi",168.8), (18,"wangwu",184.8), (21,"zhaoliu",164.8) ) //TODO sink到标准输出 stu.print() //TODO sink到标准error输出 stu.printToErr() //TODO sink到本地Collection println(stu.collect()) env.execute() } }
4.2、sink到文件
import org.apache.flink.api.scala._ import org.apache.flink.core.fs.FileSystem.WriteMode /** * 将数据写入文件 */ object BatchSinkFile { def main(args: Array[String]): Unit = { //初始化环境 val env = ExecutionEnvironment.getExecutionEnvironment //定义数据 val ds1 = env.fromElements(Map(1 -> "spark",2 -> "flink")) //TODO 写入到本地,文本文档,NO_OVERWRITE模式下如果文件已经存在,则报错,OVERWRITE模式下如果文件已经存在,则覆盖 ds1.setParallelism(1).writeAsText("./data/aa", WriteMode.OVERWRITE) //TODO 写入到hdfs,文本文档,NO_OVERWRITE模式下如果文件已经存在,则报错,OVERWRITE模式下如果文件已经存在,则覆盖 ds1.setParallelism(1).writeAsText("hdfs://master:9000/a", WriteMode.OVERWRITE) env.execute() } }
5、Flink的广播变量
import org.apache.flink.api.common.functions.RichMapFunction import org.apache.flink.api.scala._ import org.apache.flink.configuration.Configuration /** * 广播变量 * 1. 广播出去的变量存放在每个节点的内存中,直到程序结束,这个数据集不能太大 * 2. withBroadcastSet 需要在要使用到广播的操作后调用 * 3. 需要手动导入 scala.collection.JavaConverters._ 将Java集合转换为scala集合 */ object BroadCast { def main(args: Array[String]): Unit = { //获取`ExecutionEnvironment`运行环境 val env = ExecutionEnvironment.getExecutionEnvironment //分别创建两个数据集 val stuDataSet = env.fromCollection(List((1,"张三"),(2,"李四"),(3,"王五"))) val scoreDataSet = env.fromCollection(List((1,"语文",50),(2,"数学",70),(3,"英文",86))) //使用`RichMapFunction`对`成绩`数据集进行map转换 //将成绩数据(学生ID,学科,成绩) -> (学生姓名,学科,成绩) val resultDataSet = scoreDataSet.map(new RichMapFunction[(Int,String,Int),(String,String,Int)] { var bc_studentList: List[(Int, String)] = null //重写`open`方法中,获取广播数据 override def open(parameters: Configuration): Unit = { import scala.collection.JavaConverters._ bc_studentList=getRuntimeContext.getBroadcastVariable[(Int, String)]("bc_student").asScala.toList } //在`map`方法中使用广播进行转换 override def map(value: (Int, String, Int)): (String, String, Int) = { //获取学生ID val studentId = value._1 //过滤出和学生ID相同的内容 val tuples = bc_studentList.filter( x => x._1 == studentId ) //构建元组 (tuples(0)._2,value._2,value._3) } }).withBroadcastSet(stuDataSet,"bc_student") //打印测试 resultDataSet.print() } }
6、Flink的累加器
import org.apache.flink.api.common.accumulators.IntCounter import org.apache.flink.api.common.functions.RichMapFunction import org.apache.flink.api.scala._ import org.apache.flink.configuration.Configuration /** * counter 累加器 * Flink Broadcast和Accumulators的区别 * Broadcast(广播变量)允许程序员将一个只读的变量缓存在每台机器上,而不用在任务之间传递变量。广播变量 * 可以进行共享,但是不可以进行修改 * Accumulators(累加器)是可以在不同任务中对同一个变量进行累加操作 */ object BatchCounterPract { def main(args: Array[String]): Unit = { //初始化环境 val env = ExecutionEnvironment.getExecutionEnvironment val data = env.fromElements("a","b","c","d") val res = data.map(new RichMapFunction[String,String] { //定义累加器 val numLines = new IntCounter() override def open(parameters: Configuration): Unit = { super.open(parameters) //注册累加器 getRuntimeContext.addAccumulator("num-lines",this.numLines) } var sum =0 override def map(value: String): String = { //如果并行度为1,使用普通的累加求和即可,但是设置多个并行度,则普通的累加求和结果就不准了 sum +=1 System.out.println("sum:"+sum) this.numLines.add(1) value } }).setParallelism(1) res.writeAsText("./data/count0") val jobResult = env.execute("BatchCounterPractScala") //获取累加器 val num = jobResult.getAccumulatorResult("num-lines") println("num:"+num) } }
7、Flink的分布式缓存
import org.apache.commons.io.FileUtils import org.apache.flink.api.common.functions.RichMapFunction import org.apache.flink.api.scala._ import org.apache.flink.configuration.Configuration /** * flink的分布式缓存 * */ object BatchDisCachePract { def main(args: Array[String]): Unit = { //初始化环境 val env = ExecutionEnvironment.getExecutionEnvironment //注册文件 env.registerCachedFile("data/a.txt","b.txt") //读取数据 val data = env.fromElements("a","b","c","d") val result = data.map(new RichMapFunction[String,String] { override def open(parameters: Configuration): Unit = { super.open(parameters) //访问数据 val myFile = getRuntimeContext.getDistributedCache.getFile("b.txt") val lines = FileUtils.readLines(myFile) val it = lines.iterator() while (it.hasNext){ val line = it.next() println("line:"+line) } } override def map(value: String): String = { value } }) result.print() } }
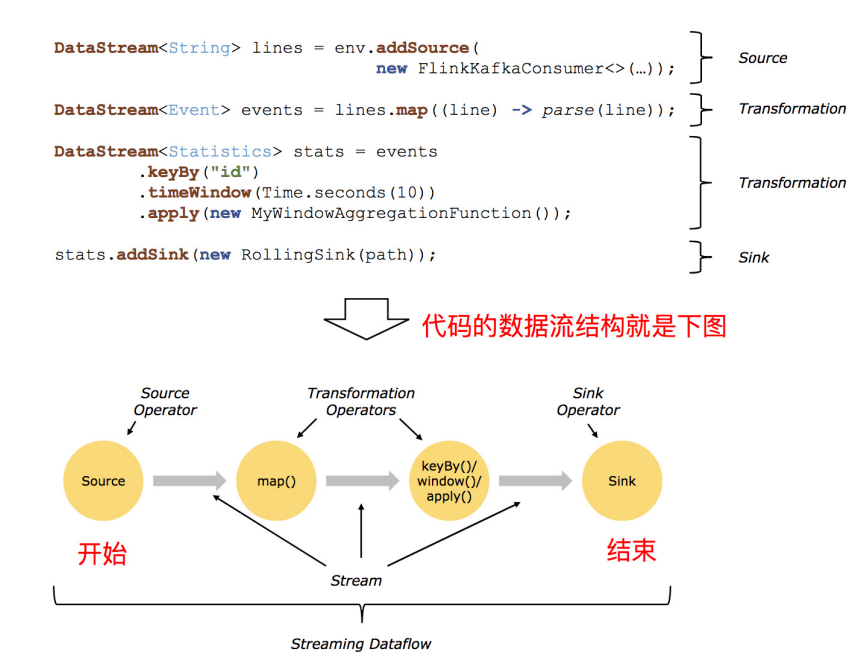
五、Flink流处理
1、输入数据集DataSource
Flink 中你可以使用 StreamExecutionEnvironment.getExecutionEnvironment 创建流处理的执行环境,Flink 中你可以使用 StreamExecutionEnvironment.addSource(source)来为你的程序添加数据来源。Flink 已经提供了若干实现好了的 source functions,当然你也可以通过实现 SourceFunction 来自定义非并行的source或者实现 ParallelSourceFunction 接口或者扩展 RichParallelSourceFunction 来自定义并行的source。
Flink在流处理上的source和在批处理上的source基本一致。大致有4大类:
- 基于本地集合的source(Collection-based-source)
- 基于文件的source(File-based-source)- 读取文本文件,即符合 TextInputFormat 规范的文件,并将其作为字符串返回
- 基于网络套接字的source(Socket-based-source)- 从 socket 读取。元素可以用分隔符切分。
- 自定义的source(Custom-source)
1.1、基于集合的source
import org.apache.flink.streaming.api.scala._ import scala.collection.immutable.{Queue, Stack} import scala.collection.mutable import scala.collection.mutable.{ArrayBuffer, ListBuffer} /** * 流处理基于集合的source * */ object StreamFromCollection { def main(args: Array[String]): Unit = { val senv = StreamExecutionEnvironment.getExecutionEnvironment //0.用element创建DataStream(fromElements) val ds0 = senv.fromElements("spark","flink") ds0.print() //1.用Tuple创建DataStream(fromElements) val ds1: DataStream[(Int, String)] = senv.fromElements((1, "spark"), (2, "flink")) ds1.print() //2.用Array创建DataStream val ds2: DataStream[String] = senv.fromCollection(Array("spark", "flink")) ds2.print() //3.用ArrayBuffer创建DataStream val ds3: DataStream[String] = senv.fromCollection(ArrayBuffer("spark", "flink")) ds3.print() //4.用List创建DataStream val ds4: DataStream[String] = senv.fromCollection(List("spark", "flink")) ds4.print() //5.用List创建DataStream val ds5: DataStream[String] = senv.fromCollection(ListBuffer("spark", "flink")) ds5.print() //6.用Vector创建DataStream val ds6: DataStream[String] = senv.fromCollection(Vector("spark", "flink")) ds6.print() //7.用Queue创建DataStream val ds7: DataStream[String] = senv.fromCollection(Queue("spark", "flink")) ds7.print() //8.用Stack创建DataStream val ds8: DataStream[String] = senv.fromCollection(Stack("spark", "flink")) ds8.print() //9.用Stream创建DataStream(Stream相当于lazy List,避免在中间过程中生成不必要的集合) val ds9: DataStream[String] = senv.fromCollection(Stream("spark", "flink")) ds9.print() //10.用Seq创建DataStream val ds10: DataStream[String] = senv.fromCollection(Seq("spark", "flink")) ds10.print() //11.用Set创建DataStream(不支持) //val ds11: DataStream[String] = senv.fromCollection(Set("spark", "flink")) //ds11.print() //12.用Iterable创建DataStream(不支持) //val ds12: DataStream[String] = senv.fromCollection(Iterable("spark", "flink")) //ds12.print() //13.用ArraySeq创建DataStream val ds13: DataStream[String] = senv.fromCollection(mutable.ArraySeq("spark", "flink")) ds13.print() //14.用ArrayStack创建DataStream val ds14: DataStream[String] = senv.fromCollection(mutable.ArrayStack("spark", "flink")) ds14.print() //15.用Map创建DataStream(不支持) //val ds15: DataStream[(Int, String)] = senv.fromCollection(Map(1 -> "spark", 2 ->"flink")) //ds15.print() //16.用Range创建DataStream val ds16: DataStream[Int] = senv.fromCollection(Range(1, 9)) ds16.print() //17.用fromElements创建DataStream val ds17: DataStream[Long] = senv.generateSequence(1, 9) ds17.print() senv.execute(this.getClass.getName) } }
1.2、基于文件的source
object DataSource_CSV { def main(args: Array[String]): Unit = { // 1. 获取流处理运行环境 val env = StreamExecutionEnvironment.getExecutionEnvironment // 2. 读取文件 val textDataStream = env.readTextFile("./datas/score.csv") // 3. 打印数据 textDataStream.print() // 4. 执行程序 env.execute() } }
1.3、基于网络套接字的source
import org.apache.flink.streaming.api.scala._ /** * 基于网络套接字的source *注:在Linux中,使用 nc -lk 端口号 监听端口,并发送单词 * 安装nc: yum install -y nc * nc -lk 9999 监听9999端口的信息 */ object StreamSocketSource { def main(args: Array[String]): Unit = { //获取流处理运行环境 val senv = StreamExecutionEnvironment.getExecutionEnvironment // 2. 构建socket流数据源,并指定IP地址和端口号 // hadoop hadoop hive spark val socketDataStream = senv.socketTextStream("192.168.116.90",9999) //转换,以空格拆分单词 val mapDataSet = socketDataStream.flatMap(_.split(" ")) //打印输出 mapDataSet.print() // 启动执行 senv.execute(this.getClass.getName) } }
1.4、自定义source
import java.util.UUID import java.util.concurrent.TimeUnit import org.apache.flink.streaming.api.functions.source.{RichSourceFunction, SourceFunction} import org.apache.flink.streaming.api.scala._ import scala.util.Random /** * 自定义数据源 * */ object StreamZdySource { //创建一个订单样例类Order,包含四个字段(订单ID、用户ID、订单金额、时间戳) case class Order(id:String,userId:Int,money:Long,createTime:Long) def main(args: Array[String]): Unit = { //获取流处理运行环境 val senv = StreamExecutionEnvironment.getExecutionEnvironment val orderDataStream = senv.addSource(new RichSourceFunction[Order] { override def run(sourceContext: SourceFunction.SourceContext[Order]): Unit = { //使用for循环生成1000个订单 for (i <- 0 until 100){ //随机生成订单ID(UUID) val id = UUID.randomUUID().toString //随机生成用户ID(0-2) val userId = Random.nextInt(3) //随机生成订单金额(0-100) val money = Random.nextInt(101) //时间戳为当前系统时间 val timestamp = System.currentTimeMillis() //收集数据 sourceContext.collect(Order(id,userId,money,timestamp)) //每隔1秒生成一个订单 TimeUnit.SECONDS.sleep(1) } } override def cancel(): Unit = () }) //打印数据 orderDataStream.print() //执行程序 senv.execute() } }
1.5、使用Kafka作为数据源
import java.util.Properties import org.apache.flink.api.common.serialization.SimpleStringSchema import org.apache.flink.streaming.api.scala.{DataStream, StreamExecutionEnvironment} import org.apache.flink.streaming.connectors.kafka.{FlinkKafkaConsumer} import org.apache.kafka.clients.CommonClientConfigs import org.apache.flink.api.scala._ /** * 使用Kafka作为数据源 * Kafka相关操作: * 创建topic * kafka-topics.sh --create --partitions 1 --replication-factor 1 --topic kafkatopic --zookeeper master-90:2181 * 模拟生产者 * kafka-console-producer.sh --broker-list master-90:9092 --topic kafkatopic * 模拟消费者 * kafka-console-consumer.sh --from-beginning --bootstrap-server master-90:9092 --topic kafkatopic */ object StreamKafkaSource { def main(args: Array[String]): Unit = { // 1. 创建流式环境 val senv = StreamExecutionEnvironment.getExecutionEnvironment // 非常关键,一定要设置启动检查点!! //senv.enableCheckpointing(5000); //senv.setStreamTimeCharacteristic(TimeCharacteristic.EventTime); //2 .指定kafak相关信息 //指定kafka数据流的相关信息 val kafkaCluster = "192.168.116.90:9092" val kafkaTopic = "kafkatopic" // 3. 创建Kafka数据流 val props = new Properties() props.setProperty(CommonClientConfigs.BOOTSTRAP_SERVERS_CONFIG,kafkaCluster) val kafka = new FlinkKafkaConsumer[String](kafkaTopic,new SimpleStringSchema(),props) //4 .添加数据源addSource val text: DataStream[String] = senv.addSource(kafka) // 5. 打印数据 text.print() // 6.执行任务 senv.execute() } }
1.6、使用mysql作为数据源
import java.sql.DriverManager import org.apache.flink.streaming.api.functions.source.{RichSourceFunction, SourceFunction} import org.apache.flink.streaming.api.scala._ /** * 使用MySQL作为数据源 * 1. 自定义Source,继承自RichSourceFunction * 2. 实现run方法 * 1). 加载驱动 * 2). 创建连接 * 3). 创建PreparedStatement * 4). 执行查询 * 5). 遍历查询结果,收集数据 * 3. 使用自定义Source * 4. 打印结果 * 5. 执行任务 */ object StreamMysqlSource { def main(args: Array[String]): Unit = { //创建流处理环境 val senv = StreamExecutionEnvironment.getExecutionEnvironment //设置并行度 senv.setParallelism(1) //添加自定义MySql数据源 val source = senv.addSource(new MySql_source) //打印结果 source.print() // 执行任务 senv.execute() } class MySql_source extends RichSourceFunction[(Int,String,String,String)]{ override def run(sourceContext: SourceFunction.SourceContext[(Int, String, String, String)]): Unit = { //加载MySql驱动 Class.forName("com.mysql.jdbc.Driver") //链接MySql var connect = DriverManager.getConnection("jdbc:mysql://192.168.116.102/test","root","123456") //创建PreparedStatement val sql = "select id,username,password,name from user" var ps = connect.prepareStatement(sql) //执行Sql查询 val queryRequest = ps.executeQuery() //遍历结果 while (queryRequest.next()){ val id = queryRequest.getInt("id") val username = queryRequest.getString("username") val password = queryRequest.getString("password") val name = queryRequest.getString("name") //收集数据 sourceContext.collect(id,username,password,name) } } override def cancel(): Unit = {} } }
2、DataStream的Transformation
import org.apache.flink.streaming.api.scala._ /** * KeyBy算子的使用 */ object StreamTransKeyBy { def main(args: Array[String]): Unit = { //获取流处理运行环境 val senv = StreamExecutionEnvironment.getExecutionEnvironment //设置并行度 senv.setParallelism(3) //获取Socket数据源 val stream = senv.socketTextStream("192.168.116.90",9999,'\n') //转换操作,以空格切分,每个元素计数1,以单词分组,累加 val text = stream.flatMap(_.split("\\s")) .map((_,1)) //TODO 逻辑上将一个流分成不相交的分区,每个分区包含相同键的元素。在内部,这是通过散列分区来实现的 .keyBy(_._1) //TODO 这里的sum并不是分组去重后的累加值,如果统计去重后累加值,则使用窗口函数 .sum(1) //打印到控制台 text.print() //执行任务 senv.execute() } }
2.2、Connect
import java.util.concurrent.TimeUnit import org.apache.flink.streaming.api.functions.source.SourceFunction import org.apache.flink.streaming.api.scala._ /** * Connect用来将两个DataStream组装成一个 ConnectedStreams 。它用了两个泛型,即不要求两个dataStream的 * element是同一类型。这样我们就可以把不同的数据组装成同一个结构 */ object StreamTransConnect { def main(args: Array[String]): Unit = { //创建流式处理环境 val senv = StreamExecutionEnvironment.getExecutionEnvironment // 添加两个自定义数据源 val text1 = senv.addSource(new MyLongSourceScala) val text2 = senv.addSource(new MyStringSourceScala) //使用connect合并两个数据流,创建ConnectedStreams对象 val connectedStream = text1.connect(text2) //遍历ConnectedStreams对象,转换为DataStream val result = connectedStream.map( line1 => line1 ,line2 => line2) // 打印输出,设置并行度为1 result.print().setParallelism(1) //执行任务 senv.execute() } /** * 创建自定义并行度为1的source * 实现从1开始产生递增数字 */ class MyLongSourceScala extends SourceFunction[Long]{ var count = 1L var isRunning = true override def run(sourceContext: SourceFunction.SourceContext[Long]): Unit = { while (isRunning){ sourceContext.collect(count) count +=1 TimeUnit.SECONDS.sleep(1) } } override def cancel(): Unit = { isRunning = false } } /** * 创建自定义并行度为1的source * 实现从1开始产生递增字符串 */ class MyStringSourceScala extends SourceFunction[String]{ var count = 1L var isRunning = true override def run(sourceContext: SourceFunction.SourceContext[String]): Unit = { while(isRunning){ sourceContext.collect("str"+count) count +=1 TimeUnit.SECONDS.sleep(1) } } override def cancel(): Unit = { isRunning = false } } }
2.3、split和select
import org.apache.flink.streaming.api.scala._ /** * 演示Split和Select方法 * Split: DataStream->SplitStream * Select: SplitStream->DataStream */ object StreamTransSplitAndSelect { def main(args: Array[String]): Unit = { //初始化环境 val senv = StreamExecutionEnvironment.getExecutionEnvironment //设置并行度 senv.setParallelism(1) //加载本地集合 val elements = senv.fromElements(1,2,3,4,5,6,7) //数据分流,分为奇数和偶数,在后期版本中split将会不支持,替代的是sideoutput val splitData = elements.split( num => num %2 match{ case 0 => List("even") case 1 => List("odd") } ) //获取分流后的数据 val even = splitData.select("even") val odd = splitData.select("odd") val all = splitData.select("even","odd") //打印数据 odd.print() //执行任务 senv.execute() } }
2.4、side output分流
//待补充
3、Flink在流处理上常见的sink
import org.apache.flink.api.common.serialization.SimpleStringSchema import org.apache.flink.streaming.api.scala._ import org.apache.flink.streaming.connectors.kafka.FlinkKafkaProducer import streaming.StreamMysqlSource.MySql_source /** * sink到kafka * 读取MySql的数据, 落地到Kafka中 */ object StreamSinkKafka { def main(args: Array[String]): Unit = { // 创建流处理环境 val senv = StreamExecutionEnvironment.getExecutionEnvironment //设置并行度 senv.setParallelism(1) //添加自定义MySql数据源 val source = senv.addSource(new MySql_source) //转换元组数据为字符串 val strDataStream = source.map( line => line._1+line._2+line._3+line._4 ) // 构建FlinkKafkaProducer strDataStream.addSink(new FlinkKafkaProducer[String]("192.168.116.90:9092","kafkatopic",new SimpleStringSchema())) senv.execute() } }
3.2、Sink到MySQL
import java.sql.{Connection, DriverManager, PreparedStatement} import org.apache.flink.configuration.Configuration import org.apache.flink.streaming.api.functions.sink.RichSinkFunction import org.apache.flink.streaming.api.scala._ /** * sink到mysql * */ object StreamSinkMysql { def main(args: Array[String]): Unit = { //1.创建流执行环境 val env = StreamExecutionEnvironment.getExecutionEnvironment //2.准备数据 val value: DataStream[(Int, String, String, String)] = env.fromCollection(List( (10, "dazhuang", "123456", "大壮"), (11, "erya", "123456", "二丫"), (12, "sanpang", "123456", "三胖"))) // 3. 添加sink value.addSink(new MySql_Sink) //4.触发流执行 env.execute() } } // 自定义落地MySql的Sink class MySql_Sink extends RichSinkFunction[(Int, String, String, String)] { private var connection: Connection = null private var ps: PreparedStatement = null override def open(parameters: Configuration): Unit = { //1:加载驱动 Class.forName("com.mysql.jdbc.Driver") //2:创建连接 connection = DriverManager.getConnection("jdbc:mysql://192.168.116.102/test", "root", "123456") //3:获得执行语句 val sql = "insert into user(id , username , password , name) values(?,?,?,?);" ps = connection.prepareStatement(sql) } override def invoke(value: (Int, String, String, String)): Unit = { try { //4.组装数据,执行插入操作 ps.setInt(1, value._1) ps.setString(2, value._2) ps.setString(3, value._3) ps.setString(4, value._4) ps.executeUpdate() } catch { case e: Exception => println(e.getMessage) } } //关闭连接操作 override def close(): Unit = { if (connection != null) { connection.close() } if (ps != null) { ps.close() } } }
4、Flink的Window操作
- 根据 时间 进行截取(time-driven-window),比如每1分钟统计一次或每10分钟统计一次。
- 根据 消息数量 进行截取(data-driven-window),比如每5个数据统计一次或每50个数据统计一次
4.1、时间窗口
import org.apache.flink.streaming.api.scala._ import org.apache.flink.streaming.api.windowing.time.Time /** * 时间窗口 * 1)翻滚窗口-无重叠数据 * 2)滑动窗口-有重叠数据 * 小结 * 1). 如果窗口计算时间 > 窗口时间,会出现数据丢失 * 2). 如果窗口计算时间 < 窗口时间,会出现数据重复计算 * 3). 如果窗口计算时间 = 窗口时间,数据不会被重复计算 */ object StreamWindowTumblingTime { /** * @param sen 哪个红绿灯 * @param cardNum 多少辆车 */ case class WordCountCart(sen: Int, cardNum: Int) def main(args: Array[String]): Unit = { //创建运行环境 val senv = StreamExecutionEnvironment.getExecutionEnvironment //定义数据流来源 val textStream = senv.socketTextStream("192.168.116.90",9999) //转换数据格式,text->CarWc val data = textStream.map( line =>{ val array = line.split(",") WordCountCart(array(0).toInt,array(1).toInt) }) val keyByData = data.keyBy(line => line.sen) //无重叠数据,所以只需要给一个参数即可,每10秒钟统计一下各个路口通过红绿灯汽车的数量 //val result = keyByData.timeWindow(Time.seconds(10)).sum(1) //每2秒钟统计一次,在这过去的10秒钟内,各个路口通过红绿灯汽车的数量 val result = keyByData.timeWindow(Time.seconds(10), Time.seconds(2)).sum(1) //显示统计结果 result.print() //触发流计算 senv.execute() } }
4.2、Count-Window
import org.apache.flink.streaming.api.scala._ /** * 数据个数统计的窗口 * */ object StreamWindowTumblingCount { /** * @param sen 哪个红绿灯 * @param cardNum 多少辆车 */ case class WordCountCart(sen: Int, cardNum: Int) def main(args: Array[String]): Unit = { //创建运行环境 val senv = StreamExecutionEnvironment.getExecutionEnvironment //定义数据流来源 val textStream = senv.socketTextStream("192.168.116.90",9999) //转换数据格式,text->CountCart val data = textStream.map( line =>{ val array = line.split(",") WordCountCart(array(0).toInt,array(1).toInt) }) val keyByData = data.keyBy(line => line.sen) //相同的key出现三次才做一次sum聚合 //val result = keyByData.countWindow(3).sum(1) //相同的key出现三次时,统计最近的5次消息做sum聚合 val result = keyByData.countWindow(5,3).sum(1) //显示统计结果 result.print() //触发流计算 senv.execute() } }
4.3、Window apply
import org.apache.flink.streaming.api.scala._ import org.apache.flink.streaming.api.scala.function.WindowFunction import org.apache.flink.streaming.api.windowing.time.Time import org.apache.flink.streaming.api.windowing.windows.TimeWindow import org.apache.flink.util.Collector /** * apply方法可以进行一些自定义处理,通过匿名内部类的方法来实现。当有一些复杂计算时使用 */ object StreamWindowApply { def main(args: Array[String]): Unit = { //获取流处理运行环境 val senv = StreamExecutionEnvironment.getExecutionEnvironment // 构建socket流数据源,并指定IP地址和端口号 val socketDataStream = senv.socketTextStream("192.168.116.90",9999) //对接收到的数据转换成单词元组 val wordCountDataStream = socketDataStream.flatMap{ text => text.split(" ").map((_ -> 1)) } //使用`keyBy`进行分流(分组) val groupedDataStream = wordCountDataStream.keyBy(_._1) //使用`timeWinodw`指定窗口的长度(每3秒计算一次) val windowedDataStream = groupedDataStream.timeWindow(Time.seconds(3)) //实现一个WindowFunction匿名内部类 val resultDataStream = windowedDataStream.apply(new WindowFunction[(String,Int),(String,Int),String,TimeWindow] { //在apply方法中实现聚合计算 override def apply(key: String, window: TimeWindow, input: Iterable[(String, Int)], out: Collector[(String, Int)]): Unit = { val resultWordCount = input.reduce{ (wc1,wc2) => (wc1._1,wc1._2+wc2._2) } //使用Collector.collect收集数据 out.collect(resultWordCount) } }) //打印输出 resultDataStream.print() // 启动执行 senv.execute() } }
5、Flink的水印机制
5.1、flink流处理时间方式
- EventTime[事件时间]
- IngestionTime[摄入时间]
- ProcessingTime[处理时间]
// 设置为按照事件时间来进行计算 env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime) // 设置为按照处理时间来进行计算 env.setStreamTimeCharacteristic(TimeCharacteristic.ProcessingTime)
5.2、使用水印解决网络延迟问题
- 水印并不会影响原有Eventtime
- 当数据流添加水印后,会按照水印时间来触发窗口计算
- 一般会设置水印时间,比Eventtime小几秒钟
- 当接收到的 水印时间 >= 窗口的endTime ,则触发计算
import java.util.{Date, UUID} import java.util.concurrent.TimeUnit import org.apache.commons.lang.time.FastDateFormat import org.apache.flink.streaming.api.TimeCharacteristic import org.apache.flink.streaming.api.functions.AssignerWithPeriodicWatermarks import org.apache.flink.streaming.api.functions.source.{RichSourceFunction, SourceFunction} import org.apache.flink.streaming.api.scala._ import org.apache.flink.streaming.api.watermark.Watermark import org.apache.flink.streaming.api.windowing.time.Time import scala.util.Random /** * 水印(watermark)就是一个 时间戳 ,Flink可以给数据流添加水印,可以理解为:收到一条消息后,额外给这个消 * 息添加了一个时间字段,这就是添加水印。 * 水印并不会影响原有Eventtime * 当数据流添加水印后,会按照水印时间来触发窗口计算 * 一般会设置水印时间,比Eventtime小几秒钟 * 当接收到的 水印时间 >= 窗口的endTime ,则触发计算 */ object StreamWaterMark { // 3. 创建一个订单样例类`Order`,包含四个字段(订单ID、用户ID、订单金额、时间戳) case class Order(orderId: String, userId: Int, money: Long, timestamp: Long) def main(args: Array[String]): Unit = { // 1. 创建流处理运行环境 val senv = StreamExecutionEnvironment.getExecutionEnvironment // 2. 设置处理时间为`EventTime` senv.setStreamTimeCharacteristic(TimeCharacteristic.EventTime) // 4. 创建一个自定义数据源 val orderDataStream = senv.addSource(new RichSourceFunction[Order] { var isRunning = true override def run(sourceContext: SourceFunction.SourceContext[Order]): Unit = { while(isRunning){ // - 随机生成订单ID(UUID) // - 随机生成用户ID(0-2) // - 随机生成订单金额(0-100) // - 时间戳为当前系统时间 // - 每隔1秒生成一个订单 val order = Order(UUID.randomUUID().toString,Random.nextInt(3),Random.nextInt(101),new Date().getTime) //直接设置水印时间 //sourceContext.emitWatermark(new Watermark(order.timestamp-2)) sourceContext.collect(order) TimeUnit.SECONDS.sleep(1) } //设置默认水印 //sourceContext.emitWatermark(new Watermark(Long.MaxValue)) } override def cancel(): Unit = {isRunning = false} }) // 5. 添加水印 val watermarkDataStream = orderDataStream.assignTimestampsAndWatermarks(new AssignerWithPeriodicWatermarks[Order] { //-允许延迟2秒 //在获取水印方法中,打印水印时间,当前事件事件和当前系统时间 var currentTimestamp = 0L val delayTime = 2000 override def getCurrentWatermark: Watermark = { val watermark = new Watermark(currentTimestamp-delayTime) val dateFormat = FastDateFormat.getInstance("HH:mm:ss") println(s"当前水印时间:${dateFormat.format(watermark.getTimestamp)},当前事件时间:${dateFormat.format(currentTimestamp)}," + s"当前系统时间:${dateFormat.format(System.currentTimeMillis())}") watermark } override def extractTimestamp(t: Order, l: Long): Long = { val timestamp = t.timestamp currentTimestamp = Math.max(currentTimestamp,timestamp) currentTimestamp } }) // 6. 按照用户进行分流 // 7. 设置5秒的时间窗口 // 8. 进行聚合计算 // 9. 打印结果数据 // 10. 启动执行流处理 watermarkDataStream.keyBy(_.userId).timeWindow(Time.seconds(5)).reduce{ (order1,order2) => Order(order2.orderId,order2.userId,order2.money+order1.money,0) }.print() senv.execute() } }
六、Flink的状态管理
----------待补充
七、Flink的容错机制
----------待补充
八、Flink SQL开发
----------待补充
